/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
Выявление мошеннических операций с кредитными картами.
Важно, чтобы компании, выпускающие кредитные карты, могли распознавать мошеннические операции с кредитными картами, чтобы клиенты не платили за товары, которые они не покупали.
Допустим у нас есть наборы данных, которые содержат транзакции, совершенные с помощью кредитных карт в августе 2012 года держателями карт.
В этом наборе данных представлены транзакции, которые произошли за два дня, и у нас 631 мошенничество из 351902 транзакций. Набор данных сильно не сбалансирован, это значит, что на положительный класс (мошенничество) приходится 0,1793% всех транзакций. Можно считать, что выборка не сбалансирована, когда размеры классов отличаются более, чем в 10 раз.
Набор данных содержит только числовые входные переменные, которые являются результатом преобразования PCA. PCA – это Метод Главных Компонент (Principal Components Analysis). Он используется в основном для уменьшения размерности данных, но и для обезличивания данных тоже может использоваться, об этом расскажу в следующей статье. А сейчас вернемся к нашим несбалансированным данным и деревьям решений (Random Forest).
К сожалению, из-за проблем с конфиденциальностью, организации, выдающие кредитные карты, не могут предоставить оригинальные функции и дополнительную справочную информацию о данных. Функции V1 – V28 являются основными компонентами, полученными с помощью PCA (это наши 28 столбцов, преобразованные с помощью PCA). Единственными функциями, которые не были преобразованы с помощью PCA, являются «Время» и «Количество». Функция «Время» содержит секунды, прошедшие между каждой транзакцией и первой транзакцией в наборе данных. Функция «Сумма» – это сумма транзакции. Функция «Класс» – это переменная ответа, которая принимает значение 1 в случае мошенничества и 0 в противном случае.
Учитывая коэффициент дисбаланса класса, мы рекомендуем измерять точность используя область под кривой Precision-Recall Curve (AUPRC). Вообще есть разные методы борьбы с дисбалансом, но это применяется только для определенных случаев, когда мы используем невероятностную или многоклассовую классификации. Также логистической регрессии (и её подобие – нейросетях) баланс классов может оказать сильное влияние.
В деревьях решений дисбаланс классов влияет на меры неоднородности (impurity) листьев, но это влияние почти одинаково для всех тех, кто попадает в очередную разбивку (split), поэтому почти не влияет на выбор разбивок. И так выбираем модель обучения на случайном лесе с оценкой качества модели AUPRC
Метрики Precision, Recall что это?
Precision (точность) то есть если мы нашли 10 положительных примеров и ни одного ложного срабатывания, то Precision равен 1 (но она не отвечает на вопрос на сколько в целом удается хорошо находить положительные примеры).
Recall (полнота) сколько в целом нашли положительные примеры (но тут нет информации сколько мы переплатили ложными срабатываниями).
Считаем, что нам важно выявить максимальное число фальсификаций даже если будут ложные срабатывания.
Для перебора параметров и последующей кроссвалидации можно использовать GridSearchCV. В этот метод можно передать модель с определенным набором параметров, на основании которых при помощи кроссвалидации он переберет все возможные сочетания заданных параметров и выберет наилучшее для заданной заранее нами метрики, которая выбирается исходя из условий задачи.
Кроссвалидация делит all data на train и test, чтобы постоянно не обучать только на train, потому что это приведет к переобучению модели и как следствие модель будет хорошо работать на обучающей выборке и выдавать достаточно высокие показатели качества модели, а на реальных (рабочих) данных выдаст значительно хуже. Train делиться на указанное количество сплитов и каждый кусок должен побывать как на train, так и на test потом полученный скор для всех сплитов усредняется и так пока не переберет все параметры, что мы указали, получается мы избегаем частично переобучения с помощью кроссвалидации.
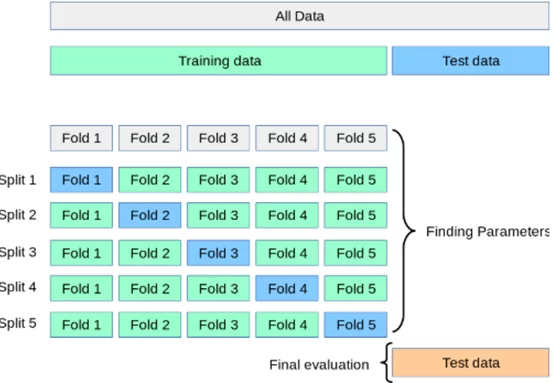
И так проводим Exploratory Data Analysis (EDA) с нашими данными. Делим наш датасет на тренировочный и тестовый. Инициализируем решетку параметров (param_grid), которые будут перебираться на тренировочном датасете и выведет лучшие параметры для нашей метрики. Обучаем на train, выявляя лучшие параметры, после чего используем их на тестовой выборке.
from sklearn.model_selection import GridSearchCV
clf = RandomForestClassifier()
param_grid = {
'criterion': ['entropy'], # ['gini','entropy'],
'n_estimators' : range(4, 15, 3), # число деревьев
'max_depth' : range(3, 7, 1), # максимальная глубина
# 'min_samples_leaf' : range(1, 10, 2), # минимальное число проб в листе
# 'min_samples_split' : range(2, 10, 2) # минимальное число проб для разделения
}
GridSearchCV = GridSearchCV(clf, param_grid, n_jobs=-1, cv=3)
GridSearchCV.fit(X_train, y_train)
best_estimator_rf = GridSearchCV.best_estimator_
print(best_estimator_rf)
best_params_rf = GridSearchCV.best_params_
print(best_params_rf)
imp = pd.DataFrame(best_estimator_rf.feature_importances_,
index = X_train.columns,
columns = ['importance_for))'])
print(imp.sort_values('importance_for))', ascending=False).head(10))
print(imp.sort_values('importance_for))').plot(kind='barh', figsize=(12, 8)))
Получим лучшие параметры из тех, что мы указали в решетке и так же можем посмотреть степень влияния этих параметров на графике, что может быть очень интересно для исследований!
