/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
В предыдущей статье я описал один из способов организации проекта в QlikView (далее – QV), а также основные методов загрузки данных, используемые в первом слое разработки AppTier1. В данной статье я хочу описать основные отличия синтаксиса в QV от SQL и схемы модели данных.
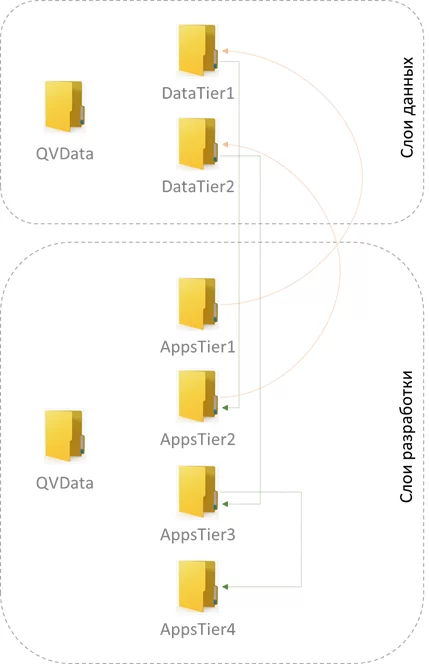
В целом процесс трансформации представляет из себя совокупность действий по преобразованию данных, удалению лишней информации и добавлению новой на основе существующей. Первоначальные данные мы выгрузили и сохранили в папке DataTier1, для их загрузки применяется следующий метод:
LOAD
Field1,
Field2,
Field3
FROM
[C:\Folder\File1.qvd] (qvd)
WHERE
Field1 = Condition1 and Field2=Condition2 or Field3=Condition3
[C:\Folder\File1.qvd] (qvd) – директория расположения файла
Скрипт формирования QVD файла из загруженной в QV таблицы следующий:
STORE tmpData INTO [C:\Folder\File1.qvd] (qvd);
Как мы видим, синтаксис по логике похож на SQL-ский – также указываем какие поля выгружать, откуда и по каким условиям.
Далее опишу основные отличия в синтаксисе от SQL:
- Имена таблиц и полей чувствительны к регистру.
- Название таблицы, в которую загружаются данные, указывается перед оператором Load:
Table1:
load * from
[C:\Users\kukhtenkoav\Desktop\UPiO\Qlik\Мониторинг целей\30.06\QVData\DataTier1\Castom_AIM.qvd] (qvd);

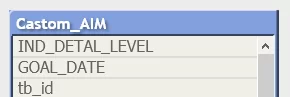
Если не прописать название, то оно присвоится по имени файла:
3. Операторы Qualify и Unqualify.
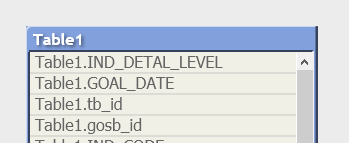
Qualify – делает приписку с названием таблицы перед именем поля:
Qualify *;
Table1:
load * from
[C:\Users\kukhtenkoav\Desktop\UPiO\Qlik\Мониторинг целей\30.06\QVData\DataTier1\Castom_AIM.qvd] (qvd);
Можно указывать конкретные поля:
Qualify tb_id, gosb_id;
Table1:
load * from
[C:\Users\kukhtenkoav\Desktop\UPiO\Qlik\Мониторинг целей\30.06\QVData\DataTier1\Castom_AIM.qvd] (qvd);
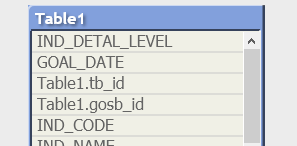
Unqualify – соответственно наоборот, снимает эту метку.
4. Нет операторов Union и Union All – вместо них используется Concatenate.
5. Нет Case…when…end, вместо него используется if:
if(Field1=1, 'A','B') Так же применяются вложенные if:
if(Field1=1, 'A', if(Field2=1,'B','C'))6. Для присвоения значений переменным помимо Set используется Let (отличия в том, что Let производит вычисления, Set – нет):
LET vTable = 't_FCT_BFO_DAILY' 7. Джоины работают так же, как и в SQL, только нет необходимости прописывать поля, по которым происходит соединение.
Table1:
Load * inline [
Key, field1, field2
1, Иван, Иванов
3, Петр, Петров
4, Сергей, Сергеев
];
left join(Table1)
Load * inline [
Key, field3, field4
1, Аудитор, ОАРБ
2, Старший аудитор, ОАКБ
4, Аудитор, ОАРБ
];
Джоин происходит по всем полям с одинаковыми именами в обеих таблицах – в данном случаем по полю Key.
