/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
За всеми архитектурами нейронных сетей уследить сложно, поэтому выбираем одну из самых популярных — Gated recurrent units (GRU). По сути, это разновидность архитектуры LSTM. Они были разработаны для того, чтобы запоминать отдельные зависимости в неких последовательностях (во времени, если брать наш случай). Также они часто используются в задачах анализа текста. GRU была изучена сравнительно недавно в 2014 году в статье “Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling”. (ссылка)
Для данной задачи сформируем некий бейзлайн, который в дальнейшем можно улучшать до бесконечности, но мы разберем только некоторые моменты, чтобы не увеличивать размер данной статьи. Начнем! Данные о курсе Биткоина берем в открытых источниках, допустим, тут (ссылка)
Стоит отметить, что GRU уже реализовано в Keras, поэтому остается только импортировать нужные библиотеки.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense, Dropout, GRU
from keras.optimizers import SGD
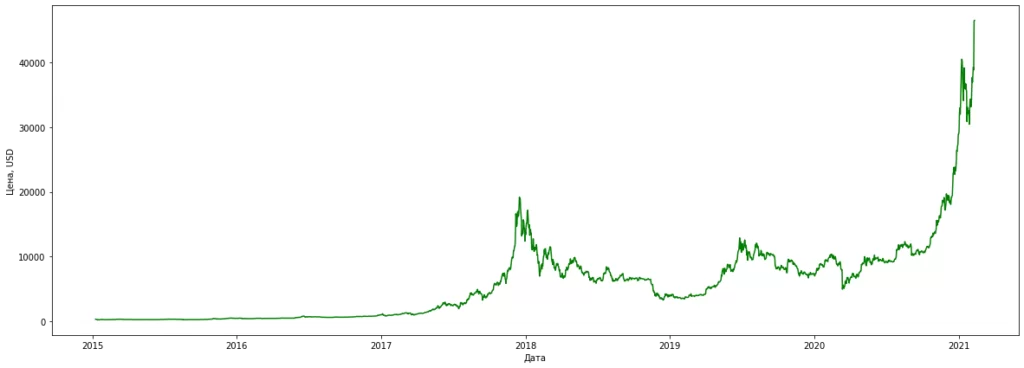
Загружаем наш датасет, приводим дату к Datetime формату, а строковые цены к float, далее строим график зависимости курса биткоина от времени.
df = pd.read_csv('BTC_USD.csv')
df = df[['Дата', 'Цена']]
df['Дата'] = pd.to_datetime(df['Дата'], format = '%d.%m.%Y')
df = df.sort_values('Дата').reset_index(drop=True)
df['Цена'] = df['Цена'].apply(lambda x: x.replace('.', '').split(',')[0])
df['Цена'] = df['Цена'].astype(float)
print(df.shape)
plt.figure(figsize = (20, 7))
plt.plot(df['Дата'], df['Цена'], color = 'g')
plt.xlabel('Дата')
plt.ylabel('Цена, USD')
Разделим данные на тренировочную и тестовую выборку, нормализуем данные в масштабе от 0 до 1.
split_num = 2150
train = df.iloc[:split_num, 1:2]
test = df.iloc[split_num:, 1:2]
scaler = MinMaxScaler(feature_range = (0, 1))
train_scaled = scaler.fit_transform(train)
Пройдемся по временному ряду так называемым “окном” в 2 месяца. То есть наше предсказание будет выдавать курс на 61 день.
X_train = []
y_train = []
window = 60
for i in range(window, split_num):
X_train_ = np.reshape(train_scaled[i - window:i, 0], (window, 1))
X_train.append(X_train_)
y_train.append(train_scaled[i, 0])
X_train = np.stack(X_train)
y_train = np.stack(y_train)
Стоит отметить, что у первого предсказанного дня уже будет какая-то ошибка и даже если она мала, имеет свойство накапливаться. Из этого следует вывод о том, что такие модели хороши для предсказаний на короткий период времени.
Обучим нашу тестовую модель на 1000 эпох, минимизировать будем MSE, от переобучения добавим дропаут, а также установим размер батча равным 16 (если сделать его больше, то прогнозы будут более консервативны и линия предсказания может получиться очень плавной). Keras удобен тем, что мы как конструктор можем последовательно укладывать нужные слои по очереди, а в конце собрать ее в одну нужную модель для дальнейшей работы.
model = Sequential()
model.add(GRU(units = 50, return_sequences = True, input_shape=(X_train.shape[1],1)))
model.add(Dropout(0.2))
model.add(GRU(units = 50, return_sequences = True, input_shape=(X_train.shape[1],1)))
model.add(Dropout(0.2))
model.add(GRU(units = 50, return_sequences = True, input_shape=(X_train.shape[1],1)))
model.add(Dropout(0.2))
model.add(GRU(units = 50))
model.add(Dropout(0.2))
model.add(Dense(units = 1))
model.compile(optimizer = 'sgd', loss = 'mean_squared_error')
model.fit(X_train, y_train, epochs = 1000, batch_size = 16, verbose = 0)
Преобразуем тестовые данные.
df_volume = np.vstack((train, test))
inputs = df_volume[df_volume.shape[0] - test.shape[0] - window:]
inputs = inputs.reshape(-1,1)
inputs = scaler.transform(inputs)
num_2 = df_volume.shape[0] - split_num + window
X_test = []
for i in range(window, num_2):
X_test_ = np.reshape(inputs[i-window:i, 0], (window, 1))
X_test.append(X_test_)
X_test = np.stack(X_test)
Далее сделаем свои предсказания и построим график на последние пару месяцев.
