/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
В настоящее время активно развиваются и внедряются системы искусственного интеллекта. Собеседник всё чаще становится виртуальным, представляющим из себя мощную программу. Таковой является чат-бот. Сейчас такие программы-собеседники уже напоминают личных секретарей, в круг их обязанностей входят информирование о погоде, перевод денег, напоминание о важных событиях, запись на приём к врачу и многое другое.
В данной статье я расскажу, как можно создать такого небольшого чат-бота в Telegram. Он сможет говорить на общие темы: погода, досуг и т.д. В статье будет много ссылок на дополнительные материалы, они позволят более глубоко погрузиться в тему NLP и создания ботов в Telegram. Также в конце я оставлю предложения по усовершенствованию разработанного чат-бота.
Весь код написан на языке Python.
- Создание бота в Telegram
Для того, чтобы создать бота в Telegram необходимо написать боту по имени BotFather.
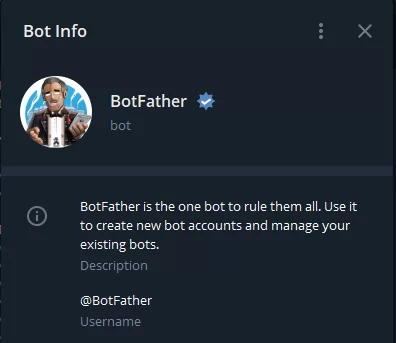
С помощью BotFather можно создавать новых ботов в Telegram и изменять настройки существующих. Например, добавить описание, установить аватарку для бота.
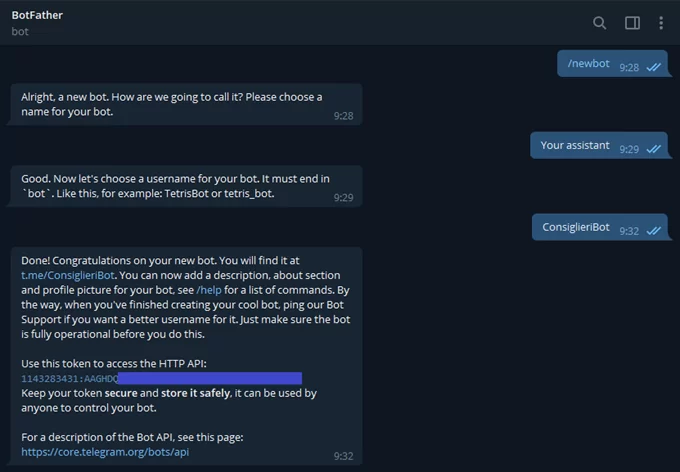
После создания чат-бота в BotFather вы получите уникальный токен. Токен нужен для идентификации вашего бота. Не сообщайте его никому.
2. Написание кода бота
Для создания чат-ботов в Telegram можете использовать библиотеки python-telegram-bot или pyTelegramBotAPI
from telegram import Update
from telegram.ext import Updater, CommandHandler
# Обработка команды start
def send_start(update: Update):
update.message.reply_text(“Hey, what’s up?”)
updater = Updater(“YOUR_BOT_TOKEN”)
# Добавление обработчика
updater.dispatcher.add_handler(CommandHandler(‘hello’, send_start))
# Запуск бота
updater.start_polling()
updater.idle()
Использование библиотекиpython-telegram-bot
import telebot
bot = telebot.TeleBot("YOUR_BOT_TOKEN")
# Обработка команды start
@bot.message_handler(commands=['start'])
def send_start(message):
bot.reply_to(message, "Hey, what’s up?")
# Запуск бота
bot.infinity_polling()
Использование библиотеки pyTelegramBotAPI
Принципиально эти библиотеки ничем друг от друга не отличаются. Отличие связано с синтаксисом.
В данной статье я использовал библиотеку python-telegram-bot.
