/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Одной из важнейших задач при разработке моделей машинного обучения является выбор гиперпараметров, обеспечивающих наилучшее качество моделей. Для решения этой задачи можно совместно использовать два инструмента библиотеки sklearn: пайплайны и поиск параметров по сетке, либо случайный поиск. Однако, для того, чтобы сравнить модели, построенные на разных компонентах, например, логистической регрессии и решающем дереве, придется создать разные пайплайны.
Рассмотрим задачу классификации текстов на примере известного набора данных «The 20 newsgroups dataset», состоящего приблизительно из 18 тысяч текстов по 20 темам. Загружаем набор данных и помещаем его в датафрейм.
from sklearn.datasets import fetch_20newsgroups
import pandas as pd
X, y = fetch_20newsgroups(subset='all', return_X_y=True)
df = pd.DataFrame({'text': X, 'label': y})
В целях демонстрации будем использовать только десятую часть исходного набора данных.
from sklearn.model_selection import train_test_split
df_train, _ = train_test_split(df, train_size=0.1, shuffle=True, stratify=df['label'])
Для начала построим базовую модель, состоящую из трех этапов: векторизации текстов на TfidfVectorizer, уменьшении пространства признаков на TruncatedSVD и классификации на логистической регрессии. Импортируем необходимые классы.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.decomposition import TruncatedSVD
from sklearn.pipeline import Pipeline
from sklearn.model_selection import GridSearchCV
Собираем пайплайн из трех компонентов.
pipe = Pipeline(steps=[('vectorizer', TfidfVectorizer(token_pattern='[a-z]{2,}')),
('reduction', TruncatedSVD()),
('classifier', LogisticRegression())
])
Визуализируем построенную цепочку средствами sklearn.
from sklearn import set_config
set_config(display='diagram')
pipe
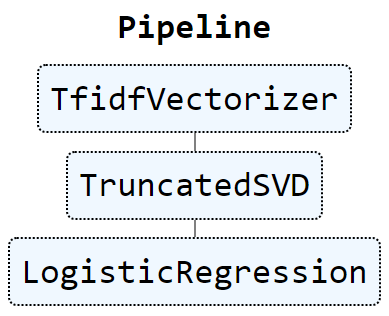
Создаем набор гиперпараметров и запускаем поиск по сетке, выбрав F1 в качестве метрики качества классификации. Отметим что в данном примере возможно 2 x 2 x 2 = 8 уникальных сочетаний вcех гиперпараметров.
param_grid = {'vectorizer__ngram_range': [(1,1), (1,2)],
'reduction__n_components': [100, 300],
'classifier__C': [0.1, 1]}
model = GridSearchCV(pipe, param_grid, scoring='f1_macro', cv=3, n_jobs=-1)
model.fit(df_train['text'], df_train['label'])
Выводим наилучшее значение метрики качества.
model.best_score_.round(5)0.65913Выводим оптимальные значения гиперпараметров.
model.best_params_{'classifier__C': 1,
'reduction__n_components': 300,
'vectorizer__ngram_range': (1, 1)}
Теперь реализуем более сложный инструмент на основе двух методов векторизации текстов, одного метода уменьшения размерности и трех методов классификации. Очевидно что всего возможно 2 x 1 x 3 = 6 принципиально разных пайплайнов, например CountVectorizer — TruncatedSVD — DecisionTreeClassifier.
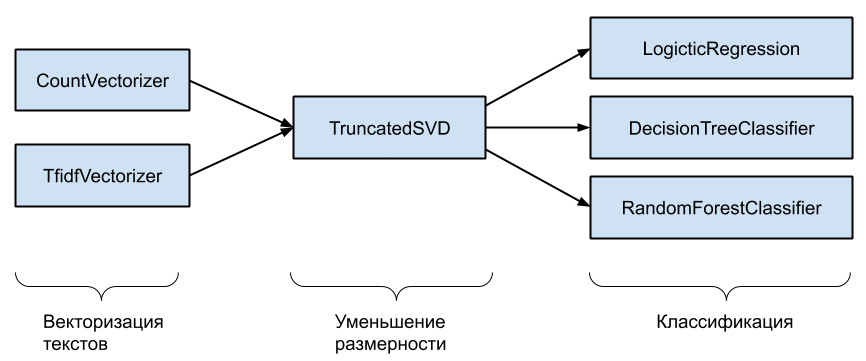
Создаем списки этапов пайплайна и соответствующих классов.
vectorizers = ['countvectorizer', 'tfidfvectorizer']
reductors = ['truncatedsvd']
classifiers = ['logisticregression', 'decisiontreeclassifier', 'randomforestclassifier']
Импортируем необходимые классы.