predict = model.predict(X_test)
predict = scaler.inverse_transform(predict)
plt.figure(figsize = (20, 7))
plt.plot(df['Дата'][2000:], df_volume[2000:], color = 'g', label = 'Real')
plt.plot(df['Дата'][-predict.shape[0]:].values, predict, color = 'r', label = 'Predicted')
plt.xlabel('Дата')
plt.ylabel('Цена, USD')
plt.legend()
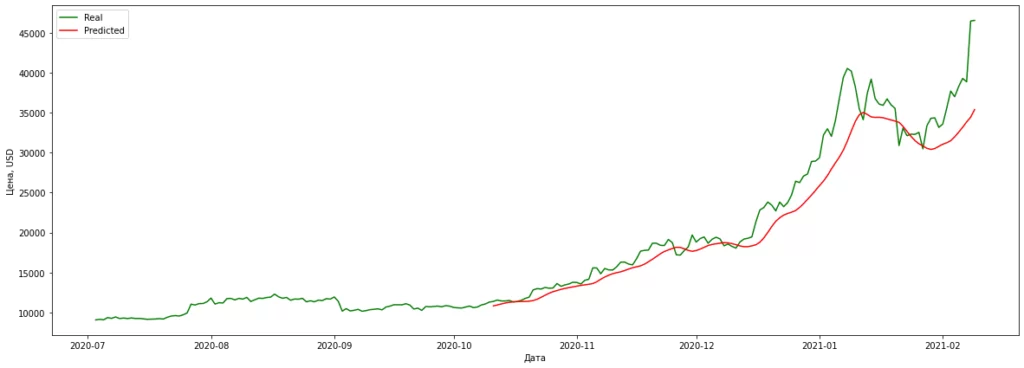
Наша бейзлайн модель довольно точно описывает тренды, но получилась достаточно гладкой, без явных скачков. Повторим действия аналогичные предыдущим и попробуем предсказать курс хотя бы на 3 недели.
pred_ = predict[-1].copy()
prediction_full = []
window = 60
df_copy = df.iloc[:, 1:2][1:].values
for j in range(20):
df_ = np.vstack((df_copy, pred_))
train_ = df_[:split_num]
test_ = df_[split_num:]
df_volume_ = np.vstack((train_, test_))
inputs_ = df_volume_[df_volume_.shape[0] - test_.shape[0] - window:]
inputs_ = inputs_.reshape(-1,1)
inputs_ = scaler.transform(inputs_)
X_test_2 = []
for k in range(window, num_2):
X_test_3 = np.reshape(inputs_[k - window:k, 0], (window, 1))
X_test_2.append(X_test_3)
X_test_ = np.stack(X_test_2)
predict_ = model.predict(X_test_)
pred_ = scaler.inverse_transform(predict_)
prediction_full.append(pred_[-1][0])
df_copy = df_[j:]
prediction_full_new = np.vstack((predict, np.array(prediction_full).reshape(-1,1)))
df_date = df[['Дата']]
for h in range(20):
kk = pd.to_datetime(df_date['Дата'].iloc[-1]) + pd.DateOffset(days=1)
kk = pd.DataFrame([kk.strftime("%Y-%m-%d")], columns = ['Дата'])
df_date = df_date.append(kk)
df_date = df_date.reset_index(drop = True)
df_date['Дата'] = pd.to_datetime(df_date['Дата'])
Нарисуем финальный график.
plt.figure(figsize = (20,7))
plt.plot(df['Дата'][2000:], df_volume[2000:], color = 'red', label = 'Real')
plt.plot(df_date['Дата'][-prediction_full_new.shape[0]:].values, prediction_full_new, color = 'blue', label = 'Predicted')
plt.xlabel('Дата')
plt.ylabel('Цена, USD')
plt.legend()
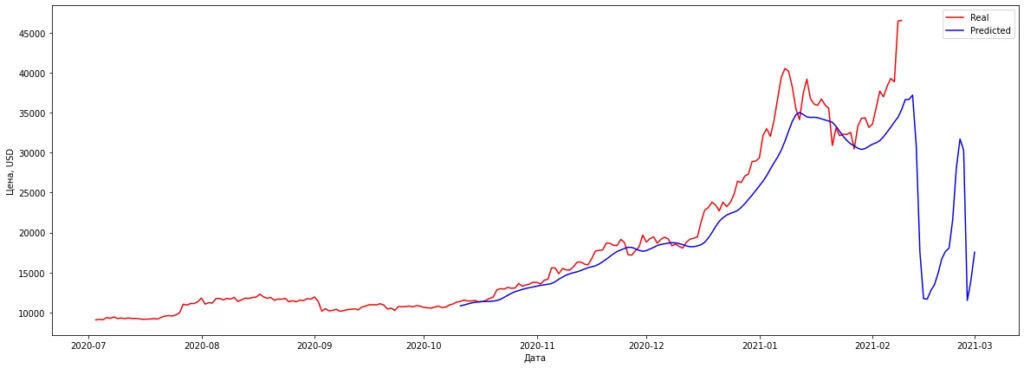
Наша модель предсказывает нам падение курса биткоина до уровня 2019 года. В данной статье мы получили некий бейзлайн для задачи прогнозирования временных рядов, для ее улучшения нужно экспериментировать с архитектурой сети, различными гиперпараметрами, как самой сети, так и некими переменными для времени (ширина окна, количество дней для предсказания).