/img/star (2).png.webp)



/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Для своего исследования мы выбрали процесс взаимодействия внутреннего аудита с управлением рисками. Нам интересно было понять — насколько своевременно и качественно организован обмен данными между подразделениями, требует ли процесс оптимизации и если да, то какие шаги мы должны для этого предпринять. Анализировать процесс мы решили с использованием методологии Process Mining. Все действия с данными проводились с помощью Python и библиотеки Pm4py.
Когда мы попытались собрать информацию о фактической работе процесса, то столкнулись с тем, что в автоматизированных системах недостаточно данных.
Какими данными мы обладали на начальном этапе?
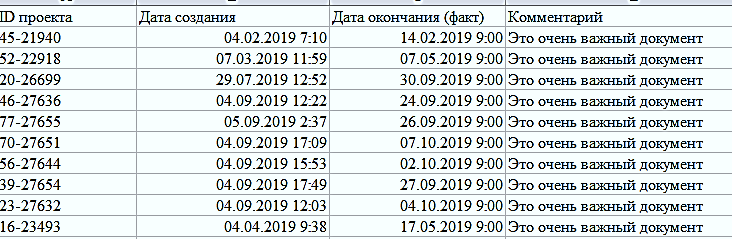
1.Информация из системы электронного документооборота.
В ней отражались название документа и фактические даты ввода/валидации/завершения документа. Пример таблицы приведен ниже.
2.Информация из аналога Service Desk.
Мы точно знали, что сотрудник, после проведения документа через систему электронного документооборота, должен завести заявку в Service Desk для отправки в управление рисков.
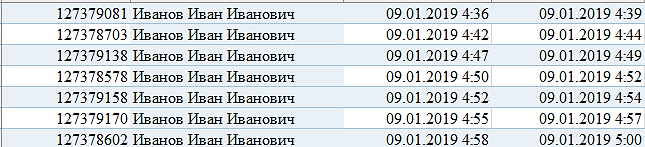
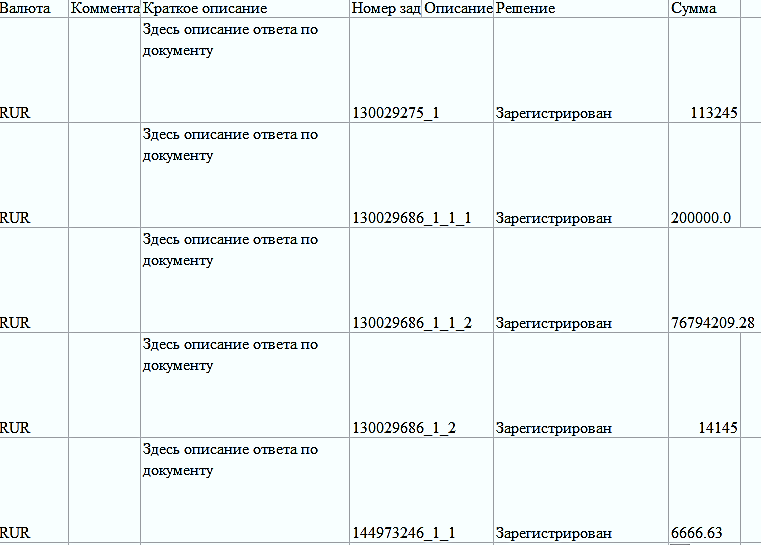
3.Информация из отчетов по заявкам в Service Desk.
Направлялись аудиторам по почте.
Все имеющиеся данные мы преобразовали в первый этап процесса, то есть фактически мы рассмотрели начальный путь документа с момента его заведения до внесения информации в Service Desk.
На данном этапе мы столкнулись с первым препятствием — в базе отсутствовало поле, связывающее систему документооборота с Service Desk. Проверили комментарии к заявке, и обнаружили, что в поле есть необходимый нам идентификатор. Далее — написали короткий Код, позволяющий с использованием регулярного выражения получить из текста информацию.
