/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Построить граф по логам процесса очень просто. В распоряжении аналитиков в настоящее время достаточное многообразие профессиональных разработок, таких как Celonis, Disco, PM4PY, ProM и т.д., призванных облегчить исследование процессов. Сложнее найти отклонения на графах, сделать верные выводы по ним. Что делать, если некоторые профессиональные разработки, зарекомендовавшие себя и представляющие особый интерес не доступны по тем или иным причинам, или вам хочется больше свободы в расчетах при работе с графами? Насколько сложно самим написать майнер и реализовать некоторые необходимые возможности для работы с графами? Сделаем это на практике с помощью стандартных библиотек Python, реализуем расчеты и дадим с их помощью ответы на детальные вопросы, которые могли бы заинтересовать владельцев процесса.
Перед построением графа, необходимо выполнить расчеты. Собственно расчет графа и будет тем самым майнером, о котором говорилось ранее. Для выполнения расчета необходимо собрать знания о событиях — вершинах графа и связях между ними и записать их, например в справочники. Заполняются справочники с помощью процедуры расчета calc (см. код по ссылке). Заполненные справочники передаются в качестве параметров процедуре отрисовки графов draw (см. код по ссылке выше). Эта процедура форматирует данные, в представленный ниже вид:
digraph f {"Permit SUBMITTED by EMPLOYEE (6255)" -> "Permit APPROVED by ADMINISTRATION (4839)" [label=4829 color=black penwidth=4.723857205400346]
"Permit SUBMITTED by EMPLOYEE (6255)" -> "Permit REJECTED by ADMINISTRATION (83)" [label=83 color=pink2 penwidth=2.9590780923760738]
"Permit SUBMITTED by EMPLOYEE (6255)" -> "Permit REJECTED by EMPLOYEE (231)" [label=2 color=pink2 penwidth=1.3410299956639813]
…
start [color=blue shape=diamond]
end [color=blue shape=diamond]}и передает его для отрисовки графическому движку Graphviz. Примеры отрисованных графов ниже.
Приступим к построению и исследованию графов с помощью реализованного майнера. Будем повторять процедуры чтения и сортировки данных, расчета и отрисовки графов, как в приведенных ниже примерах. Для примеров взяты логи событий по международным декларациям из соревнования BPIC2020. Ссылка на соревнование.
Считаем данные из лога, отсортируем их по дате и времени. Предварительно формат .xes преобразован в .xlsx. Процесс конвертации оcвещен ранее на NewTechAudit.
df_full = pd.read_excel('InternationalDeclarations.xlsx')
df_full = df_full[['id-trace','concept:name','time:timestamp']]
df_full.columns = ['case:concept:name', 'concept:name', 'time:timestamp']
df_full['time:timestamp'] = pd.to_datetime(df_full['time:timestamp'])
df_full = df_full.sort_values(['case:concept:name','time:timestamp'], ascending=[True,True])
df_full = df_full.reset_index(drop=True)Выполним расчет графа.
dict_tuple_full = calc(df_full)Выполним отрисовку графа.
draw(dict_tuple_full,'InternationalDeclarations_full') После выполнения процедур получим граф процесса:
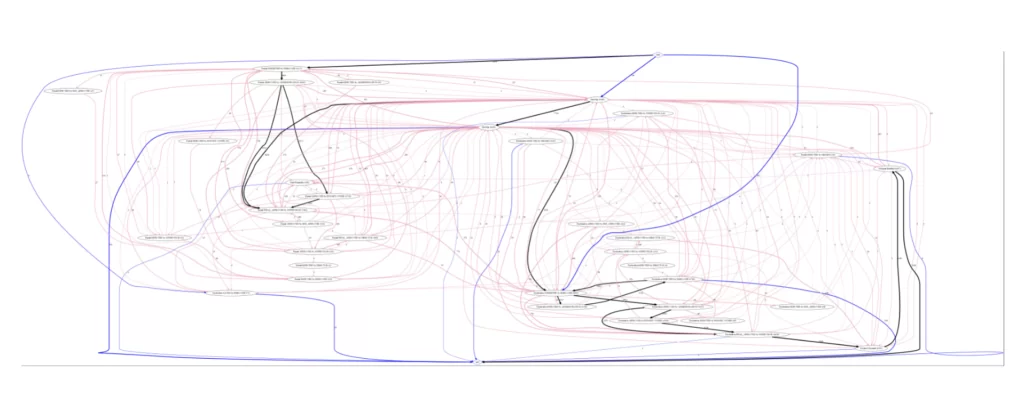
Так как полученный граф не читаем, упростим его.
