/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Порой, полученные графы необходимо передать профильному специалисту, на компьютере которого нет специализированных программ для просмотра (python, graphviz, proM и т.д), в связи с чем встал вопрос о разработке приложения, поддерживающего методы Process Mining и работающем для просмотра и взаимодействия с полученными графами на любом компьютере. Решение – написать веб-приложение. Лог файл методами Process Mining будет обрабатываться на компьютере IT-специалиста с помощью python, а вот в построении графа процесса нам поможет Дракула! Но не спешите нести осиновые колья, это всего лишь javascript библиотека!
Для визуализации графа процесса необходимо предварительно извлечь необходимую информацию из предоставленных логов, а также обогатить её новыми данными (количеством переходов между событиями, средним временем и т.д).
В начале работы импортируем необходимую для обработки табличных данных библиотеку Pandas:
import pandas as pdСчитаем данные из нашего excel-файла, указав имя листа для чтения и требуемую кодировку (указание кодировки не является обязательным, но поможет избежать проблем с отображением информации в дальнейшем):
df = pd.read_excel('log.xlsx', sheet_name='data', encoding='utf-8')
df.head()
Далее необходимо отсортировать данные нашего лог-файла по id случая и дате событий для каждого из id (так же необходимо найти список уникальных id, для дальнейшей работы):
sort_df = df.sort_values(['case_id','data'], ascending=True)
unique_ids = sort_df['case_id'].unique().tolist()
Далее сформирмируем из наших данных цепочки событий, как показано на рисунке ниже:

dict_df = {'case_id':[],'event_1':[],'event_2':[],'time_delta':[]}
for unique_id in unique_ids:
sort = sort_df[sort_df['case_id'].isin([unique_id])]
events = sort['event'].values
dates = sort['data'].values
dict_df['case_id'].append(unique_id)
dict_df['event_1'].append("начало процесса")
dict_df['event_2'].append(events[0])
dict_df['time_delta'].append(pd.Timedelta(dates[0]-dates[0]).total_seconds())
for i, event in enumerate(events[:-1]):
dict_df['case_id'].append(unique_id)
dict_df['event_1'].append(event)
dict_df['event_2'].append(events[i+1])
dict_df['time_delta'].append(pd.Timedelta(dates[i+1]-dates[i]).total_seconds())
dict_df['case_id'].append(unique_id)
dict_df['event_1'].append(events[-1])
dict_df['event_2'].append("конец процесса")
dict_df['time_delta'].append(pd.Timedelta(dates[-1]-dates[-1]).total_seconds())
new_df = pd.DataFrame.from_dict(dict_df)
Для дальнейшей работы необходимо сформировать список уникальных цепочек событий, применив метод drop_duplicates, в качестве уникальных значений для subset указав первое и второе событие.
dup = new_df.drop_duplicates(subset = ['event_1','event_2'])Далее, определим количество переходов между нашими событиями:
rows_df = new_df.groupby(['event_1','event_2']).size().reset_index(name="rows_count")
rows_df.head()
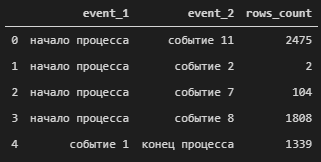
Так же при анализе графов событий, довольно часто необходимо узнать среднюю продолжительность времени, прошедшего между двумя действиями, для чего необходимо запустить следующий код:
def to_days(s):
return s/86400
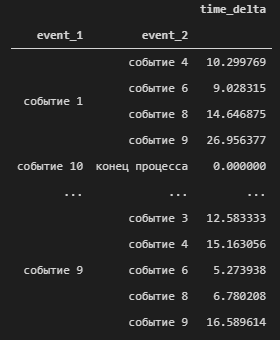
mean_time = new_df.groupby(['event_1','event_2'])[['time_delta']].mean()
mean_time['time_delta'] = mean_time['time_delta'].apply(to_days)
mean_time.head()
С помощью метода apply мы можем применить указанную функцию to_days, к элементам из указанного столбца (в данном случае преобразуем данные столбца time_delta из секунд в дни).
