/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Сегодня, когда прогнозирование с помощью машинного обучения применяется в промышленности, медицине, бизнесе, цена минимальной ошибки и погрешности высока. Для любой аналитики это будет полезно, так как выходные данные станут более достоверными, а значит и более подходящими для дальнейшей работы с ними.
Так как откалибровать вашу модель? Для начала необходимо построить так называемый калибратор, то есть вторую модель, способную помочь приблизить вероятности к реальным.
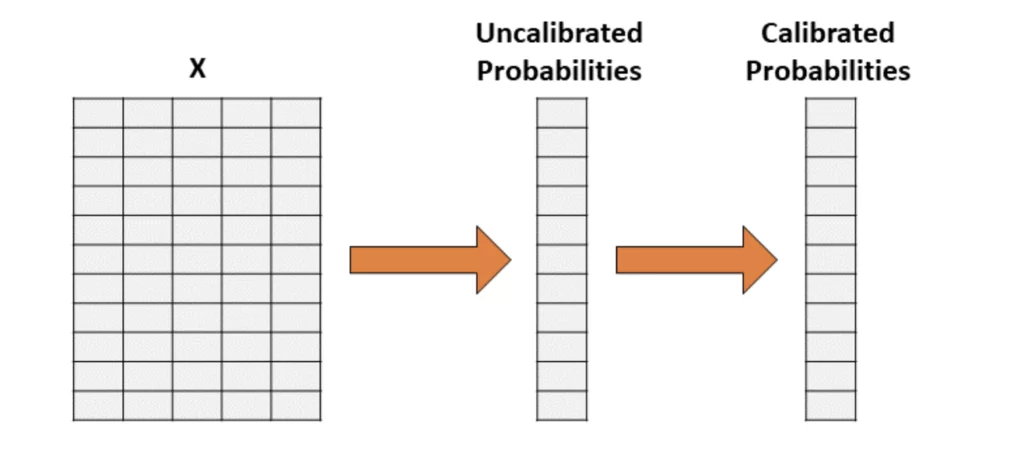
Калибровку не стоит проводить на тех же данных, что применялись для обучения первой модели. Это приведет к смещению, так как производительность модели на его обучающих данных будет выше, чем на новых.
Для калибровки можно использовать достаточно большое количество методов:
- Гистограммная калибровка;
- Изотоническая регрессия;
- Калибровка Платта;
- Логистическая регрессия;
- Деревья калибровки;
- Ансамблирование;
- Сглаживание меток;
- Использование фокальной ошибки и т.д.
Их применение варьируется в зависимости от ситуации.
Откалибровывать нашу модель будем в Python. Поэтому рассмотрим калибровку на примере изотонической и логистической регрессий, так как они уже реализованы в библиотеке SciKit-Learn и будут достаточно показательны.
Вот исходный тестовый набор:
from sklearn.datasets import make_classification
a, b = make_classification(
n_samples = 12000, # количество сэмплов
n_features = 20, # количество функций
n_informative = 20, # количество информ. функций
n_redundant = 10, # количество избыточных функций
weights = [.10, .1], # пропорции сэмплов для каждого класса
random_state = 0) # генерация случайных чисел
a_tr, a_val, a_t = a[:4000], a[4000:8000], a[8000:]
b_tr, b_val, b_t = b[:4000], b[4000:8000], b[8000:]
Следующим шагом будет обучение. Воспользуемся случайным лесом (RandomForestClassifier):
from sklearn.ensemble import RandomForestClassifier
RF = RandomForestClassifier().fit(a_tr, b_tr) # выстраивание случайного леса из исходного набора
prb = RF.predict_proba(a_val)[:, 1] # прогностическая вероятность
Нам необходимо обучить калибратор на основе обеих регрессий, Воспользуемся результирующими данными нашего классификатора:
Логистическая регрессия строит прогнозы в бинарном значении, то есть в диапазоне от 0 до 1.
from sklearn.linear_model import LogisticRegression
logistic_regress = LogisticRegression().fit(prb.reshape(-1, 1), b_val) # подгонка модели с его обучением
# reshape — изменение формы массива
prb_logistic_regress = logistic_regress.predict_proba(RF.predict_proba(a_t)[:, 1].reshape(-1, 1))[:, 1]
Изотоническая регрессия подгоняет линию к последовательности наблюдений.
from sklearn.isotonic import IsotonicRegression
isotonic_regress = IsotonicRegression(y_min = 0, y_max = 1, out_of_bounds = 'clip').fit(prb, b_val)
# out_of_bounds — обработка значений за пределами диапазона данных
# 'clip' — значения, соответствующие конечным точкам интервала
prb_isotonic_regress = isotonic_regress.predict_proba(RF.predict_proba(a_t)[:, 1])
В итоге получаем 3 варианта. Но какая из этих моделей ближе всего к реальным показателям? Метрикой будет служить ожидаемая ошибка калибровки ( ECE), то есть значение ошибок отдельных ячеек. Иногда используют показатель максимальной ошибки калибровки.
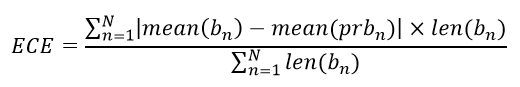
Ненадолго вернемся к теории, чтобы упомянуть, что для оценки калибровки применяется диаграмма надежности. Это гистограмма, где наблюдения, принадлежащие к одной ячейки, имеют равную вероятность. Чем кривая ближе к биссектрисе на графике, тем выше степень откалиброванности модели.
