/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 4 мин.
Одной из главных проблем современной информации является разнообразие данных.
Давайте представим, что в вашей компании есть огромная база данных, хранящая сотни миллионов обращений сотрудников и клиентов, любой текст, написанный людьми на русском или любом другом языке. Эти обращения могут относиться к техническим процессам, к оказываемым услугам и к внутренним структурным процессам и т.д. Назовем это все бизнес-процессами. Итак, таким образом, у нас в руках огромный источник информации рефлекторного характера, отражающий состояние функционирования всех систем компании. Но данных настолько много, что человеческий мозг не сможет за короткий срок все это обработать и оценить. Что же делать?
На помощь приходит такая технология как NLP (анализ естественного языка), которая имеет возможность разобрать и упорядочить этот хаос слов и эмоций человека. Однажды, перед нами стояла задача обработать и структурировать более 10 млн. записей и выявить при помощи технологий Data Science отклонения в бизнес-процессах компании.
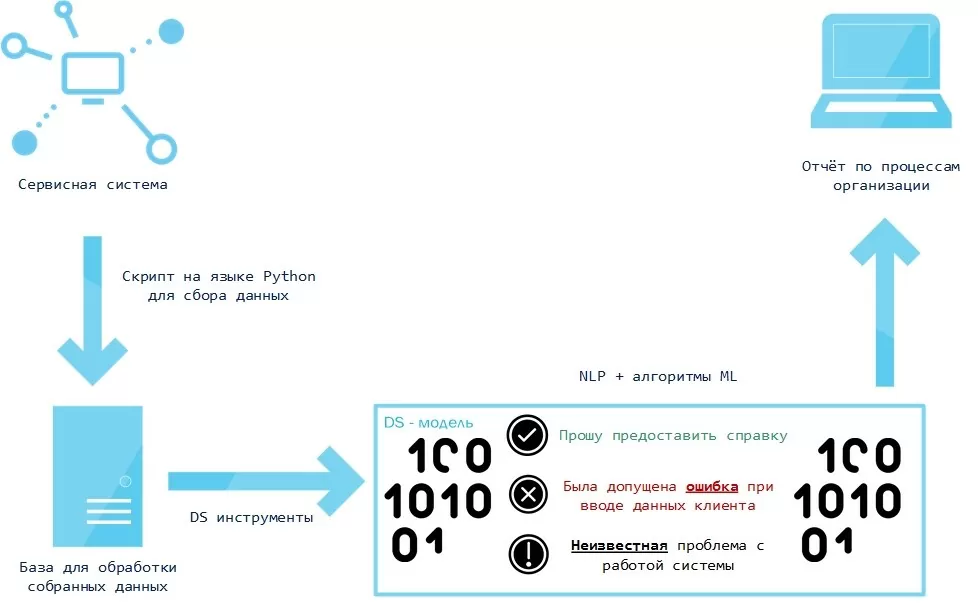
Наши данные хранятся в некоторой сервисной системе, поэтому сначала мы создали скрипт выгрузки данных. После того, как данные были выгружены из системы, мы их предварительно обработали инструментами NLTK (токенизация, лемматизация, удаление стоп-слов, фильтрация по ключевым словам).
При этом мы заранее обучили алгоритм логистической регрессии на выборке, размеченной вручную (задача классификации стандартного и нестандартного). После предварительной обработки на обученную модель подаётся TfidfVectorizer (матрица частот слов) исходного набора данных. Модель показывает записи, которые по её мнению являются необычными. После этого найденные необычные записи подаются на вход алгоритму машинного обучения LocalOutlierFactor, как показано на рисунке ниже.
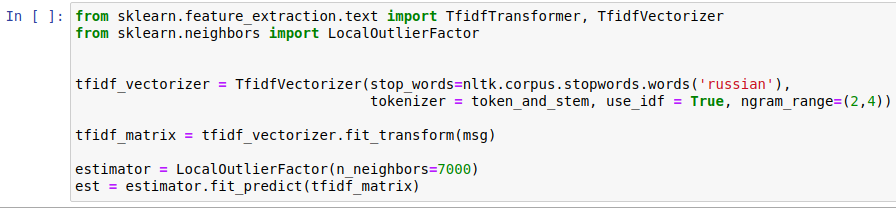
LocalOutlierFactor (Локальный уровень выброса) является алгоритмом выявления аномальных точек данных путём измерения локального отклонения данной точки с учётом её соседних точек. Алгоритм выводит найденные отклонения бизнес-процессов.
После обучения мы внедряем эту модель в работу с новыми данными, и она снова определяет, что хорошо, а что плохо и выдает отчет, с которым работает человек, но этот отчет четко структурирован и легко читается, а обработка его человеком занимает считанные минуты.