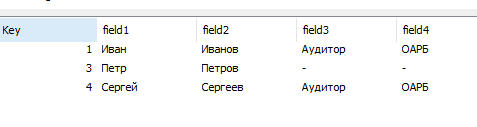
После трансформации данных все QVD файлы загружаются в один QVW и на их основе формируется общая модель данных. Таблицы соединяются между собой при помощи ключей. Как правило, используются две схемы данных:
- Звезда:
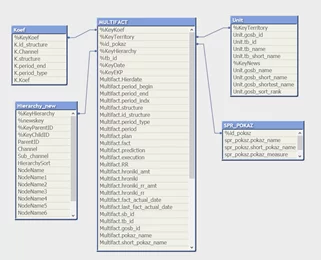
Основным преимуществом является легкое понимание взаимоотношений между таблицами.
- Снежинка:
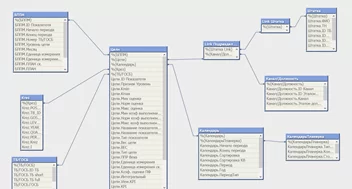
Удобно применять при наличии различных справочников, которые соединяются ключами с таблицей фактов.
Обращаю внимание, что таблицы соединяются ключами автоматически при наличии одинаковых имен полей. Если одинаковых наименований полей более одного, то формируются синтетические ключи:
Table1:
load * inline[
Key1, Key2, field1, field2
1, 101, Иван, Иванов
3, 103, Петр, Петров
4, 104, Сергей, Сергеев
];
Table2:
load * inline[
Key1, Key2, field3, field4
1, 101, Аудитор, ОАРБ
2, 102, Старший аудитор, ОАКБ
4, 104, Аудитор, ОАРБ
];
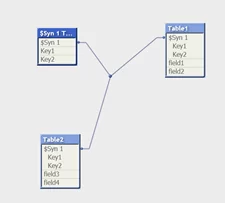
Почему синтетические ключи – это плохо? В зависимости от их количества и объема данных, в QV они могут быть обработаны неполноценно, кроме того, для их обработки потребуется дополнительная время и объем оперативной памяти. Так же, наличие синтетических ключей усложняет визуальное понимание модели данных.
Для устранения синтетических ключей можно применять несколько методов.
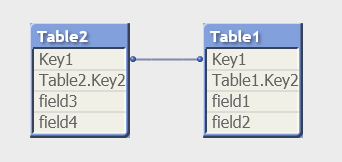
- Если таблицы требуется связать по одному полю:
— применение оператора Qualify:
QUALIFY key2;
Table1:
load * inline[
Key1, Key2, field1, field2
1, 101, Иван, Иванов
3, 103, Петр, Петров
4, 104, Сергей, Сергеев
];
Table2:
load * inline[
Key1, Key2, field3, field4
1, 101, Аудитор, ОАРБ
2, 102, Старший аудитор, ОАКБ
4, 104, Аудитор, ОАРБ
];
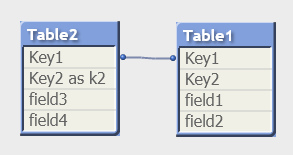
— переименование столбца при помощи as:
Table1:
load * inline[
Key1, Key2, field1, field2
1, 101, Иван, Иванов
3, 103, Петр, Петров
4, 104, Сергей, Сергеев
];
Table2:
load * inline[
Key1, Key2 as k2, field3, field4
1, 101, Аудитор, ОАРБ
2, 102, Старший аудитор, ОАКБ
4, 104, Аудитор, ОАРБ
];
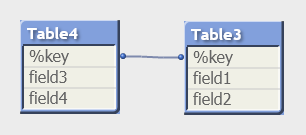
2. Если таблицы требуется связать по нескольким полям, то создание комбинированного ключа:
-без хэширования:
Table1:
load * inline[
Key1, Key2, field1, field2
1, 101, Иван, Иванов
3, 103, Петр, Петров
4, 104, Сергей, Сергеев
];
Table2:
load * inline[
Key1, Key2, field3, field4
1, 101, Аудитор, ОАРБ
2, 102, Старший аудитор, ОАКБ
4, 104, Аудитор, ОАРБ
];
Table3:
load Key1&Key2 as %key, field1, field2 resident Table1;
drop table Table1;
Table4:
load Key1&Key2 as %key, field3, field4 resident Table2;
drop table Table2;
— с хэшированием:
load autonumberhash128(Key1&Key2) as %key, field1, field2 resident Table1; Как мы видим, синтаксис написания скриптов в QV довольно быстро станет понятен для всех, кто работал в SQL, из-за своего сходства с ним. В свою очередь, принцип построения моделей напоминает MS Access, кто работал в нём так же без труда освоит эту часть QV. Но следует помнить о том, что, как и в любом языке, в QV есть свои особенности. В следующей статье я опишу основные объекты визуализации в ответах и расскажу о базовых правилх написания выражений анализа множеств.