Есть несколько подходов к улучшению читаемости или упрощению графа:
- использовать фильтрацию по весам вершин или связей;
- избавиться от шума;
- сгруппировать события по схожести названия.
Применим 3 подход.
Создадим словарь объединения событий:
_dict = {'Permit SUBMITTED by EMPLOYEE': 'Permit SUBMITTED',
'Permit APPROVED by ADMINISTRATION': 'Permit APPROVED',
'Permit APPROVED by BUDGET OWNER': 'Permit APPROVED',
'Permit APPROVED by PRE_APPROVER': 'Permit APPROVED',
'Permit APPROVED by SUPERVISOR': 'Permit APPROVED',
'Permit FINAL_APPROVED by DIRECTOR': 'Permit FINAL_APPROVED',
'Permit FINAL_APPROVED by SUPERVISOR': 'Permit FINAL_APPROVED',
'Start trip': 'Start trip',
'End trip': 'End trip',
'Permit REJECTED by ADMINISTRATION': 'Permit REJECTED',
'Permit REJECTED by BUDGET OWNER': 'Permit REJECTED',
'Permit REJECTED by DIRECTOR': 'Permit REJECTED',
'Permit REJECTED by EMPLOYEE': 'Permit REJECTED',
'Permit REJECTED by MISSING': 'Permit REJECTED',
'Permit REJECTED by PRE_APPROVER': 'Permit REJECTED',
'Permit REJECTED by SUPERVISOR': 'Permit REJECTED',
'Declaration SUBMITTED by EMPLOYEE': 'Declaration SUBMITTED',
'Declaration SAVED by EMPLOYEE': 'Declaration SAVED',
'Declaration APPROVED by ADMINISTRATION': 'Declaration APPROVED',
'Declaration APPROVED by BUDGET OWNER': 'Declaration APPROVED',
'Declaration APPROVED by PRE_APPROVER': 'Declaration APPROVED',
'Declaration APPROVED by SUPERVISOR': 'Declaration APPROVED',
'Declaration FINAL_APPROVED by DIRECTOR': 'Declaration FINAL_APPROVED',
'Declaration FINAL_APPROVED by SUPERVISOR': 'Declaration FINAL_APPROVED',
'Declaration REJECTED by ADMINISTRATION': 'Declaration REJECTED',
'Declaration REJECTED by BUDGET OWNER': 'Declaration REJECTED',
'Declaration REJECTED by DIRECTOR': 'Declaration REJECTED',
'Declaration REJECTED by EMPLOYEE': 'Declaration REJECTED',
'Declaration REJECTED by MISSING': 'Declaration REJECTED',
'Declaration REJECTED by PRE_APPROVER': 'Declaration REJECTED',
'Declaration REJECTED by SUPERVISOR': 'Declaration REJECTED',
'Request Payment': 'Request Payment',
'Payment Handled': 'Payment Handled',
'Send Reminder': 'Send Reminder'}Выполним группировку событий и отрисуем граф процесса еще раз.
