/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 4 мин.
Если вы- специалист по данным и в своей работе занимаетесь извлечением наилучшей информации из данных, но по какой-либо причине еще не готовы использовать dbt или подходы ELT, предлагаю обратить внимание на такой инструмент с открытым кодом, как библиотека Optimus, с помощью которой можно быстро подготавливать, обрабатывать, исследовать данные, используя Apache Spark и Python (PySpark).
В ряду Python-библиотек для машинного обучения, как, например, Numpy, Scikit-learn, Theano или TensorFlow, Optimus занимает свою нишу, т.к. основан на технологиях DataFrames: pandas (подходит для небольших по масштабу данных на локальном ПК), Dask (большие данные на локальном ПК или кластере Dask), cuDF (есть GPU и небольшие данные), Dask-cuDF (большие данные и кластер GPU), Spark (большие данные и кластер Spark) и Vaex (обработка больших данных на ПК с маленьким объемом памяти). Благодаря этому можно работать с данными, используя один и тот же код с помощью более подходящего для имеющейся в распоряжении инфраструктуры механизма.
Optimus можно применять для построения и создания ML (Machine Learning) моделей, о чем я и расскажу вкратце в виде двух примеров в данной статье.
Итак, для установки библиотеки выполним в окне командной строки:
pip install optimuspyspark
Необходимые требования: Apache Spark версии >= 2.3.1 (устанавливается вместе с пакетом)
Python версии >= 3.6
Несомненно, целью большинства рабочих процессов Data Science является создание ML-модели. Фреймворк Apache Spark располагает библиотекой под названием MLlib, в которой прописаны алгоритмы для машинного обучения. Установив Optimus и используя MLlib можно воспользоваться API Dataframe и его оптимизацией для создания ML pipelines.
Чтобы импортировать библиотеку MLlib выполним следующий код:
from pyspark.sql import Row, types
from pyspark.ml import feature, classification
from optimus import Optimus
from optimus.ml.models import ML
from optimus.ml.functions import *
op = Optimus()
ml = ML()
spark = op.spark
sc = op.sc
Рассмотри то, что предоставляет Optimus для Machine Learning.
Логистическая регрессия для DataFrame (текст).
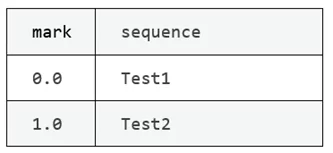
Для того, чтобы увидеть, как работает этот метод, создадим простой образец DataFrame из двух строк.
# Импортируем Optimus
import optimus as op
# Импортируем строки из pyspark
from pyspark.sql import Row
df = op.sc. \
parallelize([Row(sequence ='Test1', mark=0.),
Row(sequence ='Test2', mark=1.)]). \
toDF()
df.table()
Результат кода:
Далее давайте предскажем эти метки с помощью метода Optimus
ml.logistic_regression_text(df, input_col).
Следующий код вернет, во-первых DataFrame с прогнозами, а также столбцы с шагами, используемыми для построения конвейера, и затем ML-модель Spark, где третьим шагом (в pipeline) будет логистическая регрессия.
dfPredict, mlModel = op.ml.logistic_regression_text(df,"sequence") |
Получаем столбцы dfPredict (длинные имена – это uid для шагов в конвейере)
dfPredict.columns
['mark',
'sequence',
'Tokenizer_4df79504b43d7aca6c0b__output',
'CountVectorizer_421c9454cfd127d9deff__output',
'LogisticRegression_406a8cef8029cfbbfeda__rawPrediction',
'LogisticRegression_406a8cef8029cfbbfeda__probability',
'LogisticRegression_406a8cef8029cfbbfeda__prediction']
Теперь давайте посмотрим на результат прогноза, сравнив его с фактическими метками, выполним код:
dfPredict.cols.select([[0,6]).table()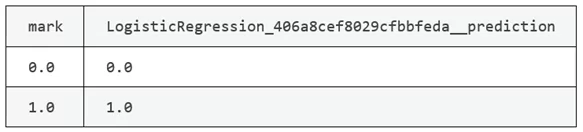
Созданная модель также отображается в переменной mlModel, ее можно сохранить и оценить.
Метод извлечения N-gram[1].
Этот метод Optimus (ml.n_gram(df, input_col, n=2) преобразует входной массив строк внутри Spark DataFrame в массив n-gram. Так как по умолчанию значение n равно 2, то этот метод будет создавать би-граммы.
Итак, для примера создадим DataFrame:
Импортируем Optimus
import optimus as op
# Импортируем строки из pyspark
from pyspark.sql import Row
df = op.sc. \
parallelize([['This is the best sentence ever'],
['This is however the worst sentence available']])\
.toDF(schema=types.StructType().add('sequence', types.StringType()))
# Применяем метод n-gram для массива строк
dfPredict, model = op.ml.n_gram(df, input_col="sequence", n=2)
Столбцы dfPredict:
dfPredict.columns
['sequence',
'Tokenizer_4a0eb7921c3a33b0bec5__output',
'StopWordsRemover_4c5b9a5473e194516f3f__output',
'CountVectorizer_41638674bb4c4a8d454c__output',
'NGram_4e1d89fc70917c522134__output',
'CountVectorizer_4513a7ba6ce22e617be7__output',
'VectorAssembler_42719455dc1bde0c2a24__output',
'features']
Теперь получим би-граммы для имеющихся в DataFrame предложений ‘This is the best sentence ever’ и ‘This is however the worst sentence available’:
dfModel.cols.select([[0,4]).table()
Как видно получены n-граммы одной строкой кода.
Задачи очистки, подготовки данных, запуска алгоритмов машинного обучения не должны быть головной болью, и это возможно с таким инструментом, как Optimus, использующим библиотеку для параллельных вычислений Dask и PySpark. Optimus работает как унифицированный API для таких задач. Его можно использовать для обработки малых и больших данных на локальном ПК или в удаленных кластерах с использованием CPU или GPU.
[1] N-gram — последовательность из n элементов. С семантической точки зрения, это может быть последовательность звуков, слогов, слов или букв.