/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
При выполнении задач по машинному обучению, зачастую приходится анализировать и «очищать» огромные выгрузки, в том числе с использованием инструментов Python. Это необходимо для подготовки данных, которые подаются на вход обучаемой модели, так как именно от них во многом будет зависеть качество полученного решения, а также время, затраченное на обучение.
Так, для анализа неэффективных затрат на транспортное обеспечение я первым делом сформировала выгрузку заявок.
Сегодня я буду анализировать размеченный датасет с заявками по транспортному обеспечению для обучения модели выявления признаков получения завышенной компенсации.
В датасете у нас уже загружен целевой признак «target», где 1 – «заявка, оформленная с нарушениями», а 0 – «заявка, оформленная без нарушений».
Загружаем данные для обработки:
df = pd.read_csv('all_data.csv', sep='\t')Посмотрим на наши данные, это важно делать всегда, чтобы понять, что все прочиталось корректно и датасет можно дальше обрабатывать- размер датасета 143 096 строк и 307 столбцов:
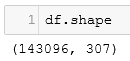
Вывод первых пяти строк датасета:
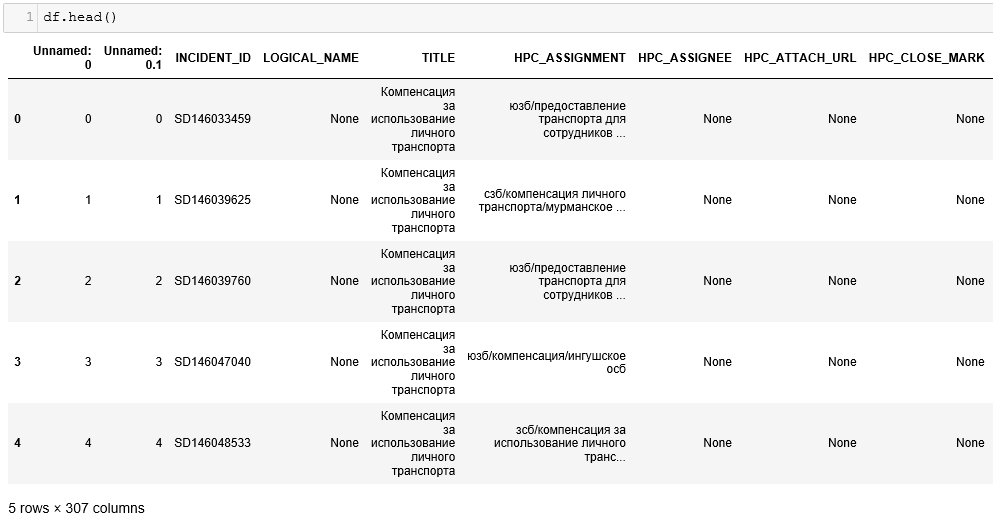
Полная сводка по данным, имеющимся в датасете:
Попробуем обучить нашу модель классификации признаков по первоначальным данным без предварительной «очистки» датасета:
# отделяем целевую переменную «target» от остальных данных для обучения
Class = df['target'].values
df_for_ml = df.drop(['target', 'INCIDENT_ID'], axis=1)
allIndeces = np.arange(len(Class))
# разделяем выборки на обучающую (80%) и тестовую (20%)
numTrain = int(round(0.80*len(Class)))
numTest = len(Class) – numTrain
inTrain = sorted(np.random.choice(allIndeces, size=numTrain, replace=False))
inTest = list(set(allIndeces)-set(inTrain))
train = df_for_ml.iloc[inTrain, :]
test = df_for_ml.iloc[inTest, :]
trainY = Class[inTrain]
testY = Class[inTest]Производим обучение модели:
%%time
model = xgb.XGBClassifier().fit(train, trainY)Обучение модели на неочищенном датасете было произведено за 55,5 секунд:

Первичная выгрузка содержит большое количество избыточных данных, не несущих полезной информации для анализа, к тому же лишняя информация замедляет скорость обучения модели, поэтому в первую очередь необходимо провести исследовательский анализ, чтобы «очистить» наш датасет от таких данных. Обработка такого массива в Excel потребовала бы существенных затрат времени и ресурсов ПК.
Проанализировав методы обработки данных инструментами Python, я обратила внимание на наличие библиотеки «pandas-profiling». Она заинтересовала меня наличием возможностей, которые позволяют:
- выполнять исследовательский анализ данных за короткое время;
- оперативно генерировать интерактивные отчеты в формате HTML.
Чтобы наглядно показать, как это работает, приведу пример отчета, созданного с использованием «pandas-profiling» на примере заявок по транспортному обеспечению.
Итак, для работы с библиотекой импортируем необходимые модули:
import pandas as pd
import pandas_profilingС помощью функции «ProfileReport» модуля «pandas-profiling» формируем отчёт:
report = pandas_profiling.ProfileReport(df)Полученный отчет содержит раздел Overview (Обзор), в котором отражаются основные сведения о данных (количество переменных, количество наблюдений, и т.д.), а также об имеющихся в таблице типах данных:

