/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 8 мин.
В данной статье я опишу наш опыт создания датасета для обучения модели распознавания рукописного текста.
Предварительный анализ работ по этой теме показал, что в публичном доступе отсутствуют размеченные наборы данных на русском языке. Доступные данные либо описывают английский текст, либо не доступны для коммерческого использования. Нам не подходило такое условие, поэтому единственным вариантом стало создание собственных данных.
Общий принцип был заимствован у коллег из Казахстана – создание и заполнение табличных форм с двумя колонками на странице – печатной и рукописной, а затем разбивка скана либо фотографии страницы на мини-боксы с текстом. Мы начали с выбора текстов. Чтобы модель показывала хорошие результаты на инференсе, она должна иметь высокую обобщающую способность. Для этого она должна «увидеть» в процессе обучения как множество образцов почерка, так и разнообразие текстов. Мы взяли текст из нескольких источников, в числе которых бульварный роман, газетные публикации, научная работа и ряд других. Ниже приведена функция, которая формирует набор предложений из файла-источника, для чего выбирает по 3 слова в случайном месте текста. Ограничения на длину установлены, чтобы избежать слишком коротких или слишком длинных фраз.
def write_source(input_path, line_cnt, words_per_line=3):
"""
Формирует csv файл из простого текстового файла (файл-источник)
Данный файл необходим для формирования labels разметки
:param input_path: путь к txt файлу источника
:param line_cnt: ограничение на число выходных строк
:param words_per_line: количество слов в строке
:return: None
"""
with open(input_path, encoding='utf-8') as file:
text = file.read().lower()
text = re.sub(r'[^а-я ]+', ' ', text)
words = text.split()
words_total = len(words) - 3
while line_cnt > 0:
rand = np.random.randint(0, words_total)
if len(words[rand]) < 3 and len(words[rand + 1]) < 3:
continue
elif len(words[rand + 1]) < 3 and len(words[rand + 2]) < 3:
continue
elif len(words[rand]) < 3 and len(words[rand + 2]) < 3:
continue
concat = ' '.join(words[rand: rand + words_per_line])
if len(concat) > 20:
continue
line_cnt -= 1
yield concat
После этого csv-файлы импортируются в подготовленную Excel-форму, ключевым параметром в ней является верхний колонтитул, где прописан источник текста и номер страницы. Эта информация нужна для сопоставления с csv-файлами, сформированными на предыдущем шаге. Фрагмент формы выглядит следующим образом:

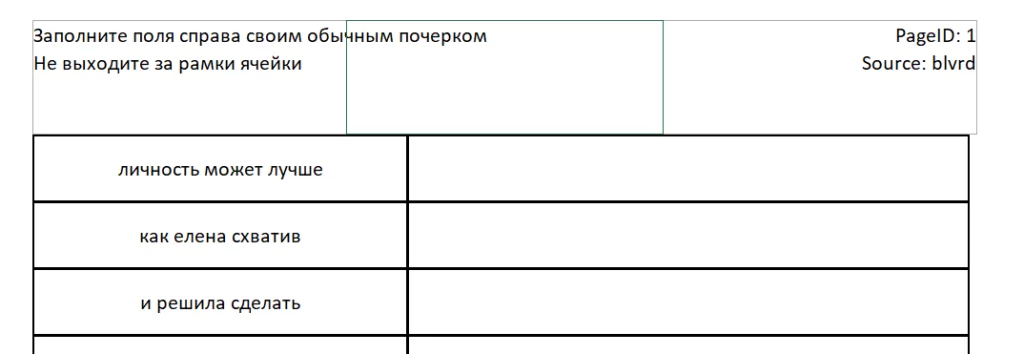
Следующий этап – заполнение форм. Распечатываем, раздаем коллегам, друзьям, знакомым, а также заполняем сами. У нас получилось более тысячи форм, что при 20 словосочетаниях на страницу позволило сформировать выбору из более чем двадцати тысяч примеров. Практика показала, что этого вполне достаточно для обучения модели.