{'criterion': 'entropy', 'max_depth': 6, 'n_estimators': 10}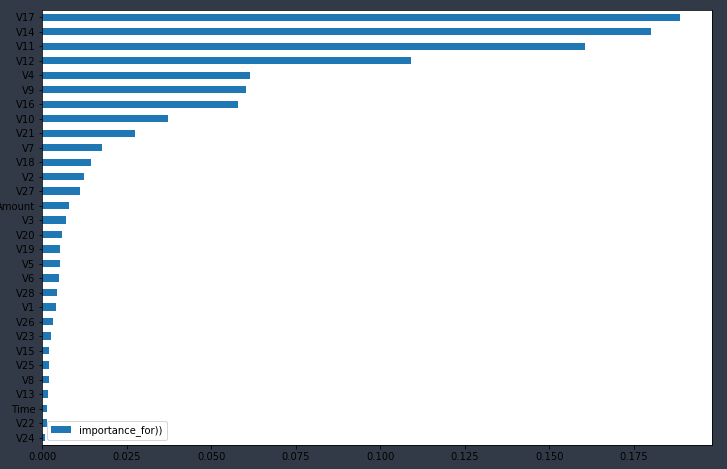
best_estimator_rf.score(X_test, y_test) # максимальное среднее значение accuracy
0.9995318501494888 Пробуя модель на тестовой выборке получаем эррэй с отнесением к классу 1 или 0
from sklearn.metrics import precision_score, recall_score
y_pred = best_estimator_rf.predict(X_test)
y_pred # это не класс а вероятность отнесения к этому классу !!
array([1, 0, 0, ..., 0, 0, 0], dtype=int64)
Посмотрим наши параметры
precision_score(y_test, y_pred)
recall_score(y_test, y_pred)
0.9007633587786259
0.7919463087248322
Так же мы можем посмотреть с какой вероятностью мы имели дело, когда относили в тот или иной класс!
y_predicted_prob = best_estimator_rf.predict_proba(X_test)
y_predicted_prob # вероятность отнесения к тому или другому классу
array([[1.98330879e-03, 9.98016691e-01],
[9.99835631e-01, 1.64368814e-04],
[9.99816159e-01, 1.83841278e-04],
...,
[9.99915443e-01, 8.45569281e-05],
[9.99895860e-01, 1.04139837e-04],
[9.99875136e-01, 1.24864323e-04]])
Регулируя саму вероятность отнесения к тому или иному классу, мы можем менять сами метрики
y_pred = np.where(y_predicted_prob[:,1] > 0.8, 1, 0) # что больше 0,8 то 1 остальное 0
y_pred # precision больше , recall меньше
precision_score(y_test,y_pred)
recall_score(y_test,y_pred)
0.9545454545454546
0.5637583892617449
Либо
y_pred = np.where(y_predicted_prob[:,1] > 0.1, 1, 0)
# тут наоборот precision меньше , recall больше
precision_score(y_test,y_pred)
recall_score(y_test,y_pred)
0.6479591836734694
0.8523489932885906
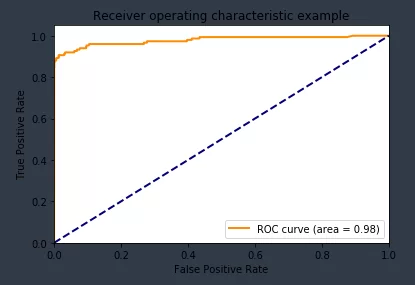
Посмотрим графики precision recall curve, roc auc
from sklearn.metrics import roc_curve, auc
fpr, tpr, thresholds = roc_curve(y_test, y_predicted_prob[:,1])
roc_auc= auc(fpr, tpr)
plt.figure()
lw = 2
plt.plot(fpr, tpr, color='darkorange',
lw=lw, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import plot_precision_recall_curve
import matplotlib.pyplot as plt
from sklearn.metrics import average_precision_score
average_precision = average_precision_score(y_test, y_pred)
disp = plot_precision_recall_curve(best_estimator_rf, X_test, y_test)
disp.ax_.set_title('2-class Precision-Recall curve: '
'AP={0:0.2f}'.format(average_precision))
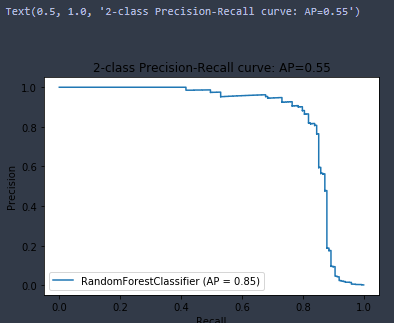
Мы получили качество нашей модели равным 0,85, что говорит о правильности отнесения к нашему классу с точностью в 85%, что довольно хорошо с учетом того, что мы использовали в решетке только перебор 2х параметров! С учетом закомментированного кода у нас бы получилось использовать перебор 5и параметров, что заметно бы увеличило время расчета, так как вариантов перебора получилось бы 640 и это без учета изменения сплита на train и test (который у нас равен 3м).
И так мы можем улучшить нашу модель в данном случае только если будем перебирать большее число параметров, но для этого необходимо значительно больше времени либо более мощные вычислительные мощности!