/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 9 мин.
Многие встречали сайты, на которых данные подгружаются при прокрутке страницы вниз. Проблема в том, что в большинстве случаях нет представления об объеме скрытых данных, поскольку «бесконечный скролл» создает иллюзию отсутствия границ у контента, пользователю остается лишь продолжать листать страницу вниз, надеясь, что конец где-то существует, поэтому использовать тот же Selenium для парсинга таких страниц — это не лучшая идея. В случае большого объема скрытых данных использование Selenium может привести к зависанию страницы.
Обойти бесконечную прокрутку возможно. Я рассмотрю один из вариантов — библиотека Scrapy.
Предполагается, что читатель знаком с основами работы библиотеки scrapy.
Подготовка
1) Установка библиотек.
pip install scrapy
pip install urllib
2) Создание проекта scrapy. Команда для терминала:
scrapy startproject vc3) Редактирование файла settings.py.
Поддержка Юникода:
FEED_EXPORT_ENCODING = 'utf-8'Данные для экспорта результатов парсинга в файл формата json:
FEED_FORMAT = 'json'
FEED_URI ='result.json'Scrapy хорош тем, что в него уже встроена асинхронность, то есть возможность сбора и обработки данных в нескольких потоках параллельно. Соответственно, время сбора данных существенно сокращается, однако именно по этой же причине следует ограничить число одновременных запросов к сайту.
CONCURRENT_REQUESTS = 32Проверяем наличие переменной USER_AGENT. Например, так:
USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36'В процессе написания кода нам важно отслеживать работоспособность скрипта, поэтому следует включить логи. Уровня «debug» достаточно.
LOG_ENABLED = True
LOG_LEVEL = "DEBUG"
Для выключения логов достаточно изменить параметр LOG_ENABLED на False.
Куки включаем:
COOKIES_ENABLED = TrueПроверяем наличие переменной ITEM_PIPELINES:
ITEM_PIPELINES = {
'vc.pipelines.VcPipeline': 300,
}
Scrapy не будет собирать данные на страницах, которые не разрешено парсить в файле robots.txt. Чтобы Scrapy собирал нужные нам данные, изменим значение на False. Если вы уверены, что у сайта нет этого файла, то ROBOTSTXT_OBEY = True.
ROBOTSTXT_OBEY = FalseВсе остальные параметры нам не понадобится. В случае необходимости, подробнее о параметрах вы можете почитать в документации библиотеки.
4) Создание паука в директории spiders.
scrapy genspider vcru vc.ru5) Cоздание запускающего файла runner.py в директории, где лежит файл settings.py:
from scrapy.crawler import CrawlerProcess
from scrapy.settings import Settings
from vc import settings
from vc.spiders.vcru import VcSpider
if __name__ == '__main__':
crawler_settings = Settings()
crawler_settings.setmodule(settings)
process = CrawlerProcess(settings=crawler_settings)
process.crawl(VcSpider)
process.start()
В результате выполнения всех действий ожидаем получить следующую файловую структуру:
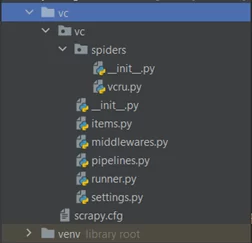
Анализируем
Прежде чем переходить к коду, проанализируем поведение сайта при прокрутке вниз.
Запускаем инструменты разработчика. Находим во вкладке «элементы» блоки с информацией по статьям. При прокрутке страницы сайта вниз, видим, как добавляются новые блоки. Открываем один из них для проверки:
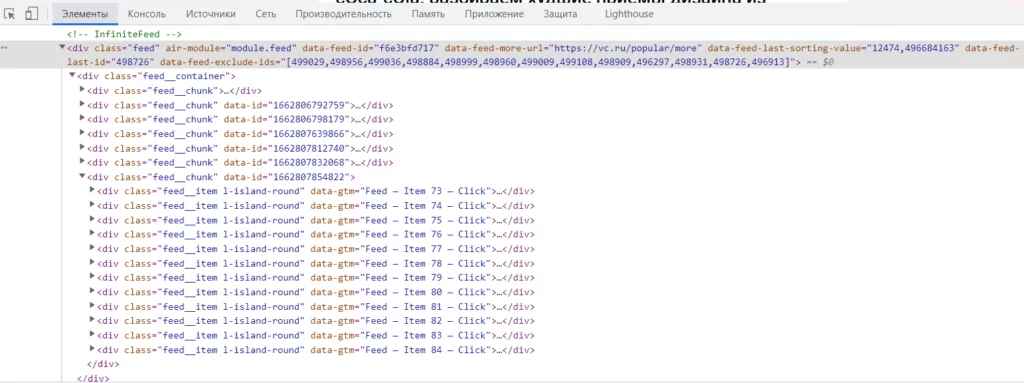

Запоминаем, что в одном блоке содержится информация по 12 статьям. Переходим во вкладку «Сеть» инструментов разработчика. Включаем XHR. А теперь прокручиваем страницу вниз. В списке появились новые записи запросов. Открываем интересующий нас запрос, чтобы увидеть в нем подробную информацию.
