/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 3 мин.
Вариант 1. Векторизация нейросетью и использование shap
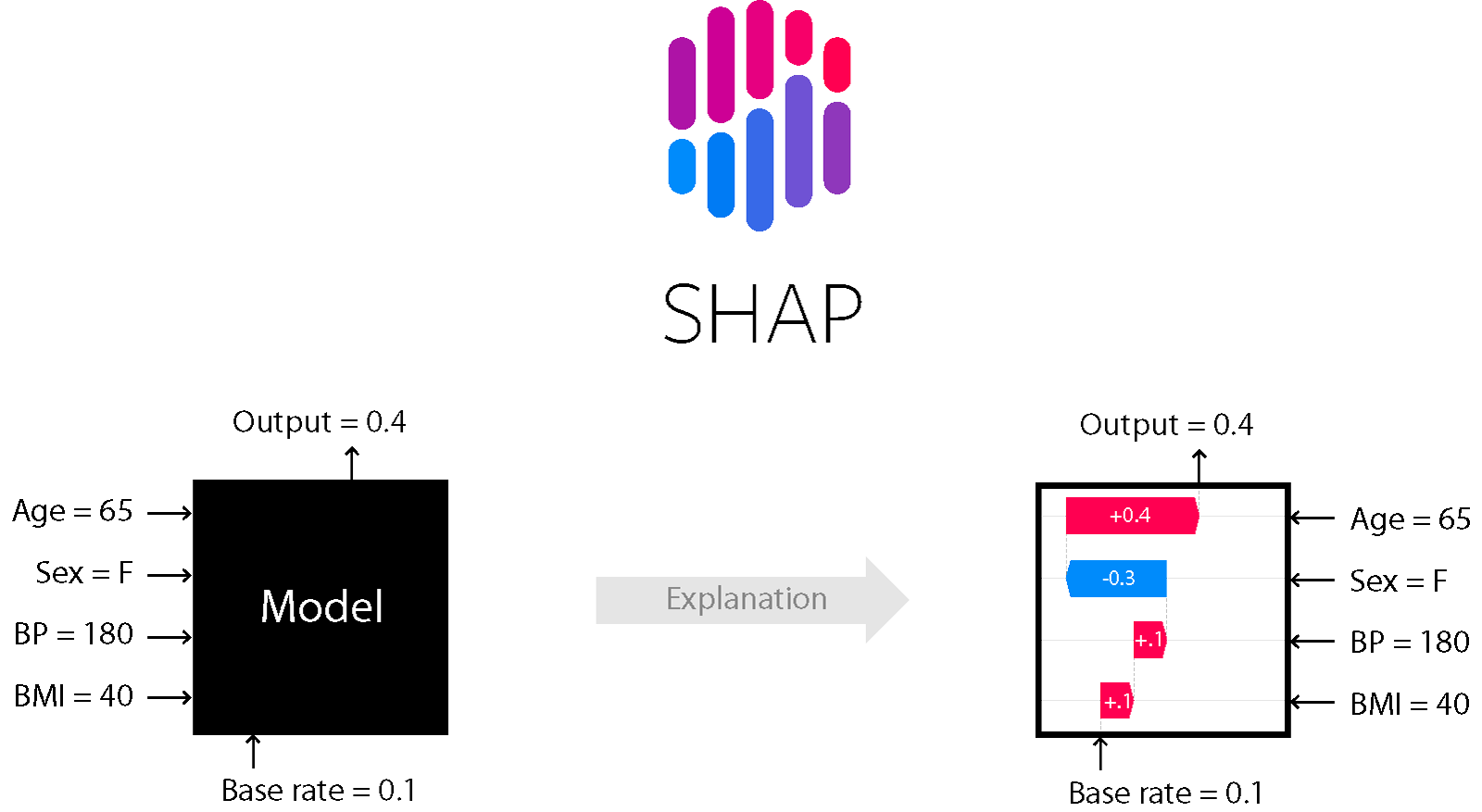
Для векторизации предложений часто используются различные вариации Bert, например, Sentence Bert. Библиотека SHAP может работать со всеми моделями с Huggigface, делается это в несколько строчек:
model = transformers.pipeline('sentiment-analysis', model='sberbank-ai/sbert_large_nlu_ru', return_all_scores=True)
explainer = shap.Explainer(model)
shap_values = explainer(["Библиотека SHAP может работать со всеми моделями с Huggingface",
"Библиотека SHAP никогда не срабатывает с Huggingface"])
shap.plots.text(shap_values)
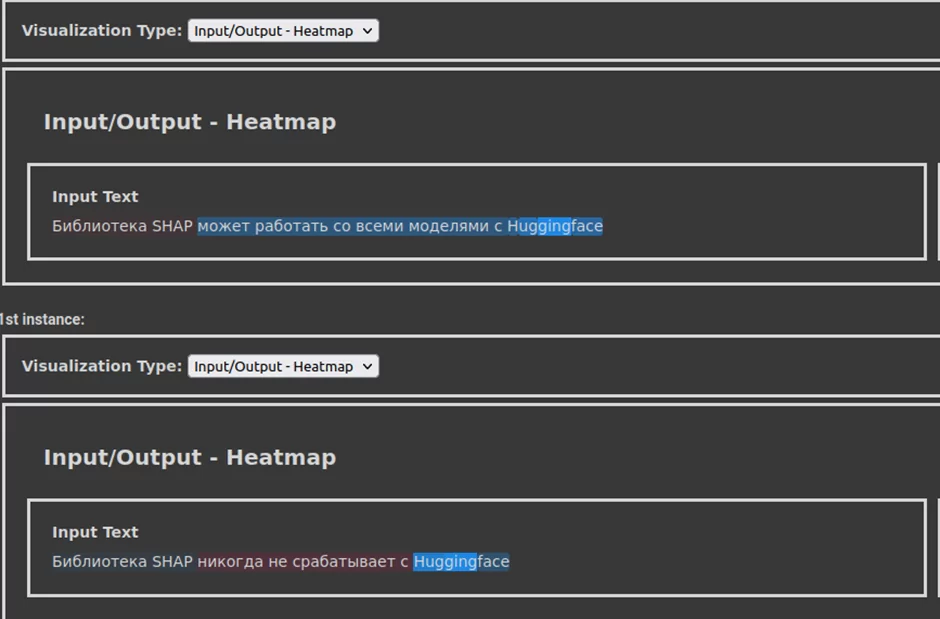
В результате получаем shap values для каждой части текста, они отражают насколько конкретный токен изменил наше предсказание по сравнению с некоторым “базовым” значением.
Полноценный пример использования shap и transformers по ссылке. Кроме того, есть недавняя статья о усовершенствовании этого подхода ссылка.
Вариант 2. Векторизация tf-idf, классификация xgboost
Первое, от чего можно отказаться — от нейросетевых методов. Да, это снижает качество, но их интерпретация заметно труднее (те же shap values используются в примере выше не в чистом виде), поэтому стоит попробовать более простую модель. На ум сразу приходит эффективная комбинация TfidfVectorizer из sklearn и XGBClassifier из xgboost. Первый кодирует каждое предложение вектором длиной в словарь из всего обучающего корпуса текстов, подробнее по по ссылке. Второй уже классифицирует получившиеся вектора.
Преимущество этого подхода — каждому слову сопоставляется одна размерность вектора (один столбец в матрице, полученной из TfidfVectorizer). Можно посмотреть на его важность в модели и составить представление о причинах классификации.
