/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 9 мин.
В этой статье мы расскажем, как, используя логи, понять, насколько ожидания от работы системы расходятся с реальностью и посчитаем метрики расхождений.
Если удобнее сразу перейти к коду, welcome на github.
В качестве примера для реализации был взят лог, предоставленный на соревновании Conformance Checking Challenge 2019. Внутри лога описана последовательность действий, как установить центральный венозный катетер с помощью ультразвука. Данные по эталонному процессу представлены в трех формах:
- Сеть Петри
- BPMN диаграмма
- Текст
Несмотря на то, что кейс не относится к бизнес-тематике, все три формы данных могут встретиться при разработке. В том числе, эталонный процесс может быть записан со слов эксперта в виде связного текста. Располагая любой формой данных, можно провести анализ, но в данной статье мы не будем рассматривать, как перевести текст в диаграмму, хотя так тоже можно сделать.
Коротко представим описание полей, которые будем использовать:
- RESOURCE: уникальный идентификатор студента
- ROUND: (PRE) — действие выполнено до проведения практических занятий и (POST) -действие выполнено после проведения практических занятий
- ACTIVITY: название действия, представленного в процессе
- START: время начала события
- END: время окончания события
Как сопоставить реальные логи и эталонную модель
На данный момент есть три популярных метода сравнений, мы подробно рассмотрим логику каждого из них, а в коде, можно познакомиться с реализацией на python, также представим наш собственный метод проверки соответствия, который родился по нуждам заказчика:
- Footprints conformance checking
- Token-based replay
- Alignment checking
- Custom check
Footprint conformance checking
Метод, который отражает связи между каждыми событиями и описывает, как последовательно друг за другом следуют все события в логах. При помощи не хитрых обозначений составляется две матрицы, которые описывают отношения событий:
- A -> B : А иногда следует за В
- A # B: А никогда не следует за В
- А || В: А и В следуют параллельно
Первая матрица отвечает за эталонный тип связей, то есть как события должны следовать друг за другом, а вторая матрица отражает реальные взаимосвязи в логах.
Метрика качества для оценки соответствия реальных логов с эталонной моделью рассчитывается:
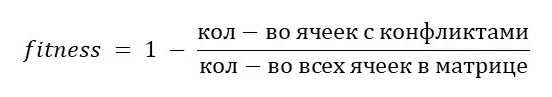
Для реального лога необходимо применить inductive miner, с его помощью мы получим отношения между событиями. Рассмотрим на примере действий студентов до проведения практических занятий:
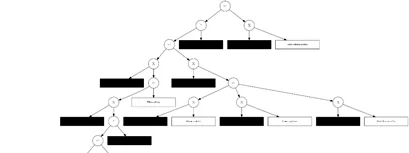
Первая матрица – матрица, в которой отражены верные взаимосвязи между событиями.

А так уже выглядит матрица с конфликтами после наложения реальных взаимосвязей из лога. Все конфликты подсвечиваются красными обозначениями.

# Посчитаем метрику для проверки качества соответствия реальных логов
from pm4py.algo.conformance.footprints import algorithm as footprints_conformance
conf_fp = footprints_conformance.apply(fp_trace_by_trace, fp_net)
dev_counter = 0
for trace in conf_fp:
for deviation in trace:
dev_counter+=len(deviation)
number_of_cells = len(set(pre['concept:name'])) ** 2
fintess_value = 1 - dev_counter/number_of_cells
Такой способ оценки дает очень поверхностное представление о том, насколько сильно реальный процесс отличается от эталонного и показывает общую метрику соответствия и не отражает, какие события, например, были пропущены и сколько раз. В то же время метод Footprints подходит для относительной оценки реальных логов. Так по итогам проверки соответствие действий студентов эталонным можно проверить на сколько в среднем после проведения практических занятий студенты стали больше (или меньше) следовать эталонному процессу.
Token-based replay
Второй способ дает более детальное представление о соответствии лога процессу, так как его логика основывается на использовании сети Петри с переходами состояний и опирается на подсчет missing, remaining, consumed, produced tokens.
