/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Sharepoint – один из наиболее встречающихся инструментов для организации веб-порталов в больших организациях. Ключевым преимуществом системы является удобное прототипирование, создание списков с данными и т.д.
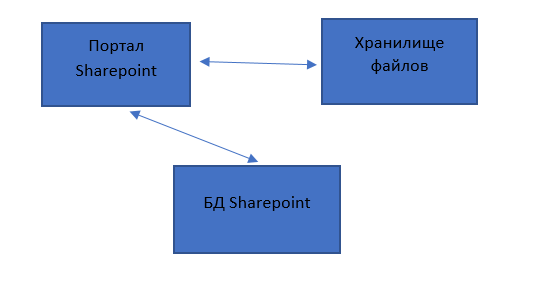
В рамках одной из систем в организации реализована такая схема – есть проект и по каждому проекту хранятся файлы в материалах Sharepoint.
Была поставлена задача – нужно выкачать файлы за весь период, а за 5 лет их накопилось очень много (примерно 122 тысячи файлов), и,соответственно, решать эту задачу руками – равноценно тому, чтобы остаться жить на работе на ближайшие десять лет.
Для начала приведем схему, как сейчас реализовано взаимодействие.
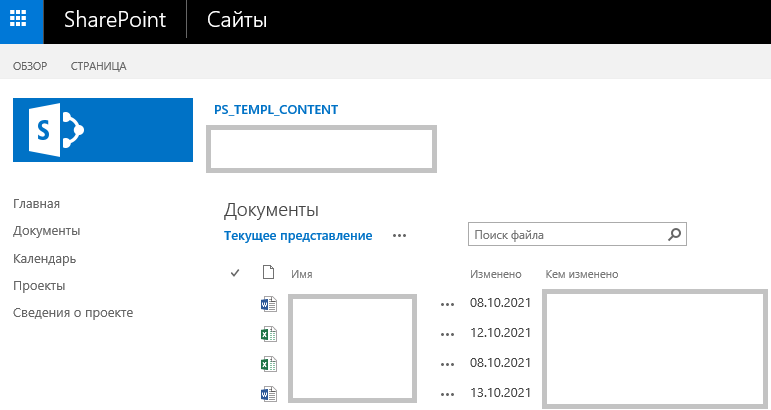
Ссылки на материалы обычно имеют такой вид:
Для начала из БД сервиса через SQL запрос сформируем ссылки на материалы для всего необходимого списка.
Как хранятся данные может сильно отличаться в зависимости от организации, в моем случае я просто сджойнил ИД документов с БД Sharepoint и на выходе получил необходимые ссылки.
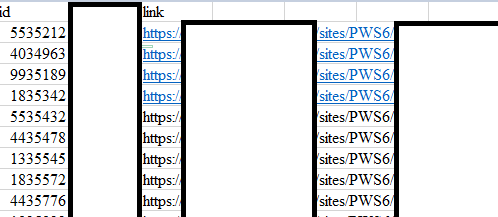
Итак, у нас есть csv файл (ссылки по понятным причинам пришлось скрыть), который хранит в себе все ссылки на необходимые нам материалы.
Возьмем python и для скачивания будем использовать библиотеку requests.
Первым делом авторизуемся по логину/паролю Windows. Для этого используем модуль авторизации HttpNtlmAuth из пакета requests_ntlm.
Чтобы получить список файлов – используем запрос к api, который вернет нам xml-документ с ссылками на материалы.
@staticmethod
def is_remote_host_available(host_link, username, password):
return requests.get(host_link + '/_api/files/', auth=HttpNtlmAuth(username, password), verify=False)

Полученный xml хранит в себе уже непосредственные ссылки на файлы, которые мы можем распарсить, а потом скачать.
Распарсим полученную XML для выделения ссылок на каждый файл по отдельности.
@staticmethod
def download_specified_files(response, username, password, output_path):
try:
doc = ET.fromstring(response.text)
except AttributeError:
return False
tree = ET.ElementTree(doc)
xml_to_parse = tree.findall('{http://www.w3.org/2005/Atom}entry')
# если пустая, пропускаем номер и даем False
if len(xml_to_parse) < 1:
return False
temp_links_list = SharepointRequest.__generate_download_links(xml_to_parse, output_path)
for file_name, file_link in temp_links_list.items():
status = False
status = SharepointRequest.download_files(file_link, file_name, username, password)
if status:
continue
else:
time.sleep(5)
staticmethod
def __generate_download_links(xml_from_request, output_path):
temp_links_list = {}
for entry in xml_from_request:
content = entry.find('{http://www.w3.org/2005/Atom}content')
properties = content.find('{http://schemas.microsoft.com/ado/2007/08/dataservices/metadata}properties')
url = properties.find('{http://schemas.microsoft.com/ado/2007/08/dataservices}Url')
if (url.text != ""):
# Получаем ссылку на файл из xml и вытаскиваем все нужное
download_link = url.text
download_file_name = ''.join([output_path,'/', url.text.split('/')[-1]])
temp_links_list[download_file_name] = download_link
return temp_links_list
После того, как сформируем список на скачивание, вызываем метод для разделения файла на чанки и скачиваем его.
Для визуализации прогресса, используем iter_content
def download_files(host_link, file_name, username, password):
with open(file_name, 'wb') as file_loading:
print(f"Downloading {file_name}")
response = requests.get(host_link, auth=HttpNtlmAuth(username, password), verify=False, stream=True)
total_file_length = response.headers.get('Content-Length')
# Берем длину файла
if total_file_length is None:
file_loading.write(response.content)
else:
dl = 0
total_file_length = int(total_file_length)
for data in response.iter_content(chunk_size=8192):
dl += len(data)
file_loading.write(data)
done = int(50 * dl / total_file_length)
sys.stdout.write("\r[%s%s]" % ('=' * done, ' ' * (50 - done)))
sys.stdout.flush()
if dl == total_file_length:
return True
Файлы по умолчанию мы сохраняем в директорию, которую мы выбрали изначально.
На этом все. Данное решение позволило мне выкачать около 500 гб файлов за 2 дня. Используйте в работе!