Но как получить эту “важность”? Стандартный способ — использовать встроенный в бустинг метод feature_importances_, но с ним есть несколько проблем. Например, разные типы важности, результаты ранжирования по которым часто дают неоднозначные результаты. Как их совмещать? Усреднять, складывать с какими-то весами, использовать что-то одно? Это вопросы, ответ на которые придётся искать в каждой конкретной задаче, хотелось бы получить более универсальный инструмент.
Кроме того, открытым остается и вопрос о интенсивности влияния каждого слова. Можно понять, что токен “2021” важнее “приказ”, но не поймем настолько сильно предсказание модели зависит именно от этого слова. Следовательно, не сможем понять — наш классификатор просто выучил локальные особенности документов или смог обобщить наблюдения?
Вариант 3. Векторизация tf-idf, классификация xgboost, объяснение shap.
Что могло бы улучшить предыдущий подход? Я хотел бы получать одно значение, при этом оно должно адекватно отражать важность каждого токена. Этого можно добиться, совмещая два предыдущих подхода. С одной стороны, я получаю информацию отдельно по каждому слову, с другой — имею всего одно значение. По моему опыту этот вариант наиболее просто интерпретируемый. Вот пример кода с получением графика важности:
vectorizer = TfidfVectorizer()
model = XGBClassifier()
vectorized_train_sample = vectorizer.fit_transform(X_train)
model.fit(vectorized_X_train, y_train)
explainer = shap.TreeExplainer(model)
vectorized_test = vectorizer.transform(test_sample)
shap_values = explainer.shap_values(vectorized)
shap.summary_plot(shap_values, vectorized_test, feature_names=vectorizer.get_feature_names_out(), plot_type='bar', show=True)
Я рассмотрел три варианта интерпретации модели машинного обучения в приложении к конкретной задаче. Конечно можно ещё упрощать модель — использовать логистическую регрессию и смотреть на веса коэффициентов или одно решающее дерево и просматривать путь от вершины к листам, но эти способы излишне упрощают модель, обычно их не хватает для решения задачи. Представленные же способы дают заметно более высокое качество и сохраняют интерпретируемость.