Сформируем итоговый DataFrame объединив все наши данные с помощью метода merge, в качестве ключей для объединения будем использовать наши «цепочки».
res_df=pd.merge(pd.merge(dup,rows_df,on=['event_1','event_2']), mean_time,on=['event_1','event_2'])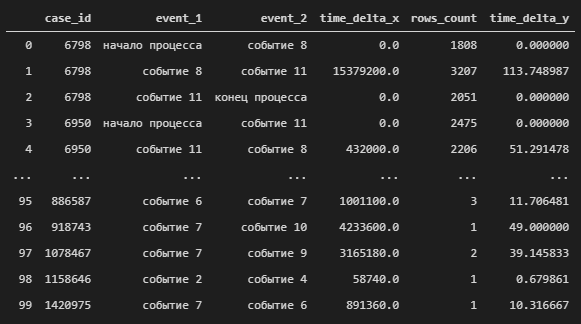
Из полученного DataFrame формируем js-файл с двумя переменными:
json1 – список из событий, которые будут использоваться для рисования графа.
json2 – полная информация о цепочках событий.
json1, json2 = {},{}
json1['events'] = df['event'].unique().tolist()
json2['events'] = []
for index, row in res_df.iterrows():
obj = {}
obj['case_id'] = row['case_id']
obj['event1'] = row['event_1']
obj['event2'] = row['event_2']
obj['count_edges'] = row['rows_count']
obj['mean_time'] = row['time_delta_y']
json2['events'].append(obj)
json_file = open('events.js', 'w', encoding='utf-8')
json_file.write('json1={0}\njson2={1}'.format(str(json1),str(json2)))
json_file.close()
Итоговый js-файл будет содержать переменные:

Далее, полученный js-файл будет использоваться для построения графа в будущем веб-приложении. Приступим к этапу работы с Dracula.
Dracula.js – это набор инструментов для отображения и компоновки интерактивных связанных графов и сетей, а также различных связанных алгоритмов из области теории графов. Название библиотеки навеяно игрой слов – Граф Дракула (Dracula Graph Library).
Cоздадим html-файл со структурой, указанной ниже:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<script type="text/javascript" src="js/raphael-min.js"></script>
<script type="text/javascript" src="js/dracula_graffle.js"></script>
<script type="text/javascript" src="js/dracula_graph.js"></script>
<script type="text/javascript" src="events.js"></script>
<script type="text/javascript" src="graph_maker.js"></script>
<style>
#canvas{
border-width:2px;
border-color:black;
border-style:solid;
}
</style>
</header>
<body>
<div id="canvas"></div>
<button id="redraw" onclick="redraw();">redraw</button>
</body>
Методы, необходимые для формирования графа и его отображения на рабочей области, будут храниться в файле graph_maker.js.
var redraw;
/*
Для отрисовки графа задаём функцию, которая будет выполняться при загрузке страницы в браузере (window.onload)
*/
window.onload = function() {
/*
Ширина и высота рабочей области в этом примере задается исходя из ширины и высоты страницы в браузере.
*/
width=document.body.clientWidth;
height=document.body.clientHeight;
//Инициализируем объект будущего графа
var g = new Graph();
//Задаем функцию отрисовки
var renderer = function(r, n) {
var set = r.set().push(
*/r.rect задает свойства прямоугольной области, в которой будет храниться информация о событии (размер, текст внутри области, цвет заливки и т.д).