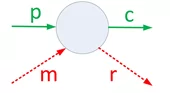
По картинке можно легко понять, какие токены к какому типу относятся:
- Produced – токены, которые были инициализированы
- Consumed – токены, которые совершили переход
- Missing – токены, которые совершили переход, но не в положенном месте
- Remaining – инициализированные токены, которые не сменили состояние
Метрика для оценки соответствия лога реальному процессу подсчитывается следующим образом:
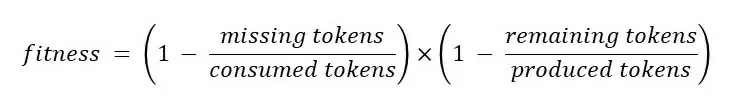
Аналогично предыдущему методу необходимо загрузить сеть Петри, чтобы отобразить эталонную последовательность. Затем при помощи функции посчитать процент fitness. В качестве параметров функции передаем реальный лог и эталонную сеть Петри.
def replay_fitness_calculation(real_log, etalon_petri_path):
net, initial_marking, final_marking pnml_importer.apply(etalon_petri_path)
replay_result = token_replay.apply(real_log, net, initial_marking, final_marking)
log_fitness = replay_fitness_factory.evaluate(replay_result, variant="token_replay")
return replay_result, log_fitness
Если развернуть, что находится, внутри replay_result, то можно посмотреть все параметры по каждому trace о его соответствии эталонной последовательности событий.
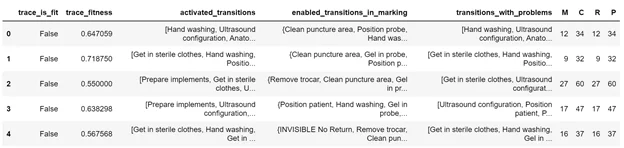
По каждому trace можно посмотреть подробный отчет о процентах соответствия, активированных и проблемных токенах, а также о количестве missing, consumed, remaining, produced.
Alignment conformance checking
Для всех логов, которые не используют все события из эталонной модели находятся максимально похожие, чтобы была возможность подсчета метрики соответствия. Максимальная похожесть trace на лог зависит от принятой функции потерь:
- Если событие пропущено только в реальном логе, а в модели событие присутствует, то штраф равен 1. Обозначается оно следующим образом {A:>>}
- Обратное событие предыдущему кейсу тоже штрафуется на единицу {>>:A}
- Если же событие заменено: {A:B}, то штраф равен бесконечности
Эти параметры дефолтные, но есть возможность их переопределить. На выходе получается список из пар (событие в модели / событие в логе).
У данного метода прорабатывается также визуализация, но на данный момент она пока находится в ветке develop на github.
Как получить схему эталонного процесса, если нет Petri Net
Как для лога в соревновании, так и для реальных бизнес-задач, чтобы создать эталонную диаграмму требуется эксперт, который знает и может описать все вариации нормы, которые могут встретиться в процессе.
Будем честны, сети Петри, по которым происходит моделирование replay процесса, сложны для восприятия и не менее сложны для проектирования. Намного удобнее для разработки и самого заказчика использовать нотацию BPMN.
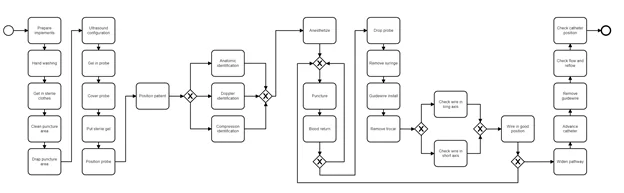
Для отрисовки моделей в формате BPMN существует множество онлайн редакторов с возможностью экспорта в .bpmn, но также есть корпоративные решения, самые популярные из них Camunda Modeler и Bizagi Modeler. Для личной разработки в них представлены также бесплатные тарифные планы.