Если речь идёт о чат-боте для сотен людей, то лучше использовать библиотеку aiogram. В отличие от двух предыдущих библиотек aiogram поддерживает ассинхронность. Это позволит обрабатывать сообщения нескольких людей одновременно.
3. Создание искусственного интеллекта
NLP (Natural Language Processing) – тема объёмная, тема для ряда статей. В этой статье я расскажу, что использовал и оставлю ссылки на ресурсы с более подробным обзором данной темы.
a. Набор датасета
Датасет я составлял вручную. Структура датасета представлена ниже на изображении.
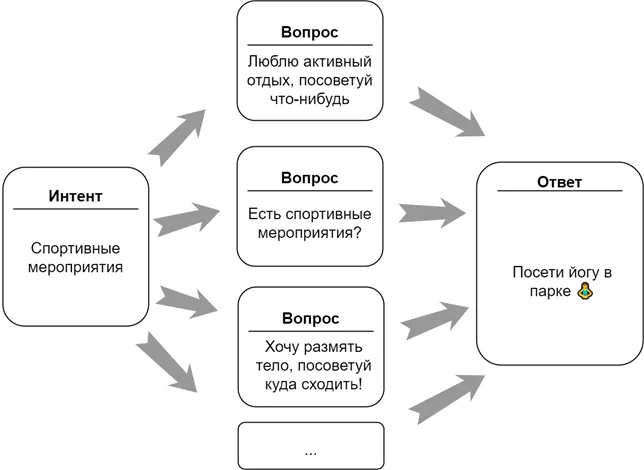
Интенты – намерения пользователей. Интент включает в себя примеры вопросов, которые задают пользователи. Например, интент Спортивные мероприятия содержит все вопросы (строго говоря, это могут быть и утверждения), связанные со спортивными мероприятиями. Также интент включает в себя ответы чат-бота. Интент может включать один или несколько ответов. Если ответов несколько, то ответ бота выбирается случайным образом.
В Python структура датасета следующая:
{‘интенты’: {‘1-й интент’: {‘примеры запросов’: [примеры], ‘ответы чат-бота’: [ответы]}, ‘2-й интент’: {‘примеры запросов’: [примеры], ‘ответы чат-бота’: [ответы], …}}
Если знаете, как это сделать проще или где можно найти готовые датасеты, пишите в комментариях.
b. Предобработка текста
Были использованы три метода: удаление символов пунктуации, приведение слов к нижнему регистру и лемматизация.
Для удаления символов пунктуации использовался модуль string.
import string
# Удаление символов пунктуации
def remove_punctuation(text):
translator = str.maketrans('', '', string.punctuation)
return text.translate(translator)
Лемматизация – это процесс приведения слова к нормальной (словарной) форме.
Лемматизация нужна для того, чтобы слова, имеющие одинаковое значение, но написанные в разной временной форме, не воспринимались ботом как совершенно разные слова и относились к одному интенту.
Библиотека pymystem3 — это морфологический анализатор русского текста от компании Яндекс. Он приводит слова к начальной форме и нижнему регистру.
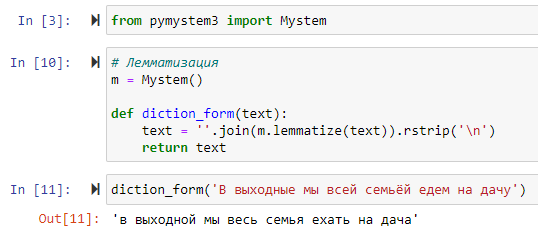
Ссылка на статью с рассмотрением различных способов предобработки текста.
c. Векторизация
В качестве векторизатора был использован TF-IDF векторизатор.
Его название — это сокращение от Term frequency-inverse document frequency (частота слова — обратная частота документа).
Частота слова (Term Frequency) — определяет, как часто выбранное слово появляется в документе (в данном случае, это запросы пользователей).
Обратная частота документа (Inverse Document Frequency) — снижает веса слов, которые часто встречаются в документах.