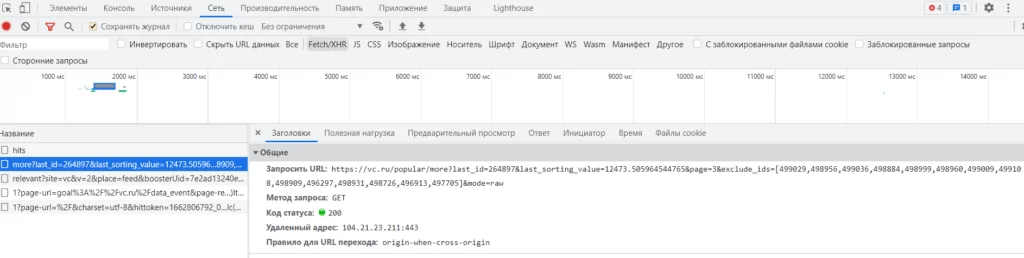
Мы видим GET-запрос, который содержит некоторые значения. Давайте посмотрим другую вкладку.

Видим, что в ответ на GET-запрос приходит json, в котором есть несколько ключей, в том числе ключ items_html – в нем содержится информация, которая подгружается при прокрутке вниз (именно этот блок мы видели на странице «элементы»).
Осталось понять, как формируются запросы. Выберем несколько запросов из списка слева и сравним, чем они отличаются.
| https://vc.ru/popular/more?last_id=264897&last_sorting_value=12473.505964544765&page=3& exclude_ids=[499029,498956,499036,498884,498999,498960,499009,499108,498909,496297,498931,498726,496913,497705]&mode=raw |
| https://vc.ru/popular/more?last_id=498082&last_sorting_value=12472.970735722707&page=4& exclude_ids=[499029,498956,499036,498884,498999,498960,499009,499108,498909,496297,498931,498726,496913,497705]&mode=raw |
| https://vc.ru/popular/more?last_id=498045&last_sorting_value=12470.745738032672&page=7& exclude_ids=[499029,498956,499036,498884,498999,498960,499009,499108,498909,496297,498931,498726,496913,497705]&mode=raw |
Отметим, что начало запросов «https://vc.ru/popular/more?» не изменяется. Меняются значенияlast_id, last_sorting_valueи page. Давайте разбираться, где взять все параметры. С параметром page– всё понятно, с каждым новым запросом значение увеличивается на единицу. Вспоминаем, что вместе с запросом возвращается словарь json, где содержатся last_id и last_sorting_value для последующих запросов, но мы до сих пор не знаем, где взять эти параметры для самого первого запроса. Возвращаемся на вкладку «Элементы» в инструментах разработчика. Присматриваемся и видим нужные нам параметры прямо внутри HTML-кода.

Отлично. Теперь нам известны все необходимые данные. Теперь перейдем в код.
Кодируем
В результате работы scrapy мы ожидаем получить json файл с собранной информацией со всех статей со страницы сайта vc.ru — https://vc.ru/popular. Мы будем собирать наименование, дату публикации, количество просмотров и ссылку.
Заходим в созданного паука(vcru.py) и видим класс VcSpider, созданный scrapy:
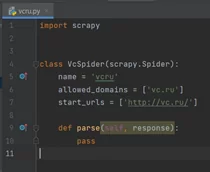
Импортируем нужные нам библиотеки:
import json
import scrapy
from scrapy.http import HtmlResponse
from urllib.parse import urlencode
from scrapy.selector import Selector
from scrapy.loader import ItemLoader
from vc.items import VcItem
Прописываем метод, который ищет все указанные параметры на страницах статей, а после передает найденные данные на дальнейшую обработку в файл pipelines.py.
def parse_ads(self, response):
loader = ItemLoader(item=VcItem(), response=response)
loader.add_xpath('name', "//h1//text()")
loader.add_xpath('date', "//time[@class='time']/@title")
loader.add_xpath('views', "//div[@class='views']/@data-value")
loader.add_value('url', response.url)
yield loader.load_item()
Сразу же заходим в файл items.py и инициализируем все названные параметры:
import scrapy
from itemloaders.processors import TakeFirst
class VcItem(scrapy.Item):
name = scrapy.Field(output_processor=TakeFirst())
date = scrapy.Field(output_processor=TakeFirst())
views = scrapy.Field(output_processor=TakeFirst())
url = scrapy.Field(output_processor=TakeFirst())
Возвращаемся вvcru.py. Добавляем переменные классу VcSpider.
name = 'vcru'
allowed_domains = ['vc.ru']
start_urls = ['https://vc.ru/popular']
main_url = 'https://vc.ru/popular/more?'
page = 2
Переменные name и allowed_domains – переменные, созданные самим scrapy. Их изменять не надо.start_urls – переменная, в которой лежит список начальных ссылок, с которых будет начинаться сбор данных. Количество ссылок может быть любым. Меняем start_urls на [‘https://vc.ru/popular’] – это та страница, на которой будет происходить поиск. main_url – неизменяемая составляющая всех GET-запросов.page – переменная, в которой хранится номер страницы, отсчет которой будет начинаться с 2, т.к. для первой страницы нам переменные не нужны.