df_full_gr = df_full.copy()
df_full_gr['concept:name'] = df_full_gr['concept:name'].map(_dict)
dict_tuple_full_gr = calc(df_full_gr)
draw(dict_tuple_full_gr,'InternationalDeclarations_full_gr')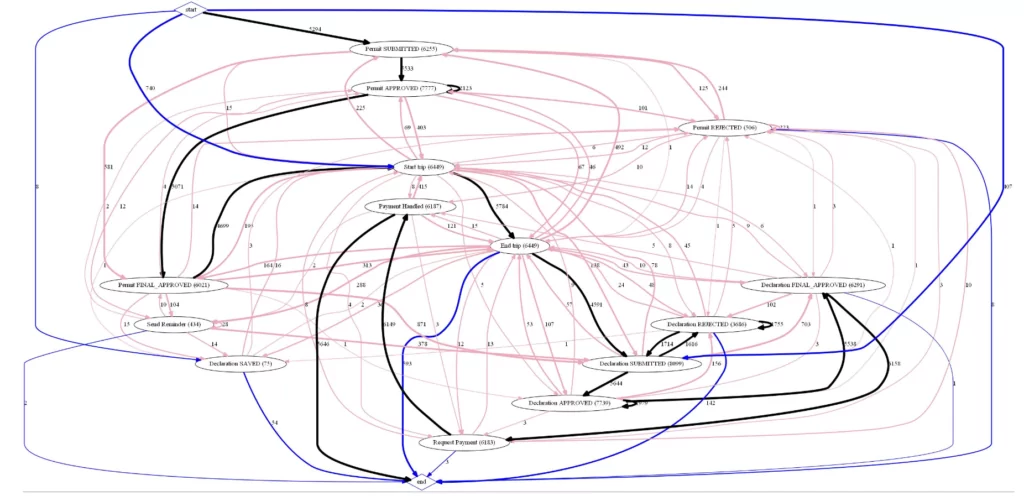
После группировки событий по схожести названия читаемость графа улучшилась. Попробуем найти ответы на вопросы. Ссылка на список вопросов. Например, скольким декларациям не предшествовало предодобренное разрешение?
Для ответа на поставленный вопрос отфильтруем граф по интересующим событиям и отрисуем граф процесса еще раз.
df_full_gr_f = df_full_gr[df_full_gr['concept:name'].isin(['Permit SUBMITTED',
'Permit APPROVED',
'Permit FINAL_APPROVED',
'Declaration FINAL_APPROVED',
'Declaration APPROVED'])]
df_full_gr_f = df_full_gr_f.reset_index(drop=True)
dict_tuple_full_gr_f = calc(df_full_gr_f)
draw(dict_tuple_full_gr_f,'InternationalDeclarations_full_gr_isin')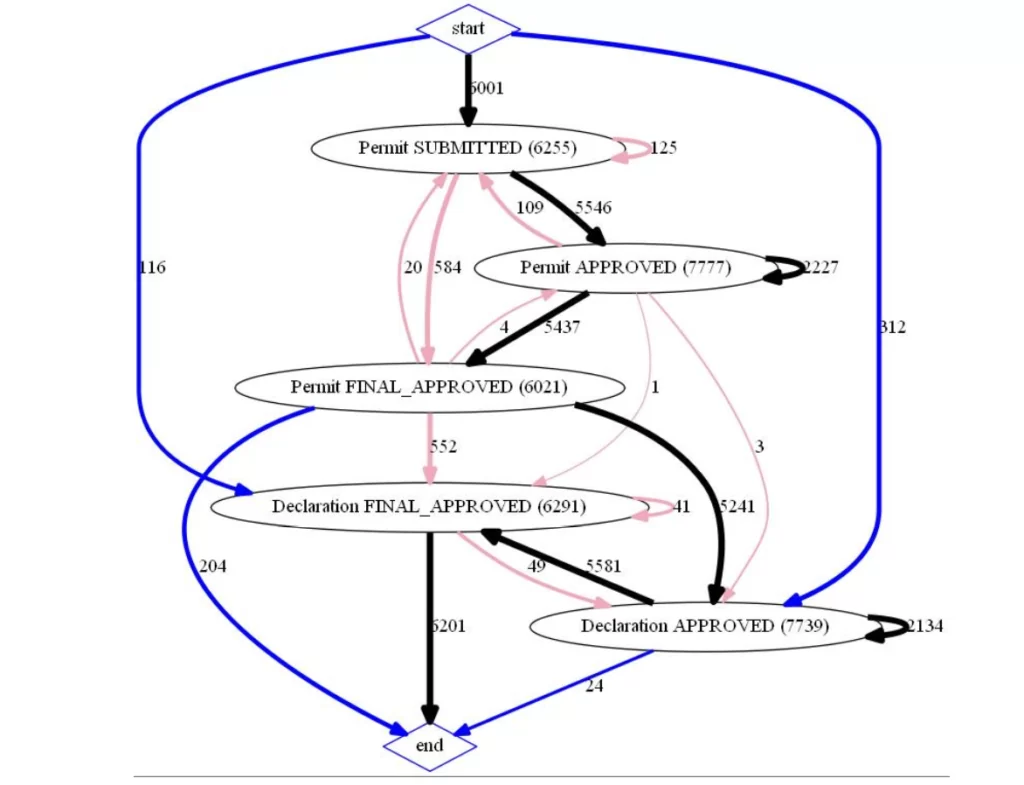
С помощью полученного графа мы легко сможем дать ответ на поставленный вопрос – 116 и 312 декларациям не предшествовало предодобренное разрешение.