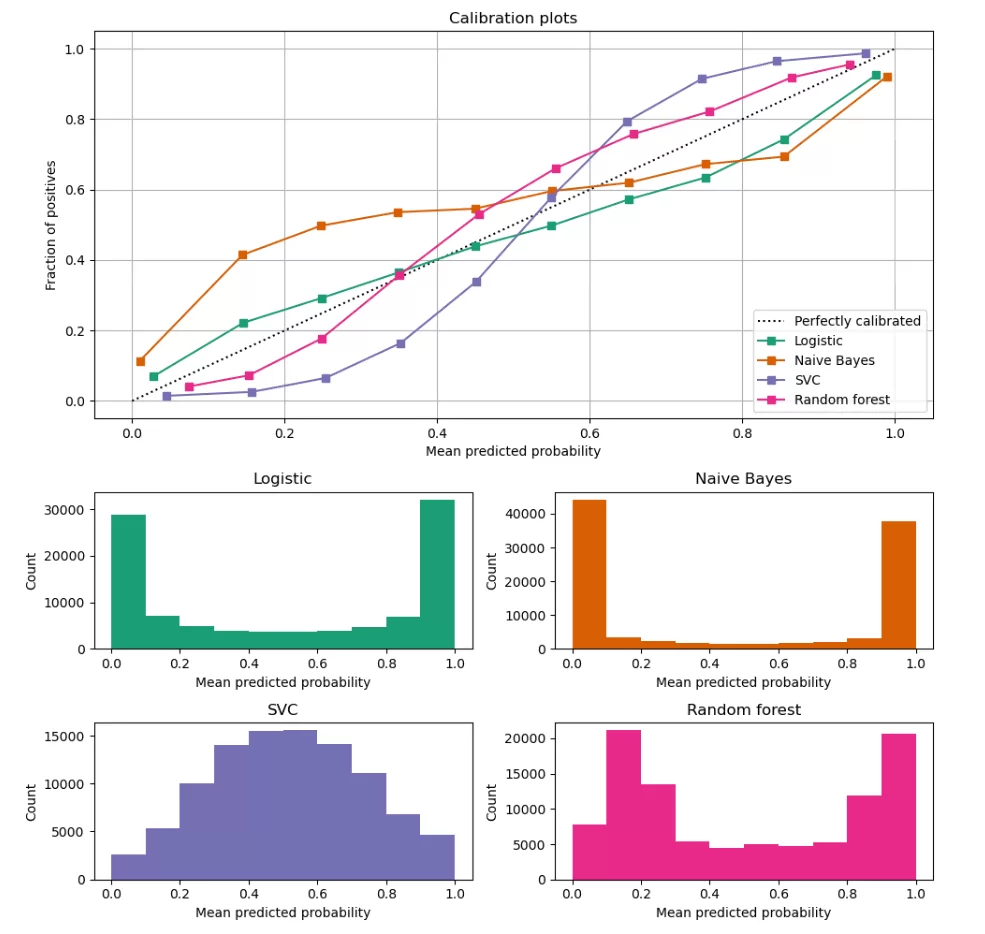
Диаграмма является отображением функции распределения вероятности. Число столбцов (правильнее будет называть их группами) можно найти с помощью:
- формулы Стерджеса;
- правила Райса;
- формулы Доана;
- правила Скотта;
- правила Фридмана-Диакониса.
Так вот в средней ошибке калибровки количество ячеек (n) и будет соответствовать числу групп. Определим это количество с помощью правила Фридмана-Диакониса, так как оно встроено в функцию histogram в numpy.
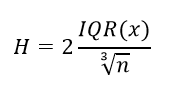
IQR– это межквартильный размах. Грубо говоря, это разница между третьим и первым квартилями, которые делят упорядоченный набор данных на четыре части.
В итоге необходимая нам метрика выглядит так:
def exp_cal_err(b, prb):
import numpy as np
num_count, num_edges = np.histogram(prb, bins = 'fd') #вычисление гистограммы набора данных
#'fd' — правило Фридмана-Диакониса
nums = len(num_count) #количество ячеек
num_edges[0] -= 1e-8 #левый край не включен
num_id = np.digitize(prb, num_edges, right = True) – 1 #вычисление индексов числовых интервалов
num_b_sum = np.bincount(num_id, weights = b, minlength = nums) #количество вхождений в массив
num_prb_sum = np.bincount(num_id, weights = prb, minlength = nums)
num_b_mean = np.divide(num_b_sum, num_count, out = np.zeros(nums), where = num_count > 0) #деление массивов
num_prb_mean = np.divide(num_prb_sum, num_count, out = np.zeros(nums), where = num_count > 0)
expcaliber = np.abs((num_prb_mean - num_b_mean) * num_count).sum() / len(prb) #конечная формула
return expcaliber
Наконец, сравним калибровку трех моделей. ECE будет следующей:
RandomForest — 7.0%
RandomForest + LogisticReg — 2.3%
RandomForest + IsotonicReg — 1.2%
Таким образом, изотоническая регрессия показала самое маленькое отклонение от реальной вероятности в 1.2%. Эта будет наиболее подходящая модель с точки зрения калибровки.
Калибровка моделей необходима, если нам нужны истинные вероятностные результаты, а не их приближения. Особенно её применение важно в отношении сложных нелинейных алгоритмов, поскольку они предоставляют неточные прогнозы. В целом калибровка дает гибкость представления прогнозов, а также вариативность в оценке модели. Если говорить обобщенно, то это важный этап формирования реальных прогнозов. Теперь вы знаете как правильно ей пользоваться.