/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Рассмотрим простой пример создания заветной цепочки с использованием Python. Предположим, данные об истории правок отчета или денежные операции сохраняются на сервере. Эти данные должны быть гарантированно неизменными, чтобы им можно было доверять.
В этом нам и поможет технология блокчейна, сохраняя в каждой новой записи историю всех предыдущих записей. В нашем блокчейне каждый блок будет содержать условные данные (сумму), индекс (id операции), метку времени (дату операции), а также собственный хэш и хэш предыдущего блока. Зачем нужен хэш предыдущего блока? В этом и состоит криптографическая ценность. Это доказательство того, что данные не были изменены или добавлены «задним» числом, так как на хэш текущего блока будет влиять хэш всех предыдущих блоков.
Предположим, требуется сохранить достоверность следующих данных, хранящихся на нашем сервере (для удобства пример уже помещён в датафрейм — df).
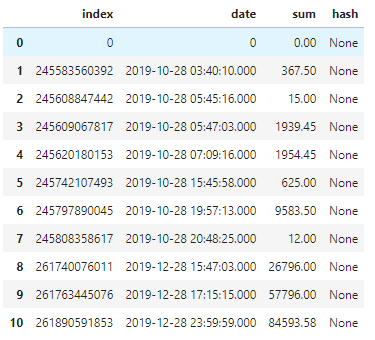
Обратите внимание, сейчас мы добавим хэш сразу для 10 строк и, так как каждый блок содержит хэш предыдущего блока, для первичного запуска используется нулевая строка с пустыми данными, чтобы можно было собрать хэш для первой строки.
Для начала напишем класс, определяющий структуру нашего блока.
class Block:
def init(self, index, timestamp, data, prev_hash):
self.index = index
self.timestamp = timestamp
self.data = data
self.prev_hash = prev_hash
self.hash = self.hash_block()
def hash_block(self):
sha = hashlib.sha256()
sha.update(str(self.index).encode('utf-8'))
sha.update(str(self.timestamp).encode('utf-8'))
sha.update(str(self.data).encode('utf-8'))
sha.update(str(self.prev_hash).encode('utf-8'))
return sha.hexdigest()Задача класса – создание хэша на основе id операции (index), даты операции (timestamp), суммы операции (data) и хеша предыдущего блока (prev_hash).
Теперь циклом прогоним каждую строку через наш класс и допишем её хэш:
for i in range(1, len(df)):
block_to_add = Block(df["index"][i],
df["date"][i],
df["sum"][i],
df["hash"][i-1])
df["hash"][i] = block_to_add.hashПосле этого датафрейм будет иметь следующий вид:
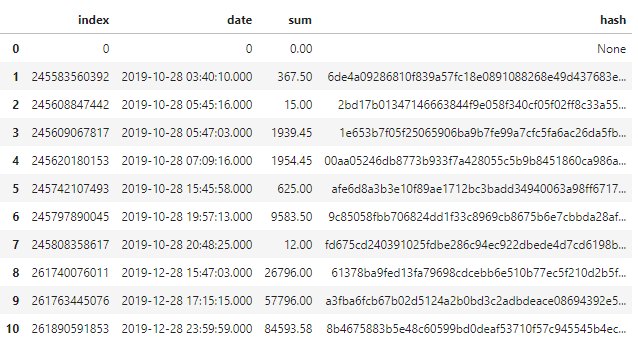
В дальнейшем, при проведении новых операций, нужно будет обработать только одну строку:
block_to_add = Block(df["index"][next_i],
df["date"][next_i],
df["sum"][next_i],
df["hash"][next_i-1])
df["hash"][next_i] = block_to_add.hash
, где next_i это индекс новой строки.Вот мы и получили наш блокчейн. Каждая новая запись содержит хэш всех предыдущих строк, и любое вмешательство в уже существующую запись не останется незамеченным. Это самый простой пример технологии блокчейна для использования в повседневной работе. Согласитесь, это прибавит вам уверенности, в случае появления “сомнительных” данных, которых вы не видели ранее!