/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Сегодня попробуем разобраться, как можно быстро решить такую задачу.
В теории информации и компьютерной лингвистики существует понятие редакционного расстояния (метрики, измеряющей разность между двумя последовательностями символов). Чаще всего, для вычисления такого редакционного расстояния используется алгоритм Левенштейна. Под ним понимается минимальное количество операций удаления, вставки и замены символа, необходимое для преобразования одной строки в другую.
Оставим рекуррентную формулу вычисления математикам, алгоритмически вычисления расстояния Левенштейна таково:
D(0, 0) = 0
для всех j от 1 до N
D(0, j) = D(0, j — 1) + цена вставки символа S2[j]
для всех i от 1 до M
D(i, 0) = D(i — 1, 0) + цена удаления символа S1[i]
для всех j от 1 до N
D(i, j) = min{
D(i — 1, j) + цена удаления символа S1[i],
D(i, j — 1) + цена вставки символа S2[j],
D(i — 1, j — 1) + цена замены символа S1[i] на символ S2[j]
}
вернуть D(M, N)
Где S1 и S2 – некоторые строки, длинной m и n соответственно, а d(S1, S2) и есть то самое расстояние.
Проще всего представить себе реализацию этого алгоритма через заполнение матрицы m на n.
На языке программирования C# алгоритм будет выглядеть так:
static int LevenshteinDistance(string firstWord, string secondWord)
{
var n = firstWord.Length + 1;
var m = secondWord.Length + 1;
var matrixD = new int[n, m];
const int deletionCost = 1;
const int insertionCost = 1;
for (var i = 0; i < n; i++)
{
matrixD[i, 0] = i;
}
for (var j = 0; j < m; j++)
{
matrixD[0, j] = j;
}
for (var i = 1; i < n; i++)
{
for (var j = 1; j < m; j++)
{
var substitutionCost = firstWord[i - 1] == secondWord[j - 1] ? 0 : 1;
matrixD[i, j] = Minimum(matrixD[i - 1, j] + deletionCost,
matrixD[i, j - 1] + insertionCost,
matrixD[i - 1, j - 1] + substitutionCost);
}
}
return matrixD[n - 1, m - 1];
}
Где firstWord и secondWord — это слова для сравнения.
Попробуем наш алгоритм на разных кейсах. Предположим, что у нас есть пары клиентов с одинаковыми персональными данными, но при этом разными ФИО.
- «Иванов Ивн Ивнаович» и «Иванов Иван Иванович»
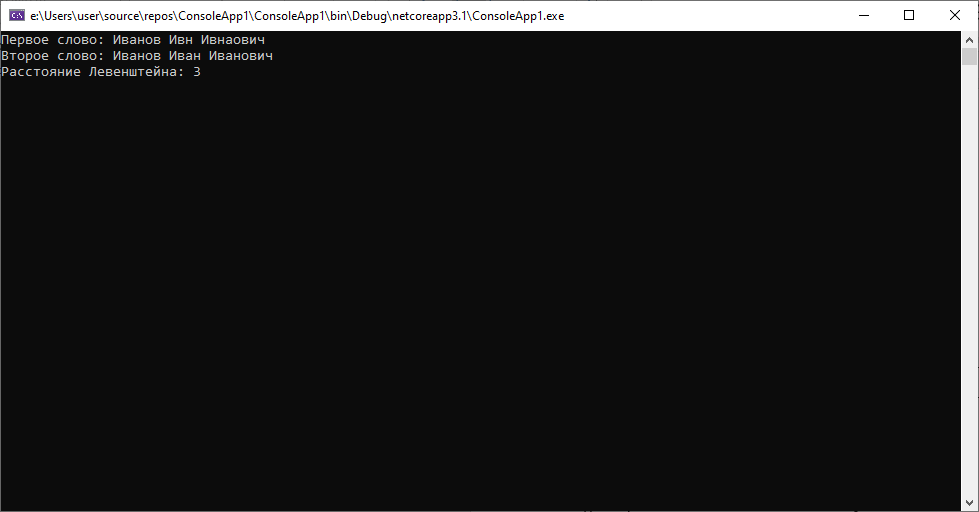
Как мы видим в данном случае имеет место — пропуск символа во втором слове и изменение порядка символов в третьем, при этом дистанция равна «3». Похоже на опечатку.
2. «Иванов Иван Иванович» и «Иванчиков Сергей Иванович»
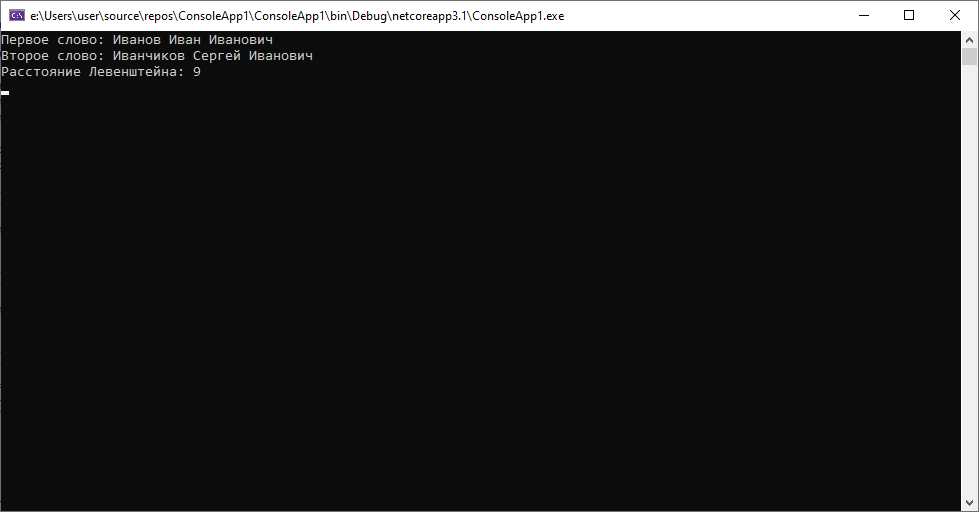
Здесь расстояние уже намного больше. Вряд ли мы имеем дело с одним и тем же человеком, вероятнее всего что-то не так с их паспортными данными.