После заполнения формы передаются на обработку. Для передачи в компьютер целесообразно использовать сканер, но мы просто фотографировали на телефон, этого оказалось достаточно. После этого изображение обрабатывается специальным ПО, которое формирует csv-файлы со строками формата – «текст — адрес картинки». Далее я кратко изложу принцип его работы.
В шапке каждой формы указан источник текста, из которого она сформирована – так программа понимает, из какого файла брать ground truth тексты – а также номер страницы – поскольку число примеров в форме фиксировано, мы можем легко вычислить offset – смещение относительно начала файла и выбрать нужный фрагмент текстов. Описанные манипуляции реализованы в виде следующих двух функций:
def read_source(path, page):
"""
Вспомогательная функция для чтения сформированного csv-файла (labels будущей разметки)
:param nrows: сколько строк считывать
:param offset: смещение (пропуск N строк)
:param path: путь к файлу
:return: список из словосочетаний
"""
nrows = 20
offset = (page - 1) * nrows # на каждой странице у нас по 20 словосочетаний
n = 0
with open(path, newline='') as file:
answers = []
for _ in range(offset): # skip first 10 rows
next(file)
for row in csv.reader(file):
answers.append(row[0]) # у нашего файла 1 столбец
n += 1
if n >= nrows:
break
return answers
def write_markup(labels_path, image_folder, labels_filename, page, gender):
"""
Принимает csv файл с labels и папку
Формирование файла разметки для обучения модели
:param gender: пол заполнившего лист
:param labels_path: путь к файлу с текстами строк
:param page: номер страницы (определяет смещение в csv-файле)
:param labels_filename: называние файла с текстами строк
:param image_folder: путь к папке с нарезанными изображениями
:return:
"""
markup_file_path = './markup/markup_' + labels_filename + '.csv'
labels = read_source(labels_path, page)
image_list = os.listdir(image_folder)
# половина ячеек таблицы - печатный текст (исходник)
# такие ячейки пропускаем, берем только нечетные
images = [image_folder + '/' + file for idx, file in enumerate(image_list) if idx % 2 == 1]
assert labels, "Список текстов пустой"
assert images, "Директория с нарезанными картинками пуста"
assert len(labels) == len(images), "Несовпадение длин массивов картинок и текстов"
# если файла не существует (пишем в него первый раз) - добавляем заголовок
if not os.path.exists(markup_file_path):
with open(markup_file_path, "w", newline='') as file:
writer = csv.writer(file)
writer.writerow(('label', 'image', 'gender'))
# после этого добавляем в файл обработанные строки
with open(markup_file_path, "a", newline='') as file:
writer = csv.writer(file)
for pair in zip(labels, images):
row = (pair[0], pair[1], gender)
writer.writerow(row)
Картинки нарезаются при помощи набора функций нашего Python-модуля table_slice. Работа с изображениями происходит при помощи библиотеки OpenCV – программа считывает контуры таблицы, фильтрует и затем сортирует их – нам не нужны слишком маленькие контуры, которые, вероятно, считаны ошибочно, а также слишком большие контуры, ограничивающие либо несколько ячеек таблицы, либо всю таблицу. Программный код этого модуля слишком большой для приведения в тексте статьи, с его основными идеями можно ознакомиться здесь. Для ускорения обработки реализован интерфейс командной строки. При запуске интерпретатора необходимо указать ряд аргументов, как обязательных, так и опциональных. Работа с аргументами происходит через модуль Argparse стандартной библиотеки. Полный программный код основного скрипта приведен ниже:
import os
import argparse
import cv2
import markup
import table_slice as ts
if __name__ == '__main__':
# интерпретатор должен быть запущен в корневой папке проекта!
parser = argparse.ArgumentParser()
parser.add_argument("labels", choices=['blvrd', 'discipl', 'econ', 'journ', 'koms', 'mathstat'],
help='Название файла с текстом. Не указывать расширение!')
