/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Что же такое статистическая гипотеза. Приведу определение из Википедии.
Статистическая гипотеза — предположение о виде распределения и свойствах случайной величины, которое можно подтвердить или опровергнуть применением статистических методов к данным выборки.
Случайная величина, например, среднее, берется из выборки, которая тоже должна быть взята случайно и в ней должно быть от 30 элементов. Если выборка берется не случайно, то и данные будут не достоверные. Значение в 30 элементов это научно доказанный факт, так как начиная от 30 выборочные среднее и дисперсия близки к реальному среднему и дисперсии генеральной совокупности.
В общем виде алгоритм проверки выглядит следующим образом:
1. Формулировка основной гипотезы Н₀ и альтернативной гипотезы Н₁
2. Задание уровня значимости α
Определение уровня значимости довольно большая тема, поэтому обозначим кратко основные моменты.
Есть стандартные уровни значимости 0,1; 0,05; 0,01; 0,001.
И условно их можно выбирать так. Если объем выборки небольшой до 100 единиц, то можно вполне отвергнуть нулевую гипотезу при уровне значимости 0,05 или даже 0,1. При объеме выборки, измеряемой сотнями – от 100 до 1000, следует понизить уровень значимости хотя бы до 0,01. А при больших выборках, измеряемых тысячами наблюдений, уверенно отвергать нулевую гипотезу можно только при значимости меньшей 0,001.
В целом же для каждой конкретной задачи нужно смотреть на данные и подбирать уровень значимости, который в лучшей мере подойдет для этих данных.
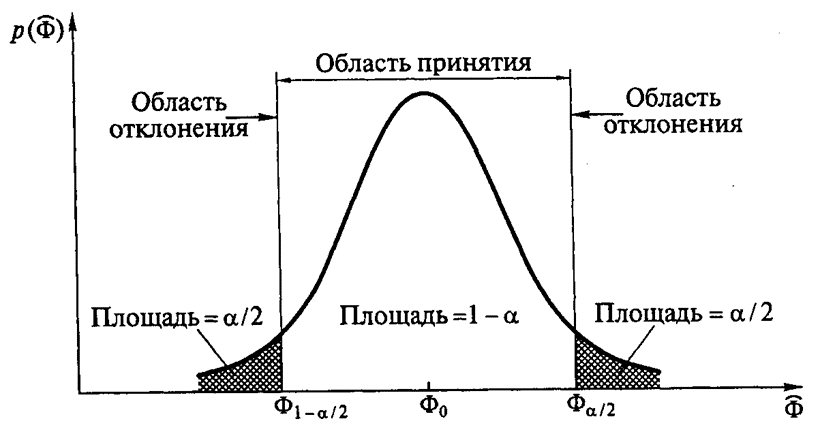
3. Выбор статистического критерия
4. Определения правила принятия решения
5. Принятие решения на основе данных
Теперь протестирую на Python используя библиотеку scipy.stats.
Гипотеза: средние показатели тарифов различаются.
- Сформулирую нулевую гипотезу (Н₀). Среднее значение тарифов тариф_1 и тариф_2 одинаковое
- Сформулирую альтернативную гипотезу (Н₁). Среднее значение тарифов тариф_1 и тариф_2 разное
Для примера возьму распределение для тарифа_1 в виде data_1, а для тарифа_2 в виде data_2
Буду использовать следующие данные для проверки гипотез:
data_1 = np.random.uniform(-1, 0, 1000) # равномерное распределение тариф1
data_2 = np.random.normal(-1, 2, 1000) # нормальное распределение тариф2
В примере буду использовать α = 0.05
Первым тестом для проверки будет тест Шапиро-Уилка.
Тест оценивает набор данных и дает количественную оценку вероятности того, что данные были получены из Гауссовского (нормального) распределения.
Для теста используется формула:
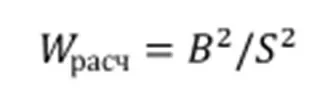
Здесь S2 — сумма квадратов отклонений значений выборки от среднего арифметического:
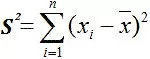
Значение B2 находят по формуле:
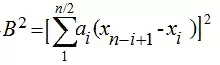
где i – номер элемента в вариационном ряду. В формуле учитывается только целая часть от n/2. Значения находят из таблиц.
data = pd.concat([data_1, data_2]).reset_index(drop=True)
# сделаем генеральное распределение для проведение теста
stat, p = stats.shapiro(data)
print('Statistics=%.3f, p-value=%.3f' % (stat, p))
if p < alpha:
print('Отклонить гипотезу о нормальности')
else:
print('Принять гипотезу о нормальности')
Statistics=0.919, p-value=0.000
Отклонить гипотезу о нормальности
Тест показал, что нормальность не соблюдается.
Следующий тест, тест Левена.
Логическая статистика, используемая для оценки равенства дисперсий для переменной, рассчитанной для двух или более групп. Некоторые распространенные статистические процедуры предполагают, что дисперсии популяций, из которых взяты различные выборки, равны. Тест Левена оценивает это предположение. Он проверяет нулевую гипотезу о том, что дисперсии популяции равны. Если результирующее p-значение теста Левена меньше некоторого уровня значимости (обычно 0.05), полученные различия в выборочных дисперсиях вряд ли имели место на основе случайной выборки из популяции с равными дисперсиями. Таким образом, нулевая гипотеза равных дисперсий отвергается и делается вывод о наличии разницы между дисперсиями в популяции.
Для теста используется формула:
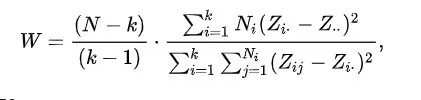

test_leven, p = stats.levene(data_1, data_2)
print('Statistics=%.3f, p-value=%.3f' % (test_leven, p))
alpha = 0.05
if p < alpha:
print('Отклонить гипотезу о равенстве дисперсий')
else:
print('Принять гипотезу о равенстве дисперсий')
Statistics=1272.766, p-value=0.000
Отклонить гипотезу о равенстве дисперсий
Проверяю гипотезу с помощью scipy.stats.ttest_ind, так как с его помощью можно сравнить средние двух совокупностей.
results = stats.ttest_ind(
data_1[0],
data_2[0],
equal_var=False) # Так как нормальность не соблюдается
print('p-значение:', results.pvalue)
if (results.pvalue < alpha):
print("Отвергаем нулевую гипотезу")
else:
print("Не получилось отвергнуть нулевую гипотезу")
p-значение: 2.19278763437e-16
Отвергаем нулевую гипотезу
Тест показывает, что гипотеза Н₀ не подтверждена, следовательно, нулевая гипотеза отвергается. Поэтому принимается альтернативная гипотеза Н₁, cреднее значение тарифа_1 и тарифа_2 разное.
В статистике есть и другие тесты для проверки гипотезы, главное понять какой конкретный тест подходит для Ваших данных. И не допускать ошибок первого и второго рода. Так как вероятность принять неправильную гипотезу, Н₀, или отвергнуть правильную всегда есть. Поэтому тестов много, как и данных, найдите правильный тест для своих гипотез.