Теперь давайте представим, что данные не хранятся в удобной базе и совсем не похожи на привычные таблицы, я говорю о первоисточниках, а именно о бумажных документах. Хорошо, когда этих документов пару папок и их можно прочитать довольно быстро и выяснить для себя все что нужно. А если их тысячи? Подумайте сколько времени у вас это займет, а кроме того ведь нужно сделать какие-то выводы по ним. В этот раз нам поможет такая технология как Computer Vision. Нашей задачей было выгрузить документы, которые хранятся в файловом хранилище и к ним нельзя через скрипты обратиться напрямую. В дальнейшем распознать текст со сканов документов, вычленить оттуда необходимую для анализа информацию и использовать её для некоторой аудиторской проверки.
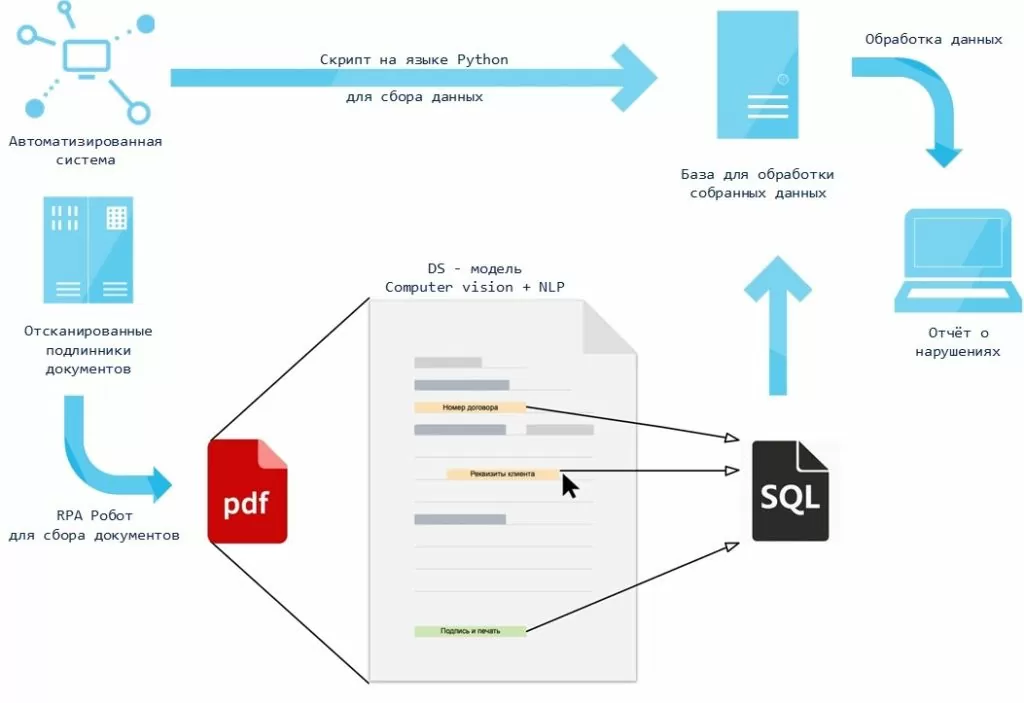
На рисунке выше представлена схема работы использованных алгоритмов и решений. Смоделируем простой пример. Представим, что у нас есть сканы трудовых договор в pdf (например, как на рисунке ниже) и нам необходимо извлечь номер договора.

Чтобы конвертировать pdf в изображение используется библиотека pdf2img языка Python. Затем для распознавания текста с изображения используется библиотека pytesseract (оптическое распознавание символов), которая работает на основе рекуррентных нейронных сетей. Достаточно просто указать путь к изображению и вызвать метод image_to_string, указав при этом параметр языка, который будет распознаваться.
Из структуры договора видим, что после номера договора идёт перенос на новую строку. Будем это использовать для того, чтобы извлечь номер. Пример применения описанного алгоритма к изображению, представлен ниже.

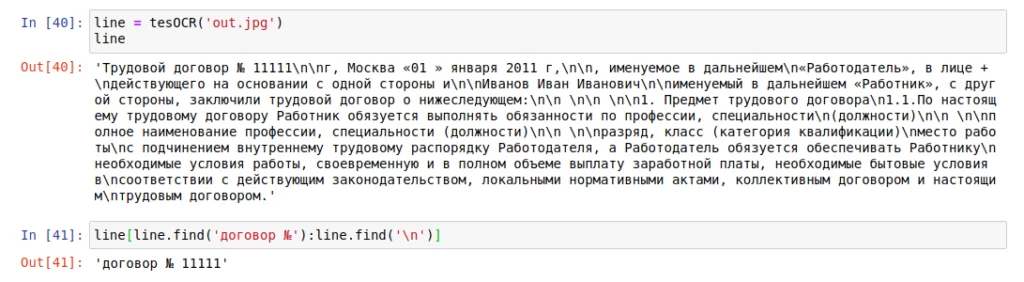
Из рисунка видно, что библиотека pytesseract отлично справилась с распознавание текста, и наш алгоритм правильно определил номер договора. Подобным образом можно решать целое множество различных задач, которые встречаются в работе аудитора.