r.rect(n.point[0]-100, n.point[1]-13, 200, 40).attr({"fill": "#fa8", "stroke-width": 2, r : "9px"})).push(
r.text(n.point[0], n.point[1] + 10, n.label).attr({"font-size":"10px"}));
set.items.forEach(function(el) {el.tooltip(r.set().push(r.rect(0, 0, 70, 70).attr({"fill": "#fec", "stroke-width": 1, r : "9px"})))});
return set; };
В цикле перебираем элементы из списка json1 и создаём вершины нашего графа, используя функцию addNode
for (var i=0; i<json1['events'].length; i++){
event = json1['events'][i];
g.addNode(event, {label:event, render:renderer});}
Перебираем элементы из переменной json2, соединяем ребрами вершины графа, согласно цепочкам событий и указываем информацию о них (количество переходов, среднее время переходов)
for (var j=0; j<json2['events'].length; j++)
{
event1 = json2['events'][j]['event1'];
event2 = json2['events'][j]['event2'];
mean_time = json2['events'][j]['mean_time'];
count_edges = json2['events'][j]['count_edges'];
g.addEdge(event1, event2, { stroke : "#bfa" , fill : "#56f", directed : true, label : count_edges});
}
Инициализируем рабочую область, на которой будет нарисован наш граф и задаём для нее параметры
var layouter = new Graph.Layout.Spring(g);
layouter.layout();
var renderer = new Graph.Renderer.Raphael('canvas', g, width, height);
renderer.draw();
redraw = function() {
layouter.layout();
renderer.draw();
};};
Открыв наш html-файл в браузере, мы сможем увидеть результат:
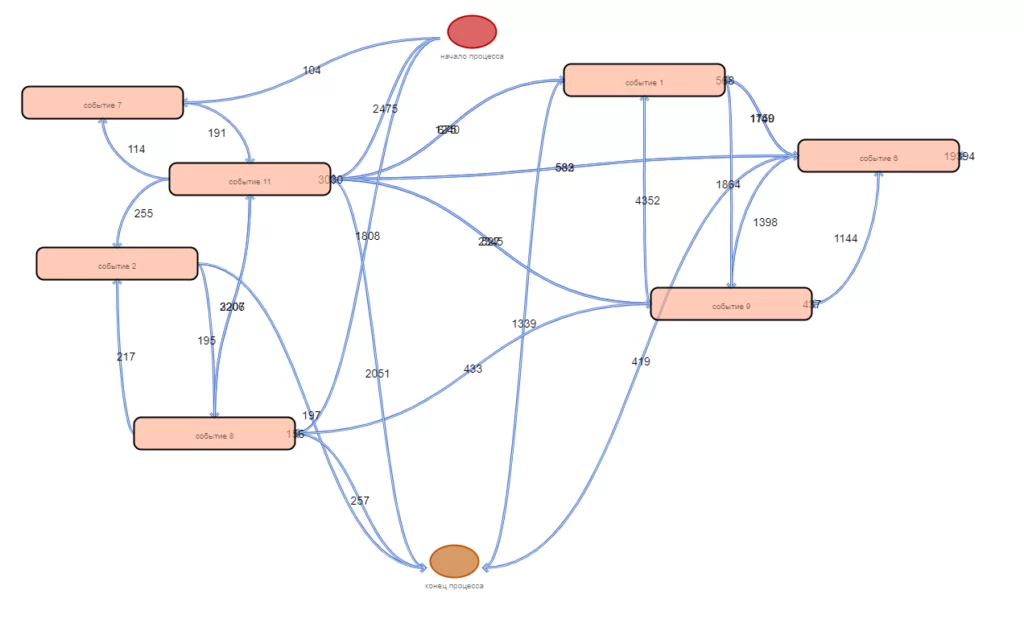
Стоит отметить, что изображенные на холсте объекты поддерживают технологию «Drag-and-drop», что позволяет изменять вид полученного графа в реальном времени. Также код в файле graph_maker.js может быть изменён в зависимости от требований к представлению процесса, при этом формирование нового графа будет произведено сразу после обновления страницы браузера.
В итоге у нас получилось разработать приложение, после работы которого может быть сформирован набор скриптов, которые можно переслать профильному сотруднику для просмотра и анализа, не задумываясь о средствах просмотра на его компьютере.