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
Создаём словарь с набором всех используемых компонентов пайплайнов.
all_models = {'countvectorizer': CountVectorizer(),
'tfidfvectorizer': TfidfVectorizer(),
'truncatedsvd': TruncatedSVD(),
'logisticregression': LogisticRegression(),
'decisiontreeclassifier': DecisionTreeClassifier(),
'randomforestclassifier': RandomForestClassifier()
}
Создаём словарь с наборами гиперпараметров всех компонентов.
all_params = {'countvectorizer': {'countvectorizer__ngram_range': [(1,1), (1,2)]},
'tfidfvectorizer': {'tfidfvectorizer__ngram_range': [(1,1), (1,2)]},
'truncatedsvd': {'truncatedsvd__n_components': [100, 300]},
'logisticregression': {'logisticregression__C': [0.1, 1, 10]},
'decisiontreeclassifier': {'decisiontreeclassifier__max_depth': [5, 10, 15],
'decisiontreeclassifier__min_samples_leaf': [1, 2]
},
'randomforestclassifier': {'randomforestclassifier__n_estimators': [30, 100, 300],
'randomforestclassifier__min_samples_leaf': [1, 2]
}
}
Импортируем метод, позволяющий в одноуровневом цикле создать все возможные сочетания нескольких параметров, а также метод для создания пайплайнов «на лету».
from itertools import product
from sklearn.pipeline import make_pipeline
Создаем пустой датафрейм для сохранения результатов всех экспериментов и запускаем основной цикл, на каждой итерации которого генерируем очередное сочетание всех этапов пайплайна, создаем словарь гиперпараметров для пайплайна, создаем сам пайплайн, выполняем обучение и оценку качества с помощью кросс-валидации, записываем результаты обучения в лог.
df_all_results = pd.DataFrame()
for i, stages in enumerate(product(vectorizers, reductors, classifiers), 1):
vectorizer, reductor, classifier = stages
pipe = make_pipeline(all_models[vectorizer], all_models[reductor], all_models[classifier])
current_params = {}
current_params.update(all_params[vectorizer])
current_params.update(all_params[reductor])
current_params.update(all_params[classifier])
print(current_params)
model = GridSearchCV(estimator=pipe, param_grid=current_params,
scoring='f1_macro', cv=3, n_jobs=-1)
model.fit(df_train['text'], df_train['label'])
df_current_results = pd.DataFrame(data={'pipeline': i,
'vectorizer': vectorizer,
'reductor': reductor,
'classifier': classifier,
'params': model.cv_results_['params'],
'score': model.cv_results_['mean_test_score']})
df_all_results = df_all_results.append(df_current_results)
В результате получаем лог, состоящий из 120 записей. Сортируем лог в порядке убывания метрики F1 и выбираем три лучших пайплайна.
df_all_results.sort_values(by='score', ascending=False, inplace=True)
df_all_results.head(3)
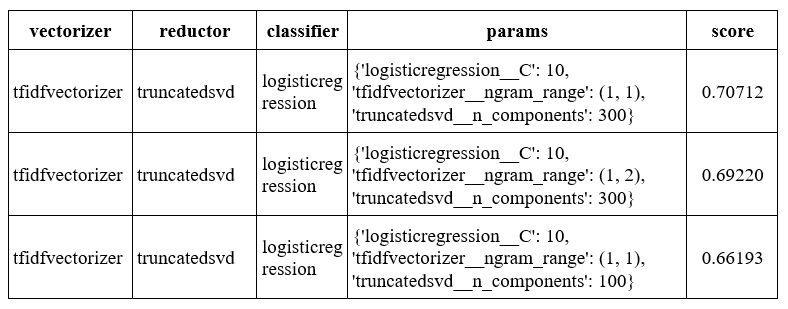
Таким образом, в данном примере наилучшее качество по метрике F1 показывает классификатор на логистической регрессии с параметром регуляризации С=10 с пространством признаков, полученным с помощью TfidfVectorizer на униграммах и уменьшенным до 300 с помощью TruncatedSVD. Предложенный способ можно использовать для поиска оптимальных пайплайнов в задачах машинного обучения. Исходный код ноутбука приведен в репозитории github.com/mporuchikov/complex_classification_pipeline.