Кроме того, данный раздел содержит список предупреждений, которые служат подсказками для аналитика, на чём можно сосредоточить усилия при очистке таблицы от данных, не участвующих в анализе.
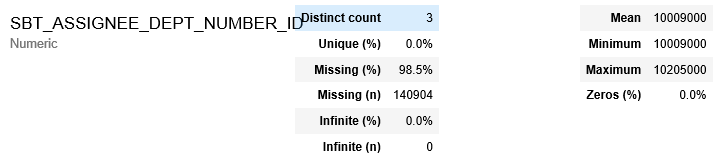
На моем примере видно, что значения с предупреждениями «missing» (пропущено) и «rejected» (отклонено) определены библиотекой как постоянные значения (Constant) и, соответственно, не целесообразны для дальнейшего анализа.
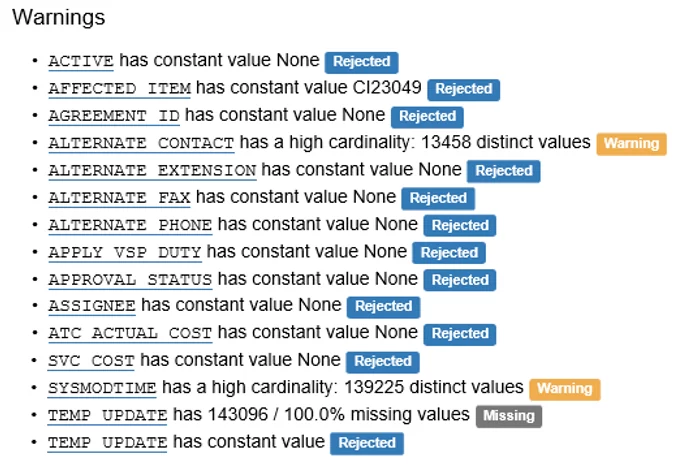
В разделе Variables (Переменные) содержатся полезные сведения о каждом столбце таблицы. При этом, «pandas-profiling» даёт нам несколько полезных индикаторов, таких, как процент и количество пропущенных значений, а также показатели описательной статистики и другие сведения о каждой переменной в исходной таблице.


Из раздела Variables мы видим, что значение в столбце ACTIVE одинаково для каждой заявки таблицы, то есть является константой (Constant). Поскольку такие данные неинформативны для обучения модели, их можно удалить. Для этого можно использовать инструменты Python, что позволит оптимизировать скорость обработки данных.
for_drop_const = list(report.get_description()['variables']\
[report.get_description()['variables']['type'] == 'CONST'].index)
df.drop(for_drop_const, axis=1, inplace=True)Аналогичным способом можно удалить:
-столбцы, имеющие высокую корреляцию с другими столбцами (Higly correlated);

-столбцы, содержащие уникальные значения (Unique);

-столбцы, в которых пропущено (Missing) более 50% значений.
В результате, я получила очищенный датасет, в котором количество столбцов для анализа уменьшилось в 5 раз.

В результате очистки нашего датасета, обучение модели обработанным массивом данных сократилось почти в 3 раза.

При этом не было потери качества обучения:
from sklearn.metrics import classification_report
print(classification_report(testY, model.predict(test)))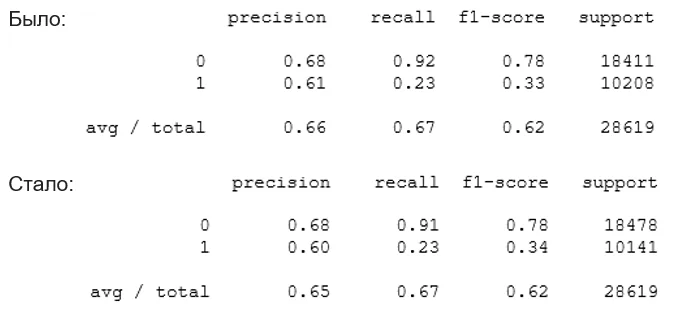
Поэтому, даже если у вас очень огромный датасет, измеряемый миллионами строк и столбцов, всегда перед обучением модели стоит провести его предварительную очистку, что позволит вам значительно сократить время обучения модели.