В процессе работы кода выяснилось, что некоторые сотрудники неверно вносят информацию в комментарии к заявке, из-за этого у нас возникли трудности при объединении данных по идентификатору. Зафиксировали как проблему, и удалили данные с ошибками из основной выборки.
import re
def searchSD(string):
parser = re.search(r'\d{2}\S\d{5}',string)
try:
return parser[0]
except TypeError:
return 'Not Found'
ServiceDesk_copy = ServiceDesk.copy()
asDrug_copy[‘Номер заявки в Service Desk'] = asDrug_copy.apply(lambda x: searchSD(x['DESCRIPTION']), axis=1)
Для выделения этапов заведения и завершения документа мы разделили столбцы по датам и присвоили новое значение, затем соединили их в единый dataframe.
С помощью PM4PY построили граф этих четырех этапов нашего процесса. Что мы увидели интересного?
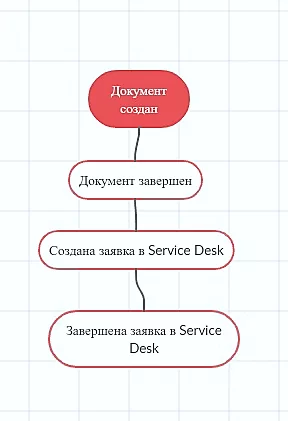
С точки зрения анализа для нас было интересно: среднее время между открытием и завершением заявки – 5 минут. Это очень сильно выделялось в разрезе остальных этапов, поэтому мы зафиксировали данный факт, как гипотезу. Далее мы объясним, почему так произошло.
На следующем этапе анализа мы столкнулись с другой проблемой. Информации из автоматизированных систем больше не было. Мы уточнили у коллег, как дальше строится процесс. В итоге выяснилось, что сотрудники управления рисков, исполняя заявку из Service Desk, выгружают себе документы и закрывают заявку. Весь дальнейший процесс общения с аудитом происходит посредством переписки в корпоративной почте. После рассмотрения представленных аудитом материалов сотрудники управления рисками присылают по почте отчет в формате xlsx на создателя заявки в Service Desk. Именно это и есть ответ на нашу гипотезу про завершение заявки в течении 5 минут.
Для понимания следующих этапов процесса мы попросили наших коллег предоставить нам переписку с управлением рисков. Примеры писем приведены ниже.
Изучив текст писем, мы подумали – что если, используя тексты писем и подходы NLP, преобразовать их в этапы процесса?
Для обработки переписки мы использовали библиотеку ExtractMSG. Библиотека позволила нам получить из файлов Outlook типа .msg всю необходимую информацию.
for files in os.listdir('./'):
print([files])
fileExtension = files.split('.')[-1]
if(fileExtension == 'msg'):
#обработка исключения, если письмо неправильно сохранено и не имеет атрибутов
try:
msg = extract_msg.Message(files)
except AttributeError:
msg = 0
try:
messageTo = processEmail(msg.to)
except AttributeError:
msg = 0
#если письмо сохранено правильно, то обрабатываем данные в нем
if msg!=0:
sd=msg.subject[msg.subject.find('SD'):]
if sd==' ' or len(sd)<=1:
sd=msg.subject[msg.subject.find('EVE-'):]
if len(sd)<=1:
sd=msg.subject
messageSubject = msg.subject
messageDate = msg.date
messageTo = processEmail(msg.to)
messageBody = msg.body
time_zona=msg.date[msg.date.find('+') : ]
#msg_to=msg.sender.split('<',1)
#sender=msg.sender.split('<',1)
msd_body=msg.body.split('From:',1)
#сохранить вложения)
#for x in msg.attachments:
# x.save()
if msd_body[0]!=' \r\n\r\n \r\n\r\n':
if msd_body[0]!='____________________________\r\n\r\nCообщение зашифровано\r\n\r\n____________________________\r\n\r\n':
mas_mail.append([str(sd),str(msg.date),str(msg.subject),str(msd_body[0]),check_mail(msg.sender),check_mail(msg.to)])
if(check_child(msg.body,time_zona)!='0'):
mas_mail.append(check_child(msg.body,time_zona))
i+=1
mas_time.append(str(msg.date))
Далее, перепроверив данные, оказалось, что в 50% случаев сотрудники отвечали на входящее сообщение, и у нас в текст письма попадала вся переписка. На этом этапе мы написали небольшой парсер, который несмотря на наличие текста, делит письмо на отдельные элементы.
