/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Одной из самых распространенных задач машинного обучения является сегментация объектов на изображении. Это крайне важный этап, так как в последующем, сегментированные изображения используются для обучения классификации либо же для вывода уже готового изображения. Поэтому к сегментации стоит относиться трепетно, и сегодня мы рассмотрим один из примеров, как это делать. Пример будет построен на сегментации животных: собак и кошек – на изображении.
Начало работы выглядит одинаково для всех моделей машинного обучения: подключаем библиотеки, загружаем датасет, добавляем фото с помощью поворотов и кадрирования и обрабатываем каждое фото, так же стандартно. Такую последовательность вы можете найти в любой статье, связанной с машинным обучением, в частности, у моего коллеги выходила статья по классификации изображений (ссылка), где он подробно описал каждый шаг. Поэтому не будем останавливаться на этом и сразу перейдем к построению.
Листинг 1. Построим входной конвейер, применив расширение после пакетирования входных данных.
train_batches = (
train_images
.cache()
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE)
.repeat()
.map(Augment())
.prefetch(buffer_size=tf.data.AUTOTUNE))
test_batches = test_images.batch(BATCH_SIZE)
Листинг 2. Посмотрим на пример изображений и маски на них.
def display(display_list):
plt.figure(figsize=(15, 15))
title = ['Input Image', 'True Mask', 'Predicted Mask']
for i in range(len(display_list)):
plt.subplot(1, len(display_list), i+1)
plt.title(title[i])
plt.imshow(tf.keras.preprocessing.image.array_to_img(display_list[i]))
plt.axis('off')
plt.show()
for images, masks in train_batches.take(2):
sample_image, sample_mask = images[0], masks[0]
display([sample_image, sample_mask])

Далее нужно определить модель.
Модель используется здесь модифицированная U-Net. U-Net состоит из кодировщика (субдискретизатора) и декодера (повышающего дискретизатора). Чтобы изучить надежные функции и уменьшить количество обучаемых параметров, мы будем использовать предварительно обученную модель — MobileNetV2 — в качестве кодировщика. Для декодера, мы будем использовать повышающий дискретизацию блок, который уже реализован в Pix2pix учебник в TensorFlow Примеры Repo.
Как упоминалось выше, кодер будет предварительно обученная модель MobileNetV2, которая готова к использованию в tf.keras.applications. Кодировщик состоит из определенных выходных данных промежуточных слоев модели. Учтите, что кодировщик не будет обучаться в процессе обучения.
Листинг 3. Определяем модель.
base_model = tf.keras.applications.MobileNetV2(input_shape=[128, 128, 3], include_top=False)
# Используем активации этих слоев
layer_names = [
‘block_1_expand_relu’, # 64×64
‘block_3_expand_relu’, # 32×32
‘block_6_expand_relu’, # 16×16
‘block_13_expand_relu’, # 8×8
‘block_16_project’, # 4×4
]
base_model_outputs = [base_model.get_layer(name).output for name in layer_names]
# Создадим модель извлечения признаков
down_stack = tf.keras.Model(inputs=base_model.input, outputs=base_model_outputs)
down_stack.trainable = False
Декодер / повышающий дискретизатор — это просто серия блоков повышающей дискретизации, реализованная в примерах TensorFlow.
up_stack = [
pix2pix.upsample(512, 3), # 4x4 -> 8x8
pix2pix.upsample(256, 3), # 8x8 -> 16x16
pix2pix.upsample(128, 3), # 16x16 -> 32x32
pix2pix.upsample(64, 3), # 32x32 -> 64x64
]
def unet_model(output_channels:int):
inputs = tf.keras.layers.Input(shape=[128, 128, 3])
# Даунсэмплинг по модели
skips = down_stack(inputs)
x = skips[-1]
skips = reversed(skips[:-1])
# Повышение дискретизации и установление пропуска соединений
for up, skip in zip(up_stack, skips):
x = up(x)
concat = tf.keras.layers.Concatenate()
x = concat([x, skip])
# Это последний слой модели
last = tf.keras.layers.Conv2DTranspose(
filters=output_channels, kernel_size=3, strides=2,
padding='same') #64x64 -> 128x128
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
Следует отметить, что количество фильтров на последнем слое устанавливается на число output_channels. Это будет один выходной канал на класс.
Далее обучаем модель.
Теперь осталось только скомпилировать и обучить модель.
Поскольку это мультиклассицирует проблему определения классификации CetegforicalCrossentropy с from_logits=True, которая является стандартной функцией потерь. Используем losses.SparseCategoricalCrossentropy(from_logits=True), так как метки являются скалярными целыми вместо vecrtors партитур for баллов для каждого класса for каждого пикселя.
Листинг 4. При выполнении вывода метка, присвоенная пикселю, — это канал с наибольшим значением. Это то, что делает функция create_mask.
OUTPUT_CLASSES = 3
model = unet_model(output_channels=OUTPUT_CLASSES)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Листинг 5. Обратный вызов, определенный ниже, используется для наблюдения за тем, как модель улучшается во время обучения.
class DisplayCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
clear_output(wait=True)
show_predictions()
print ('\nSample Prediction after epoch {}\n'.format(epoch+1))
EPOCHS = 20
VAL_SUBSPLITS = 5
VALIDATION_STEPS = info.splits['test'].num_examples//BATCH_SIZE//VAL_SUBSPLITS
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
validation_steps=VALIDATION_STEPS,
validation_data=test_batches,
callbacks=[DisplayCallback()])

loss = model_history.history['loss']
val_loss = model_history.history['val_loss']
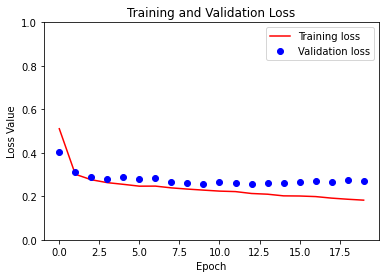
plt.figure()
plt.plot(model_history.epoch, loss, 'r', label='Training loss')
plt.plot(model_history.epoch, val_loss, 'bo', label='Validation loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss Value')
plt.ylim([0, 1])
plt.legend()
plt.show()
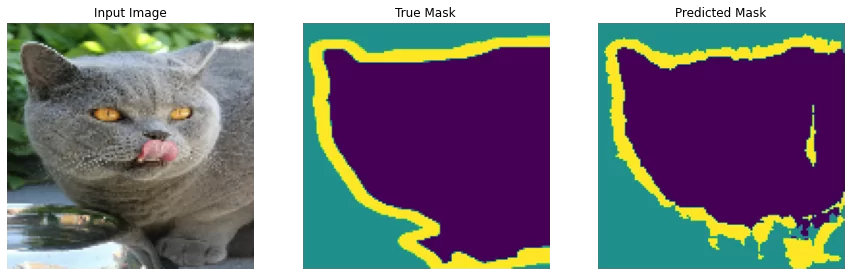
Делаем предсказания
Теперь сделаем несколько прогнозов. В целях экономии времени количество эпох оставлено небольшим, но вы можете установить его больше, чтобы получить более точные результаты.
show_predictions(test_batches, 3)

Вывод: здесь мы рассмотрели методы сегментации объектов на изображении. Это будет полезно как при участии в различных конкурсах, направленных на машинное обучение, так и в повседневной работе. Например, когда на фотографиях вам надо найти заданные объекты: документ, запрещенный прибор, средства пожарной безопасности и многое другое. В целом, возможности безграничны, все упирается в достаточно большой и качественный датасет. Ведь минимум 50% успеха работы нейросети будет зависеть от данных, на которых она обучается. Желаю успехов в будущих проектах.