Можно дополнительно “провалиться” (отфильтровать по ‘case:concept:name’, участвующих в нужной связи) за связи 116 и 312 и убедиться, что на графах будут отсутствовать события, связанные с разрешениями.
“Провалимся” за связь 116:
df_116 = df_full_gr_f[df_full_gr_f['case:concept:name'].isin(d_case_start2['Declaration FINAL_APPROVED'])]
df_116 = df_116.reset_index(drop=True)
dict_tuple_116 = calc(df_116)
draw(dict_tuple_116,'InternationalDeclarations_full_gr_isin_116')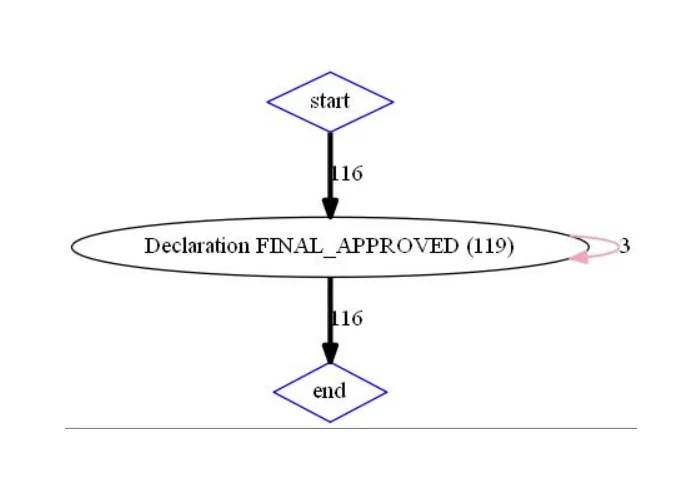
“Провалимся” за связь 312:
df_312 = df_full_gr_f[df_full_gr_f['case:concept:name'].isin(d_case_start2['Declaration APPROVED'])]
df_312 = df_312.reset_index(drop=True)
dict_tuple_312 = calc(df_312)
draw(dict_tuple_312,'InternationalDeclarations_full_gr_isin_312')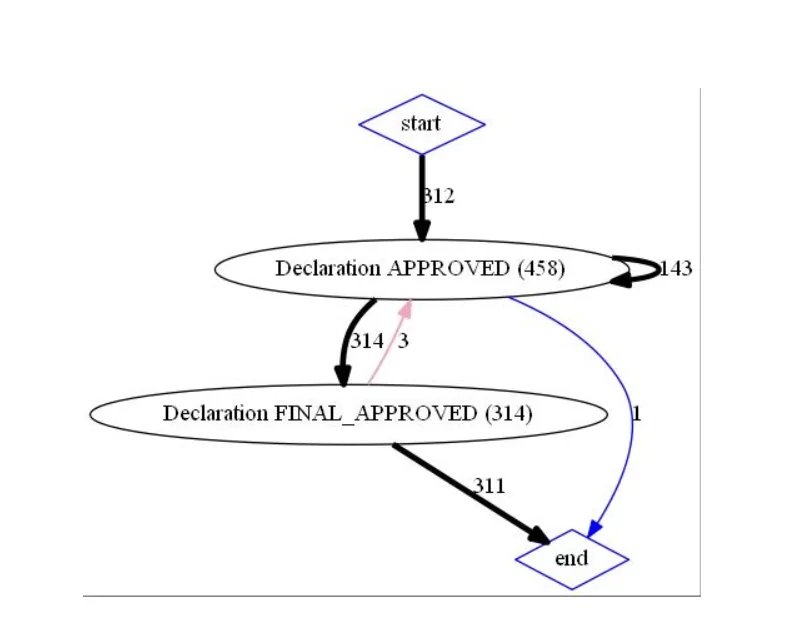
Так как на полученных графах полностью отсутствуют события, связанные с разрешениями, корректность ответов 116 и 312 подтверждается.
Как видим, написать майнер и реализовать необходимые возможности для работы с графами не сложная задача, с которой успешно справились встроенные функции Python и Graphviz в качестве графического движка.