После того, как все письма были разделены по отдельности, мы выделили из них идентификатор заявки в Service Desk. Он понадобился нам для дальнейшего объединения данных в единый Лог.
На следующем этапе нам нужно было преобразовать письма в этапы процесса. Так как самих писем было много, делать это ручным способом было неэффективно. Для реализации данной идеи были использованы подходы NLP в части мультиклассовой классификации текста. В качестве решения за основу была взята статья — ссылка.
Для обучающей выборки мы разметили письма на 6 классов и обучили классификатор. Сами классы представлены ниже. Точность работы алгоритма по метрике F1 – 0.92. Для нашей задачи — это хороший результат!

На финальном этапе мы связали переписку с отчетом по приему документов (по номеру заявки из Service Desk) и вставили эти данные в лог с перепиской. Получение от управления рисков отчета по заявке является завершением исследуемого процесса.

Соединив таблицы в единый лог, мы увидели, что получилось. Визуализацию графа мы сделали в pm4py, с использованием эвристического майнера.
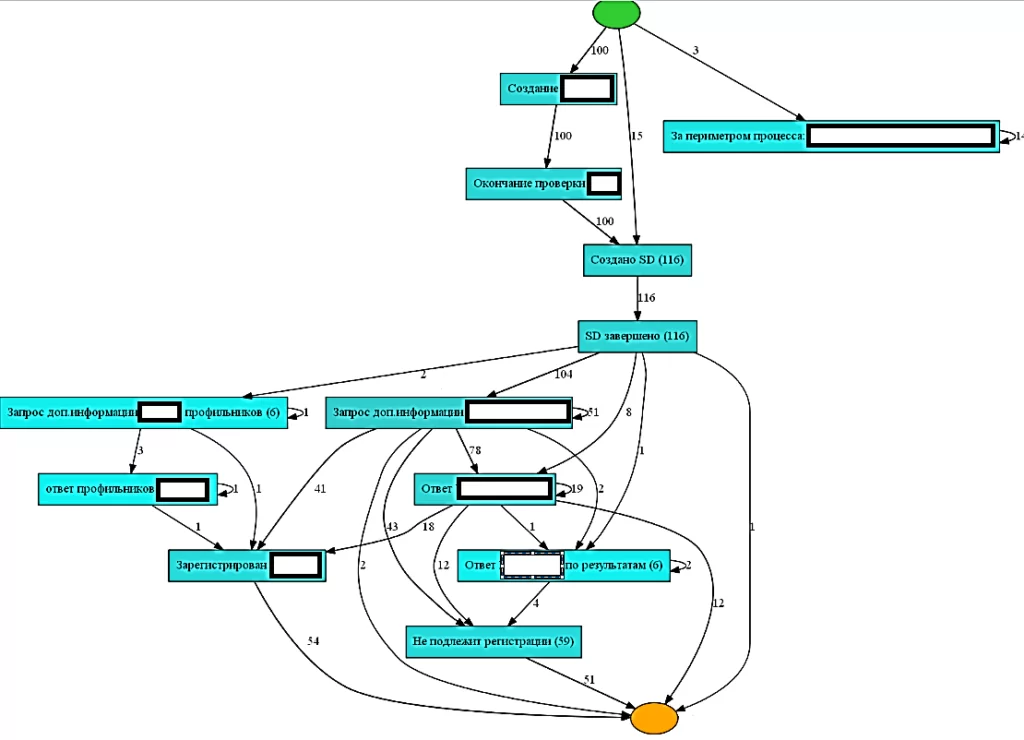
Итак, использование методов NLP и Process mining помогло нам воссоздать полную картину процесса. По результатам анализа модели процесса «AS IS» были установлены «узкие места» и отклонения, принято решение об оптимизации процесса.
В ходе нашего исследования мы убедились, что отсутствие логов не является стоп-фактором для использования методов Process Мining. Главное понять какие данные необходимы для анализа процесса и определить с помощью каких дополнительных технологий мы можем их превратить в модель для анализа.