/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
В данной статье рассмотрим ряд методов для предобработки, а также анализа текстовых данных, описанных на языке R.
В части предобработки текстовых данных для задачи обработки естественного языка (NLP) существует ряд этапов (подзадач), таких как:
- Токенизация (tokenization);
- Частеречная разметка (POS tagging);
- Лемматизация (lemmatization);
- Анализ зависимостей (dependancy parsing);
В качестве библиотеки для анализа текстовых данных возьмём UDPipe (реализация для R), которая так же включает поддержку предобученных моделей для более чем 65 языков, включая русский. Скачиваем модель для русского языка с помощью метода udpipe_download_model и загружаем с помощью метода udpipe_load_model:
library(udpipe)
dl <- udpipe_download_model(language = "russian")
udmodel_ru <- udpipe_load_model(file = dl$file_model) # где dl$file_model – это директория, где находится, непосредственно, файл скаченной моделиДалее берём текст и получаем аннотацию с помощью метода udpipe_annotate, который позволяет получить результат, в том числе для всех перечисленных выше подзадач предобработки текстовых данных, описанных выше (токенизация, частеречная разметка, лемматизация, анализ зависимостей):
txt <- c("Мы должны уметь наиболее четко выражать свои мысли в нашей разговорной или письменной речи для общего развития языка")
x <- udpipe_annotate(udmodel_ru, x = txt)
x <- as.data.frame(x)
str(x)
Результат получаем в формате CONLL-U:
$ doc_id : chr "doc1" "doc1" "doc1" "doc1" ...
$ paragraph_id : int 1 1 1 1 1 1 1 1 1 1 ...
$ sentence_id : int 1 1 1 1 1 1 1 1 1 1 ...
$ sentence : chr "Мы должны уметь наиболее четко выражать свои мысли в нашей разговорной или письменной речи для общего развития языка" "Мы должны уметь наиболее четко выражать свои мысли в нашей разговорной или письменной речи для общего развития языка" "Мы должны уметь наиболее четко выражать свои мысли в нашей разговорной или письменной речи для общего развития языка" ...
$ token_id : chr "1" "2" "3" "4" ...
$ token : chr "Мы" "должны" "уметь" "наиболее" ...
$ lemma : chr "мы" "должен" "уметь" "наиболее" ...
$ upos : chr "PRON" "ADJ" "VERB" "ADV" ...
$ xpos : chr "PRP" "JJH" "VB" "RBS" ...
$ feats : chr "Case=Nom|Number=Plur|Person=1" "Degree=Pos|Number=Plur|Variant=Short" "Aspect=Perf|VerbForm=Inf|Voice=Act" "Degree=Sup" ...
$ head_token_id: chr "2" "0" "2" "5" ...
$ dep_rel : chr "nsubj" "root" "xcomp" "advmod" ...
$ deps : chr NA NA NA NA ...
$ misc : chr NA NA NA NA ...
Для примера выведем токены из предыдущего результата (датафрейма) — поле token:
str(x$token)Результат будет следующим:
"Мы" "должны" "уметь" "наиболее" "четко" "выражать" "свои" "мысли" ...Аналогично можно вывести леммы и части речи (lemma, upos).
Теперь попробуем построить граф зависимостей. Для этого вернёмся к результату udpipe_annotate, находящемуся в датафрейме x. Связь между токенами определяется в полях token_id и head_token_id, отношение зависимости определено в dep_rel. Для построения графа нам понадобятся библиотеки igraph, ggraph, ggplot2:
library(igraph)
library(ggraph)
library(ggplot2)
e <- subset(x, head_token_id != 0, select = c("token_id", "head_token_id", "dep_rel"))
e$label <- e$dep_rel
gr <- graph_from_data_frame(e,vertices = x[, c("token_id", "token", "lemma", "upos", "xpos", "feats")],directed = TRUE)
ggraph(gr, layout = "fr") +
geom_edge_link(aes(label = dep_rel), arrow = arrow(length = unit(3, 'mm')), end_cap = circle(3, 'mm')) +
geom_node_point(color = "green", size = 4) +
theme_void(base_family = "") +
geom_node_text(ggplot2::aes(label = token), vjust = 2)
Результат построения графа следующий:
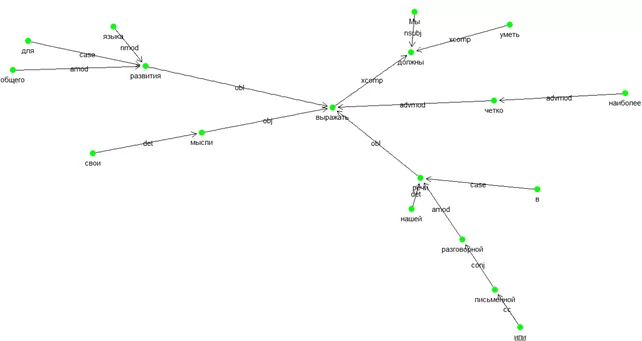
Данный пример кратко демонстрирует возможности UDPipe в работе с текстовыми данными. В сочетании с мультиязычностью применение данного инструмента в проекте на R может быть хорошим выбором