/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Добрый день, друзья!
Сегодня мы рассмотрим, как с помощью Python разбить столбец с данными на несколько отдельных колонок и добавить их к существующей таблице. При этом в некоторых строках исходной таблицы порядок параметров в столбце может отличаться (например, некоторые из них могут отсутствовать), что немного усложняет задачу.
Необходимость в этом возникла, когда в рамках проверочных мероприятий был выгружен большой массив информации из базы данных и оказалось, что требуемые для анализа параметры содержатся в одном столбце в следующем виде (их количество в нашей выгрузке намного больше):
{B=-5,695, A=-432,62627, EH=4,47378, K=-513,836492, ZV=5,60153, O=null, WP=-6,430, F=null, UW=0, J=-3,847, param=Пст тв олддяс вловл (ID 56213)}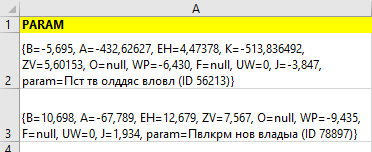
Так как фильтровать, сортировать (и т.п.) данные в таком виде неудобно, было решено разделить колонку, воспользовавшись Python, чтобы каждый параметр для всех строк находился в отдельном столбце. Новые колонки должны добавляться к существующей таблице.
Код для разбиения выглядит следующим образом:
#Импорт библиотек
import pandas as pd
import numpy as np
import re
#Чтение входного файла с данными
%%time
df = pd.read_excel(r'ПУТЬ К ФАЙЛУ\Название исходного файла с данными.xlsx')
#Пишем регулярные выражения
#Шаблоны
r1 = r'(?<=\d),(?=\d)' # ищем запятую между двумя цифрами
r2 = r'(?<=,) ' # ищем пробел после запятой
r3 = r'(?<=\d)\.(?=\d)' # ищем точку между двумя цифрами
#Пишем функции, которые применяют регулярные выражения
def f(a):
try:
a = re.sub(r'{|}','', a) #Убираем символы "{", "|" и "}"
a = re.sub(r2, '', a) #Убираем пробелы после запятых
a = re.sub(r1, '.', a) #Заменяем запятые в десятичных числах на точки (432,63 -> 432.63)
a = a.split(',') #Делим строчку на элементы между запятыми
return {key: value for (key, value) in [i.split('=') for i in a]} #формируем словарь, где 'столбец': 'его значение'
except:
return np.nan
def f_2(a):
try:
a = re.sub(r3, ',', a) #Заменяем обратно запятую в десятичных числах на точку (чтобы потом Excel понимал)
return a
except:
return np.nan
%%time
df['Словарь'] = df['Название разделяемого столбца'].astype('str').apply(f)
%%time
#Словарь преобразуем в отдельные столбцы
j_2 = df['Словарь'].apply(pd.Series)
j_2 = j_2.applymap(f_2)
#Заменяем 'null' на пустую ячейку и соединяем все в одну таблицу
j_2.replace({'null': np.nan}, inplace=True)
Output = df. join(j_2, lsuffix='_left', rsuffix='_right')
#Запись результата в Excel
writer = pd.ExcelWriter('Название итогового файла.xlsx')
Output.to_excel(writer, sheet_name = '1', index=False)
writer.save()
В результате получаем разделенные данные:

Таким образом, с помощью Python легко можно преобразовать имеющуюся в таблице информацию для снижения трудоёмкости её обработки и лучшего анализа.