Код векторизатора:
from sklearn.feature_extraction.text import TfidVectorizer
vectorizer = TfidVectorizer(analyzer=’char_wb’, ngram_range=(2,3), max_df=0.8)
vector = vectorizer.fit_transform(text)
Параметры векторизатора:
- analyzer=’char_wb’ – создание n-грамм символов только из текста внутри границ слов;
- ngram_range=(2,3) – нижняя и верхняя границы диапазона значений для n-грамм;
- max_df=0.8 — игнорирование терминов, частота которых в запросе строго превышает заданный порог.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, stratify=y)
Данные делились на обучающую и тестовую выборки. Треть данных отводилась на тесты, остальные часть данных на обучение.
Параметр stratify задаёт использование стратификации по интентам, это позволяет повысить точность классификации для классов с неравным количеством примеров запросов в датасете.
d. Классификация
Для классификации был использован алгоритм LinearSVC. Метод опорных векторов хорошо показывает себя в многоклассовой классификации.
from sklearn.svm import LinearSVC
# Классификация
clf = LinearSVC()
clf.fit(X_train, y_train)
clf.predict(vector)[0]
Если ваша модель плохо обучена и часто ошибается в классификации, то можно дополнительно реализовать один из алгоритмов нечёткого поиска. Например, расстояние Левенштейна.
Также мой совет – добавлять заглушки в бота. Заглушки – это такие фразы как «Извините, не понял вас», «Перефразируйте, пожалуйста.».
Модель машинного обучения, имеющая по всем метрикам единицы, это утопия. К тому же язык – это динамическая система и ваш датасет не вечен. Его нужно будет изменять и дополнять. С заглушками пользователь не будет думать, что чат-бот завис или не работает, человек всегда получит ответ.
e. Запуск чат-бота
Можно запускать бота и тестировать его.
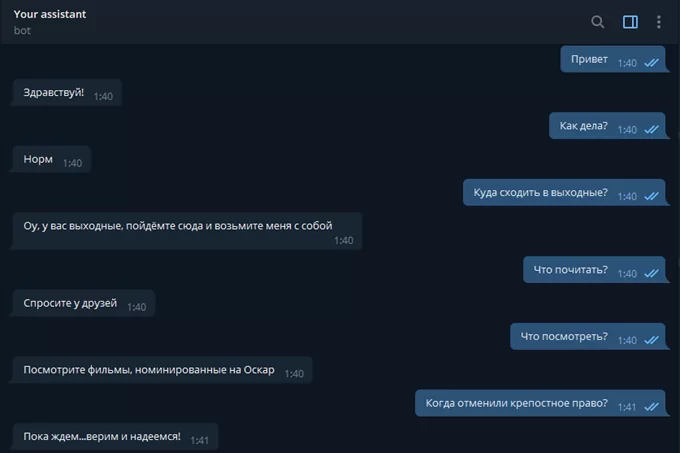
Небольшой чат-бот, который сможет поддержать разговор на общие темы, готов.
В дальнейшем, если захотите развивать этого бота и добавлять новый функционал, то можете попробовать следующее:
- Логирование
Логирование – это запись действий программы в отдельном файле. Например, запуск бота, обработка запроса пользователя. Логирование позволяет быстрее находить и исправлять баги в программе.
Библиотека: logging.
- Обработка голосовых сообщений
В общении мы используем не только текстовые, но и голосовые сообщения, поэтому возможность отвечать на голосовые сообщения будет классной фичёй для вашего бота.
Библиотека: SpeechPecognition.
- Выгрузка бота на сервер
Чтобы ваш бот отвечал круглосуточно необходимо его запустить на сервере. Для запуска небольшого личного бота отлично подойдёт облачная платформа PythonAnywhere. Бесплатного тарифа будет достаточно.
Это всё, что я хотел рассказать в данной статье. Надеюсь, вы не зря потратили время. Дерзайте и всё получится!