/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Введение
Недавно появилась задача – найти и удалить содержащие номера карт файлы, размещенные на общем ресурсе. Если бы мы искали что-то, определенное и однозначное, мы могли бы воспользоваться поиском в самой операционной системе — она позволяет искать текст в содержимом файла. Но, как правило, поиск стандартными средствами занимает очень много времени. А если вы еще хотите использовать маски или регулярные выражения, то как быть? Поделюсь, как я решал эту задачу.
Инструменты
Данную задачу можно решить на многих языках взяв за основу идею, описанную в этой статье. Я буду делать реализацию на языке Python, а инструменты использовать «из коробки», без импорта сторонних библиотек. Почему я не использовал библиотеку Pandas? Pandas хороший инструмент для работы с файлами Excel, но он достаточно массивный и ресурсоемкий для решения нашей задачи.
Решение задачи.
Углубимся в формат XLSX. Что он из себя представляет? Файл Excel — это обычный структурированный архив с расширением .XLSX. Если мы изменим расширение на .ZIP, то сможем открыть его с помощью архиватора, установленного в вашей операционной системе.
Давайте так и сделаем:

Файл Excel открылся в архиваторе, и мы видим структуру самого архива. Нам нужна папка [xl]. Проваливаемся в нее и видим:
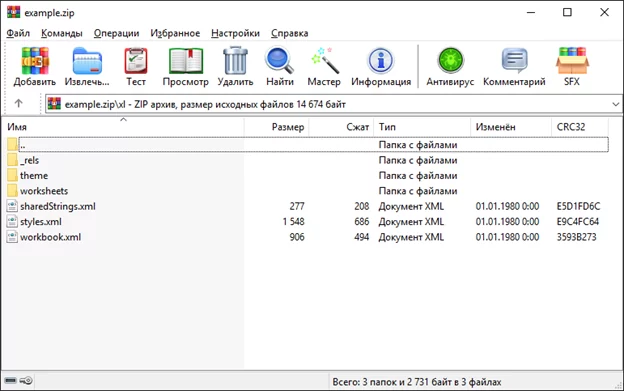
Нам интересны директория [worksheets] и файл [sharedStrings.xml].
В файле [sharedString.xml] хранятся все текстовые поля, которые есть на листах в Excel, т.е. если поле текстовое, то оно будет хранится в этом файле, а ссылка на это поле будет находится в директории [worksheets] на соответствующем листе. Если в нескольких ячейках будет одно и тоже слово, то в файле будет одно слово, а в ячейках будет указана одна ссылка на это слово (см. рис.).
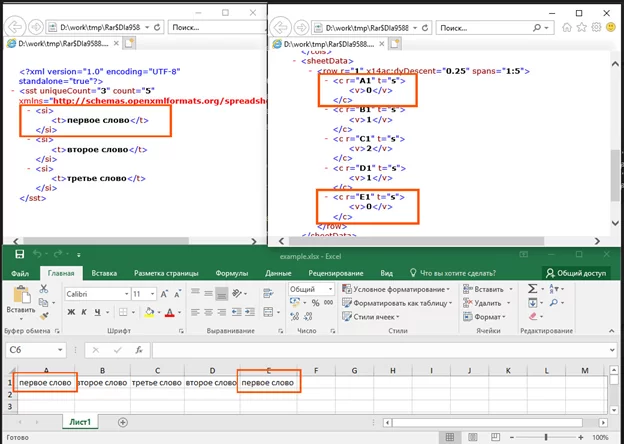
Знаем, что номер карты является текстовым полем, соответственно он будет находится в этом файле. Приступим к написанию кода. Нам понадобятся следующие библиотеки: os – для работы с путями ОС, zipfile – для работы с архивами, re – для работы с регулярными выражениями — паттернами (об этом вы можете почитать в нашей статье).
import os, zipfile, re #импортируем библиотеки
#Определяем регулярные выражения
pattern_card16=rb"(\b\d{16}\b|\b\d{4}\s\d{4}\s\d{4}\s\d{4}\b|\b\d{8}\s\d{8}\b)"
pattern_card18=rb"(\b\d{18}\b|\b\d{8}\s\d{10}\b)"
Далее пишем функцию, которая будет сканировать выбранную нами директорию:
def find_file(dirn, path): # функция принимает os.listdir, и путь на папку
try:
for i in dirn:
if os.path.isfile(path+'/'+i): #проверяем что перед нами, файл или нет
#Проверяем расширение файла и исключаем системные которые начинаются на [~$]
if i.find('.xlsx')!=-1and i.find('~$')==-1 and i.find('.xlsx.')==-1:
open_arch(path+'/'+i) #Функция по обработке архивов
else:
#Если это директория, то проваливаемся в нее
find_file(os.listdir(path+'/'+i),path+'/'+i)
except Exception as err:
print(err,path+'/'+i)
Теперь напишем саму функцию, которая будет обрабатывать найденные по условию файлы:
def open_arch(path_file):
z = zipfile.ZipFile(path_file, 'r') #открываем архив
files=z.namelist() #получаем список файлов в архиве
try:
for f in files:
if f=='xl/sharedStrings.xml':
if re.search(pattern_card16, z.read(f))!=None or re.search(pattern_card18, z.read(f))!=None:
list_file.write(path_file+'\n') #Если находит совпадение, то пишем путь в файл
#print(re.findall(pattern_card16, z.read(r))) # если вам нужно
#print(re.findall(pattern_card18, z.read(r))) # выводить совпадения
except Exception as err:
print(err, files)
Определяем директорию для поиска и запускаем функцию для поиска:
path='Y:' #указываем путь к общему ресурсу, здесь я его подцепил как диск Y:
list_file=open('list_file', 'w+') #открываем файл для записи
find_file(os.listdir(path), path) #запускаем обработку
Резюме
Наша работа сделана. Ждем, когда отработает скрипт и мы получим итоговый файл для анализа. Вы зададите вопрос, почему я сразу не стал удалять файлы? Потому что поиск основан на простом регулярном выражении и туда могут попасть номера заявок, договоров и т.д.
В результате нам удалось избежать ручного анализа более 154 тысяч файлов и сократить выборку более чем в 100 раз. Если вам понравилась статья и вы хотите подробнее узнать о структуре файлов xlsx, пишите в комментариях. Я посвящу этому отдельную статью и расскажу, как я создавал Excel файлы с нуля и писал библиотеку на PHP.
Я надеюсь, моя статья была полезна. Спасибо за внимание.