Для работы с bpmn в pm4py необходимо установить дополнение стандартной библиотеки следующей командой:
pip install pm4pybpmnТеперь приступим к импорту модели в тетрадку:
# импорт модуля и загрузка диаграммы процесса
from pm4pybpmn.objects.bpmn.importer import bpmn20 as bpmn_importer
bpmn_graph = bpmn_importer.import_bpmn('\data\CCC19 - Model BPMN.bpmn')
Провести alignments check можно по нотации BPMN, но визуализация графа для BPMN тоже пока находится в beta-версии, но посмотреть на нее можно следующим образом:
from pm4pybpmn.visualization.bpmn import factory as bpmn_vis_factory
gviz = bpmn_vis_factory.apply_petri(net, im, fm, log=pre_log, variant="alignments")
bpmn_vis_factory.save(gviz, "alignments.png")
Также есть возможность сконвертировать в сеть Петри и провести ранее описанный анализ.
# конвертация bpmn в petri net
from pm4pybpmn.objects.conversion.bpmn_to_petri import factory as bpmn_to_petri
net, initial_marking, final_marking, elements_correspondence, inv_elements_correspondence, el_corr_keys_map = bpmn_to_petri.apply(bpmn_graph)
Как быть, если есть только excel
Наша интерпретация replay родилась по простой причине, что схема эталонного процесса и его вариации могли быть реализованы только в формате таблицы в excel и заказчик не нуждался в подсчете всех вышеизложенных метрик, нужно было четко понять, сколько раз были пропущены определенные этапы и визуализировать граф с отклонениями. Для реализации мы использовали DFG (Directly-Followed Graph).
Важно обратить внимание на принятые нами допущения:
- Если в логе не хватало событий до длины эталонного лога, недостающую разницу мы дополняли нулями
- Если событие присутствовало в логе, но не на своем месте, мы считали, что пропущено исходное событие
- Чтобы определить наиболее подходящий путь для trace, который имеет недостаточно элементов, мы искали близкие по количеству уникальных событий варианты эталонного процесса. Если определить, к какой вариации ближе trace, не удавалось, пропуски событий мы засчитывали обоим вариантам прохода
Эталонный процесс на данных примера представлял собой следующую последовательность:
action 1 → action 2→ action 3‖action 4 →action 5И сгенерировали мы следующие последовательности логов:
action 1 → action 2→ action 4
action 1 → action 2→ action 5
action 1 → action 2→ action 3→action 5
action 1 → action 2→ action 4 →action 5
action 1 → action 2→ action 3
Таким образом, на выходе мы получили граф, на котором цифры слева показывают количество пропусков, а справа число раз, сколько это событие должно было быть пройдено:
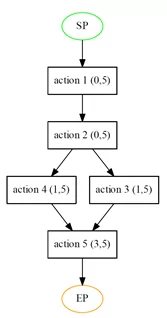
Итак:
- поскольку, некоторые логи пропускали внутри себя события, три раза action 5 не оказалось окончательным событие в цепочках логов, соответственно 3 пропуска из 5 логов
- лог action 1 ->
action 2 ->
 action 5 не дает понимание, какое из событий пропущено action 3 или action 4, поэтому по пропуску получили оба события
action 5 не дает понимание, какое из событий пропущено action 3 или action 4, поэтому по пропуску получили оба события - и поскольку action 1 и action 2 не были пропущены, в их пропусках стоят нули
Оценить, как сильно отличается ожидаемый лог процесса от реальных логов можно, это совсем не больно и можно сделать несколькими способами. Едва ли какой-то из способов покроет все нужды заказчика разом, но всегда можно придумать что-то свое.
| Плюсы | Минусы | |
| Footprints | Интуитивно легко понятен, прост и быстр в реализации, имеет наглядную визуализацию | Не учитывает пропуски событий, не принимает во внимание частоту появления событий |
| Token-Based replay | Принимает во внимание состояния токенов, ведет подсчет частоты | Не имеет пока реализованной визуализации, сложно интерпретируем |
| Alignment check | Принимает во внимание состояния токенов, ведет подсчет частоты и имеет гибкую систему штрафов для подбора | Не имеет пока реализованной визуализации, сложно интерпретируем, очень долго отрабатывает |
Полезные ссылки:
- Курс без программирования, чтобы понять суть PM
- Лекции по Conformance Check:
- Актуальная документация PM4PY