/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 2 мин.
На сегодняшний день существует много различных систем распознавания речи, например, такие системы как: Amazon Alexa, Yandex, Google и Siri. Большинство этих систем имеют открытые API и свободны для использования. Такие системы очень хорошо справляются с задачей распознавания текста, однако они работают через интернет.
Существуют и открытые системы распознавания речи, такие как: PocketSphinx, Kaldi, Mozilla DeepSpeech. Рассмотрим систему PocketSphinx. Для того чтобы она работала с русским языком нужно предварительно скачать акустическую модель, которая основана на скрытых Марковских моделях.
Для распознавания будем использовать PocketSphinx из библиотеки speech_recognition языка Python. Скачанную модель русского языка необходимо загрузить в директорию site-packages/speech_recognition/pocketsphinx-data. После этого можно приступать к распознаванию. Ниже, продемонстрирован пример распознавания аудиозаписи в текст.
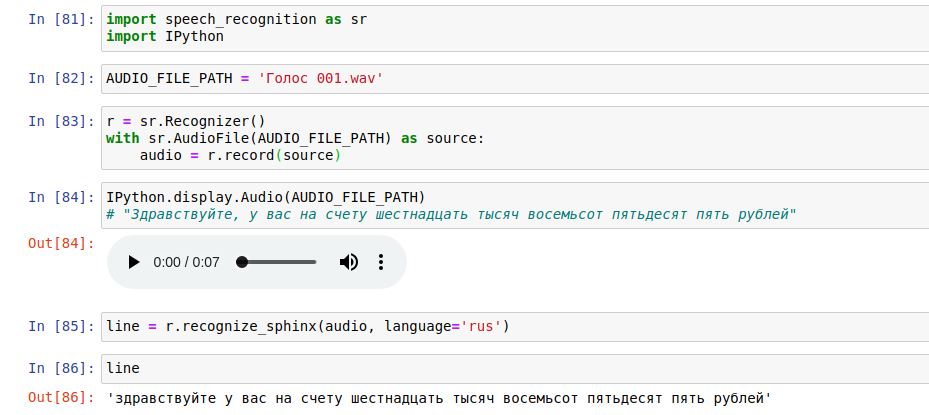
Из рисунка видно, что PocketSphinx отлично справилась с распознаванием аудио. Однако распознавание 7 секунд записи заняло около 50 секунд. Теперь перед нами дан уже текст, и мы можем превратить его в список слов с помощью библиотеки NLTK. После этого мы можем сверить слова со списком недопустимых слов и выявить нарушение. Пример показан на рисунке ниже.
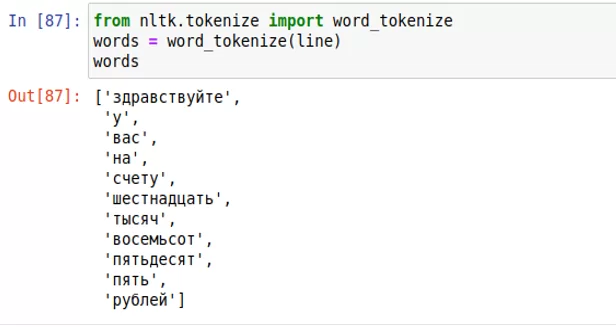

Помимо этого можно произвести лемматизацию (приведение словоформы к её нормальной (словарной) форме) полученных слов, что упростит задачу поиска недопустимых слов. Применяя описанные инструменты, мы можем с легкостью узнать, говорил ли оператор то, что ему запрещено.