/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
В современном мире существуют разные системы управления, которые представляют собой рабочее пространство для ведения проектов. Одной из таких систем является Jira. Система Jira помогает пользователям обмениваться информацией, отслеживать соблюдение сроков выполнения работы, а также просматривать прогресс решения задач.
Для помощи сотрудникам отдела внутреннего аудита требовался инструмент, который позволял отслеживать различные доработки по автоматизированным системам банка и быстро осуществлять поиск невыполненных поручений. Задача заключалась в том, чтобы выявить набор шаблонов, которые встречаются в описании задач со статусами «не выполнено», «выполнено» и «отменено». Необходимые данные, хранятся в системе управления проектам Jira.
Предварительно была создана база данных с необходимыми атрибутами, которые позволили произвести предобработку информации.
Предобработка заключалась в том, чтобы:
- Очистить данные от строк, не содержащих описания и названия задачи;
data = X[‘Название’].dropna()
2. Перевести категориальную переменную «статус» в цифровой формат, так как требуется провести классификации в зависимости от выполненных, невыполненных и отмененных задач. Пример структуризации успешных задач:
success = ['Done', 'Resolved', 'Closed', 'Закрыт', 'Approved', 'Внедрено', 'Исправлен', 'Выполнено', 'Реализовано', 'Закрыто', 'Разработка завершена', 'Ready']
X['new_status'] = X['Статус'].apply(lambda x: 1 if x in success else 2)
X [['Статус', 'Название', 'new_status']].head()
Для того, чтобы осуществить быстрый поиск доработок было принято решение использовать технологии text mining для анализа информации, находящейся в описании и названии задач. Инструмент обработки естественного языка (Natural Language Processing) позволяет провести глубокое исследование текста, выяснить ключевые темы.
Основной библиотекой в языке программирования python при работе с естественным языком является NLTK. Библиотека обладает набором инструментов для обработки и классификации текстов, токенизации, стеминга и фильтрации.
На первом этапе обработки текстовой информации требовалось провести токенизацию по словам (разделение предложений на слова-компоненты). Следующий шаг заключался в приведении всех словоформ к одной словарной форме. Далее были выделены стоп-слова, которые необходимо удалить из текстовых данных для предотвращения добавления шума. Затем осуществлялось преобразование текста в наборы цифр(векторы), определив при этом словарь токенов и частоту их встречаемости. В основу была положена концепция TF-IDF, которая определяла статическую меру для оценки важности слова, так как часто встречающиеся слова могут не удовлетворять требованиям поиска.
from sklearn.feature_extraction.text import TfidfVectorizer
tf_vectorizer = TfidfVectorizer(stop_words=stopwords, ngram_range = (1,2))
X_train_vector = tf_vectorizer.fit_transform(data)
X_train_vector.shape
Второй этап заключается в том, чтобы подобрать алгоритм для классификации текстовой информации. Основным алгоритмом для этого использовался SGDClassifier, который быстро учится на большом наборе данных и позволяет получить интерпретируемые оценки.
logit_sgd = SGDClassifier(loss='log', random_state=42, class_weight="balanced")
logit_sgd.fit(Xtr, ytr)
На завершающем этапе разработки потребовалось провести визуализацию полученных результатов для упрощения поиска нужной информации. Например, распределение слов для отмененных задач представлена далее:
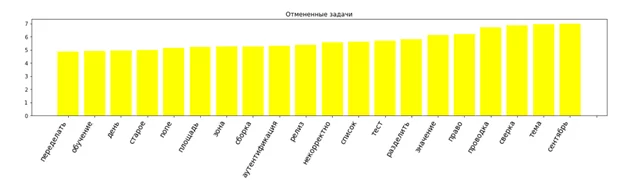
В результате анализа базы данных задач по доработкам из системы управления проектов Jira для классификации автоматизированных систем, удалось определить наборы слов, встречающихся в описании по доработкам, которые находятся в стадии невыполненных, выполненных и отмененных в процессе работы. Полученная информации позволяет сделать выводы о том, какие слова встречаются в формулировке и описании задач. Таким образом созданный инструмент позволяет улучшить выявление невыполненных задач применяя контекстный поиск.