parser.add_argument("images", help='Файл с отсканированным изображением')
parser.add_argument("page", type=int, help='Номер страницы')
parser.add_argument("gender", type=int, choices=[0,1], help="Пол: 1 - М, 0 - Ж")
parser.add_argument("--nocheck", action="store_true", help="Не запрашивать подтверждение записи")
args = parser.parse_args()
# аргументами должны быть только имена файлов, без путей
# path дает кривые слеши, поэтому использую конкатенацию строк
DST_IMG_FOLDER = './sliced/' + args.labels + '/' + args.images[:-4] # убираем расширение файла
# папка с готовыми (нарезанными) изображениями
SRC_IMG_FOLDER = './data/images' # папка с исходными (сканированными) изображениями
SRC_LBL_FOLDER = './data/labels' # папка с нарезанными текстами (csv)
LABELS_FILE_PATH = SRC_LBL_FOLDER + '/' + args.labels + '.csv' # путь к обрабатываемому файлу с ярлыками
IMAGE_FILE_PATH = SRC_IMG_FOLDER + '/' + args.labels + '/' + args.images # путь к фотке, которую нарезаем
img = cv2.imread(IMAGE_FILE_PATH, 0) # 0 для игнора цветовой палитры (читает ЧБ)
if img is None:
raise Exception("Не удалось прочитать исходный файл") # т.к. opencv не выдает ошибок чтения
# обработка изображений состоит из бинаризации
# получения границ таблицы и непосредственно нарезки
img_bin = ts.binarize(img)
img_vh, bitnot = ts.get_lines(img, img_bin)
cropped_images = ts.get_images(img_vh, bitnot, img_bin, w_min=10, h_min=25, h_max=5, debug=False)
if not os.path.exists(DST_IMG_FOLDER): # для каждой фотки - своя папка с нарезанными кусочками
os.makedirs(DST_IMG_FOLDER) # папка называется именем файла исходной фотки
for num, cropped_img in enumerate(cropped_images):
enhanced_img = markup.increase_contrast(cropped_img)
filename = DST_IMG_FOLDER + '/' + str(num).zfill(3) + '.jpg' # zfill делает названия 001, 002 и т.п.
did_write = cv2.imwrite(filename, enhanced_img)
# если не удалось записать файл, самостоятельно вызываем исключение
if not did_write:
raise Exception("Не удалось сохранить готовый файл")
# получить из csv тексты с соответствующей страницы
answers = markup.read_source(LABELS_FILE_PATH, args.page)
# контроль
ts.control(answers, cropped_images, args.nocheck)
# формирование и запись csv разметки (формат "текст" - "путь к картинке")
markup.write_markup(LABELS_FILE_PATH, DST_IMG_FOLDER, args.labels, args.page, args.gender)
print("Файл разметки сформирован")
Для обработки изображение помещается в папку, соответствующую названию текста-источника, после чего в командной строке из корневой папки python-проекта выполняется команда вида:
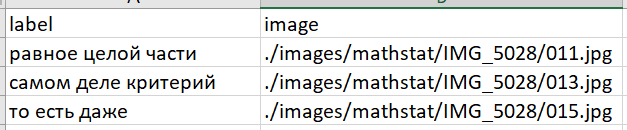
python src/main.py blvrd IMG_1234.jpg 140 1 --nocheckВ данном случае обрабатывается изображение IMG_1234, текст для которого был взят из источника blvrd, номер страницы формы – 140, автор – мужчина, а дополнительная проверка корректности форм выключена (программа не будет запрашивать подтверждение пользователя перед записью в итоговый файл). Программа автоматически контролирует корректность распознавания форм, правильность указания источника, соответствие количества нарезанных ячеек нормативному и другое. Обработка практически всегда происходит быстро и без ошибок. Практика показала, что основной причиной ошибок являются плохо пропечатанные контуры ячеек. Программа не даст записать не полностью считанную форму в файл. Результат работы представлен ниже.
Работа по разметке данных оказалась сложной и трудоемкой, однако это позволило нам сформировать уникальную выборку и в дальнейшем обучить ряд моделей, успешно распознающих написанный от руки русский текст.