Прописываем метод parse:
def parse(self, response: HtmlResponse):
links = response.xpath("//a[@class='content-link']")
for link in links:
yield response.follow(link, callback=self.parse_ads)
last_id, last_sorting_value, exclude_ids = self.get_more_page(response)
more = self.det_dict_more_page(last_id, last_sorting_value, self.page, exclude_ids)
if more['last_sorting_value'] is not None:
next_page = f'{self.main_url}{urlencode(more)}'
yield response.follow(next_page, callback=self.get_next_page)
Метод parse условно разделен на две логические части: в первой — собираются данные первой страницы, во второй – формируется запрос для открытия следующих 12 статей.
Сначала собираются ссылки на видимые статьи. Далее в цикле мы переходим по каждой ссылке и вызываем метод parse_ads для сбора данных по ним.
Для формирования первого запроса следует собрать значения параметров из html-кода и сформировать словарь, в котором будут собраны все параметры и их значения. За это отвечают методы get_more_page и det_dict_more_page. Первый – собирает информацию из html, второй – возвращает словарь с собранными значениями.
def get_more_page(self, response):
try:
last_sorting_value = response.xpath("//div[@class='feed']/@data-feed-last-sorting-value").extract_first().replace(',', '.')
except:
last_sorting_value = None
last_id = response.xpath("//div[@class='feed']/@data-feed-last-id").extract_first()
exclude_ids = response.xpath("//div[@class='feed']/@data-feed-exclude-ids").extract_first()
if exclude_ids is None:
exclude_ids = ''
return last_id, last_sorting_value, exclude_ids
def det_dict_more_page(self, last_id, last_sorting_value, page, exclude_ids):
more = {
'last_id': str(last_id),
'last_sorting_value': str(last_sorting_value),
'page': page,
'exclude_ids': exclude_ids,
'mode': 'raw'
}
return more
Как только данные собраны, проверяется значение ‘last_sorting_value’ – он указывает на возможность открыть больше информации при прокрутке вниз. Соответственно, если этот показатель не равен None, мы формируем ссылку и переходим по ней, вызывая метод get_next_page. Для формирования ссылки из полученных данных словаря, на которую осуществляется запрос, используется метод urlencode из библиотеки urllib. Запись f'{self.main_url}{urlencode(more)}’ равна следующей:
f"{self.main_url}last_id={more['last_id']}&last_sorting_value={more['last_sorting_value']}&page={more['page']}&exclude_ids={more['exclude_ids']}&mode={more['mode']}"Очевидно, первая запись лаконичнее.
Итак, мы собрали данные с первой страницы и сформировали первый запрос, который откроет нам следующие 12 статей.
Рассмотрим последний метод get_next_page, в котором получим все оставшиеся данные.
def get_next_page(self, response: HtmlResponse):
js_file = json.loads(response.text)
response2 = Selector(text=js_file['data']['items_html'])
links = response2.xpath("//a[@class='content-link']")
for link in links:
yield response.follow(link, callback=self.parse_ads)
self.page += 1
exclude_ids = self.get_more_page(response)[2]
if js_file['data']['last_sorting_value'] is not None:
more = self.det_dict_more_page(js_file['data']['last_id'], js_file['data']['last_sorting_value'], self.page, exclude_ids)
next_page = f'{self.main_url}{urlencode(more)}'
yield response.follow(next_page, callback=self.get_next_page)
Как и в методе parse, метод get_next_page условно разделен на две логические части. В первой – мы собираем данные с новых статей, во второй – отправляем запрос для открытия следующих скрытых данных.
Вспомним, что GET-запрос предполагает ответ в виде словаря json. Мы загружаем полученный json в переменную. В полученном словаре нас интересует значение в ‘items_html‘, который содержит html-код с новыми данными. Однако в json он хранится как строка, следовательно, нам из него следует сделать html-объект.
Чтобы собрать данные, мы сначала собираем все ссылки на статьи, а после в цикле собираем с каждой ссылки нужную нам информацию, вызывая метод parse_ads.
Но теперь для формирования следующего запроса, который откроет следующие скрытые данные, нужные параметры мы получаем не из html-кода, а из ответа json, кроме параметра exclude_ids. Соответственно, меняется и параметр page, увеличиваясь на единицу.
Важно! Переходя по запросу мы вновь вызываем этот же метод — get_next_page. Метод будет работать до тех пор, пока не соберется информация со всех статей. Осталось обработать полученные данные. Переходим в файл piplines.py.
class VcPipeline:
def process_item(self, item, spider):
item['name'] = item['name'].strip()
item['date'] = item['date'].strip()
item['views'] = item['views'].strip()
print(item)
return item
Чистим полученные данные от лишних пробелов, табуляций, переходов на новую строку. Как и планировалось, результат работы scrapy видим в файле result.json.

С помощью Scrapy за несколько минут (3 мин) была полностью собрана информация по 3701 статьям, которые расположены по ссылке https://vc.ru/popular.
Отлично. Цель выполнена.
Надеюсь, что описанный пример в сборе данных на сайтах с бесконечным скроллом поможет в реализации парсинга других сайтов с похожей механикой.