Этот алгоритм можно немного улучшить, если добавить к нему учет операции транспозиции (перестановки двух ближайших символов) получив тем самым расстояние Дамерау-Левенштейна.
Алгоритм немного усложнится, во вложенном цикле, где прибавляются цены действий — появится следующий код:
if (i > 1 && j > 1
&& firstWord[i - 1] == secondWord[j - 2]
&& firstWord[i - 2] == secondWord[j - 1])
{
matrixD[i, j] = Minimum(matrixD[i, j],
matrixD[i - 2, j - 2] + substitutionCost);
}
В первом кейсе получим следующее:
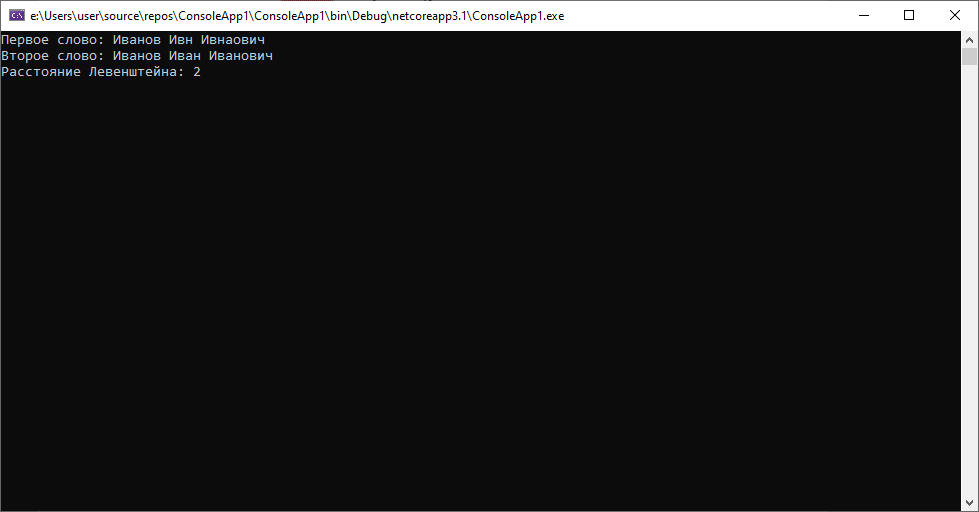
Т.е. дистанция будет еще меньше, при этом во втором кейсе все останется без изменений.
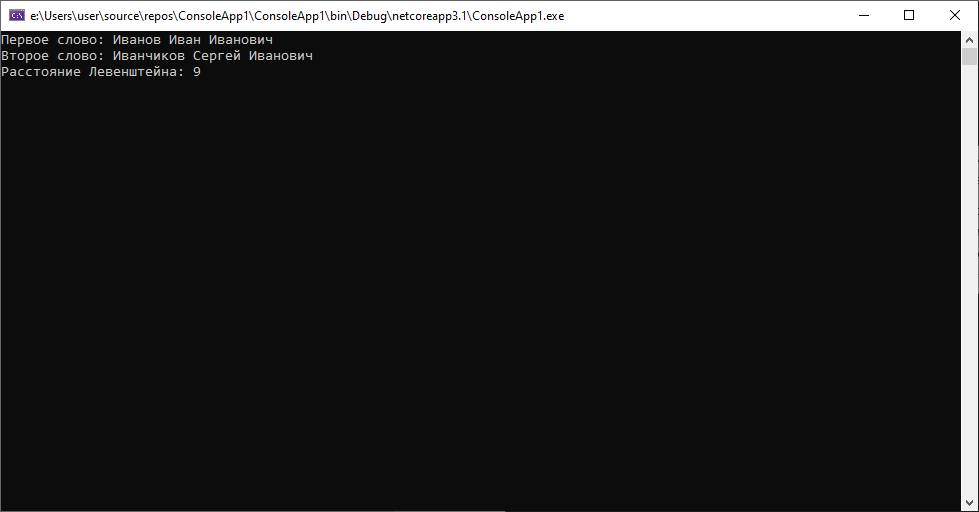
Безусловно, у данного подхода есть свои минусы:
- При перестановке местами слов или частей слов получаются сравнительно большие расстояния (частично, но не полностью решается добавлением операции транспозиции)
- Расстояния между совершенно разными короткими словами оказываются небольшими, в то время как расстояния между очень похожими длинными словами могут быть значительными
Метод не позволяет на 100% определить где была опечатка, а где мы имеем дело с «разными» данными, но позволяет значительно сократить время на проверку таких «опечаток»(особенно, если она будет производиться «вручную») за счет фильтрации по величине дистанции.