/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Стандартные способы получения информации SharePoint (экспорт списка в Excel, запрос Power Query) подойдут для разовых потребностей аналитика данных. Но если возникают задачи, требующие автоматизации (например, регулярная загрузка информации с портала, передача ее в таблицу в базе данных и т.д.), не обойтись без написания кода.
В SharePoint реализована служба REST (служба передачи репрезентативного состояния), которая позволяет разработчикам удаленно работать с данными SharePoint.
Технически это выглядит так: мы отправляем на сервер SharePoint веб-запрос, и получаем от сервера ответ в пригодном для дальнейшей обработки формате (в частности JSON), с запрошенной информацией о контенте БД SharePoint:
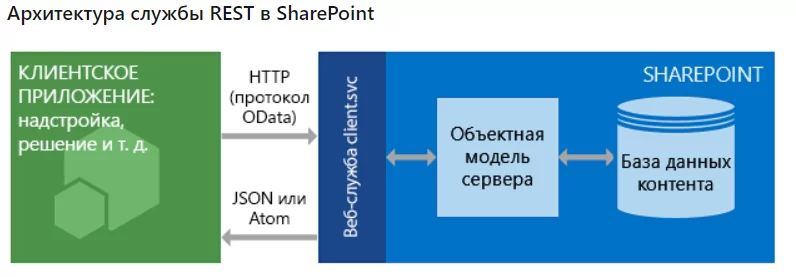
Используя объектную модель SharePoint, данные портала можно не только читать, но и создавать, обновлять и удалять. Если вы обладаете базовыми знаниями одного из языков программирования (например, Python), то самое простое — чтение и первичную обработку записей списка — реализовать совсем не сложно.
Далее рассмотрим, как загрузить и обработать информацию списка SharePoint, используя общеизвестные библиотеки Python: requests и pandas.
1. Импортируем библиотеки:
import requests, requests_ntlm
from requests_ntlm import HttpNtlmAuth
import pandas as pd
import json
Библиотеки requests_ntlm и json необходимы для аутентификации пользователя на портале SharePoint и обработки полученных данных.
2. Выбираем тип авторизации и задаем учетные данные для авторизации на портале (используем доменный логин и пароль):
username=r'mydomain\mylogin'
password='mypassword'
auth=HttpNtlmAuth(username,password)
Здесь приведен пример с открытой передачей логина и пароля, но, конечно, лучше реализовать сквозную аутентификацию в текущем сеансе.
3. Начинаем определять параметры, которые далее передадим веб-запросу с использованием библиотеки requests.
Вначале нужно найти в структуре объектов SharePoint интересующий нас объект – список, чтобы обратиться к его элементам (записям).
Есть два способа поиска:
— по уникальному идентификатору (guid) объекта, это ID вида ‘5b7055e5-309d-4b80-bae5-9b570164f85d’, который предварительно нужно найти в параметрах всех списков сайта (но для этого нужно немного «покопаться» в структуре объектов SharePoint);
— более простой способ – найти объект по его отображаемому имени (Title), что мы сейчас и будем делать. Предположим, что мы уже знаем название списка (например, ‘MyList’).
Для обращения к списку нужно написать HTTP-запрос с полным URL объекта, который можно найти, используя метод GetByTitle.
Текст запроса для получения записей списка MyList будет таким:
list_url=r"https://mysite.ru/_api/Web/Lists/GetByTitle('MyList')/Items?$top=2000"Подробно о составляющих нашего URL:
https://mysite.ru – адрес сайта SharePoint, где находится список (включая дочерние сайты, через слэш, например https://mysite.ru/site1/)
/_api/Web/ — стандартный путь к веб-интерфейсу REST API, его всегда нужно подставлять после адреса сайта/дочернего сайта;
/Lists/ — обращаемся к спискам нашего сайта;
/GetByTitle(‘MyList’)/ — передаем методу GetByTitle название нужного объекта для поиска;
/Items? – запрашиваем элементы найденного объекта SharePoint (записи списка);
$top=2000 – параметр фильтрации запрашиваемых данных, указывающий на число элементов списка (2000), которые мы хотим получить (начиная с первой записи). Его нужно обязательно указывать, т.к. по умолчанию (если запросить просто Items?), API возвратит только первые 100 элементов.
Вместо 2000 можно указать любое интересующее число записей, если нужно получить все – это число можно указать «с запасом» (при необходимости можно определять максимальное количество элементов в списке и передавать его, сейчас используем самый простой вариант).
4. Указываем, какой тип данных хотим вернуть в ответе сервера, а именно JSON:
headers = {'Accept': 'application/json;odata=verbose'}5. Tеперь у нас есть все параметры для составления веб-запроса (URL списка, данные для аутентификации пользователя портала, нужный тип данных). Направляем запрос к сайту SharePoint:
responce=requests.get(list_url,verify=False,auth=auth,headers=headers)Чтобы убедиться в том, что аутентификация прошла успешно и запрошенные данные успешно получены, можно вывести на экран результат команды print(response):
Если мы видим ответ <Response [200]>, это значит, что соединение прошло успешно и данные получены без ошибок.
6. Если мы сейчас выведем на экран полученный объект JSON,
response_json=responce.json()
print(response_json)
станет очевидна необходимость структурирования полученных данных:
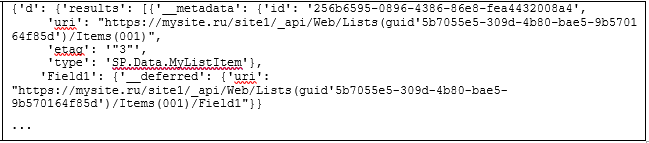
Полученный ответ имеет типовую для формата JSON структуру, и его необходимо нормализовать при помощи библиотеки json, чтобы работать с ним далее в pandas:
response_json=responce.json()
from pandas.io.json import json_normalize
response_json_norm =json_normalize(responce_json['d']['results'])
В данном случае структура полученного JSON содержит вложенные уровни, начинаем разбирать его с первого уровня [‘d’][‘results’]. Результат нормализации представляет собой не что иное, как словарь Python, который можно преобразовать в датафрейм pandas:
df=pd.DataFrame.from_dict(response_json_norm)
df.shape
df.info()
7. Сейчас мы наконец-то получили данные списка в датафрейм pandas и работаем с ним далее.
Мы видим, что в датафрейм вошли все поля нашего списка MyList, включая и те, которые являются техническими и в пользовательских представлениях списка в SharePoint не отражаются:
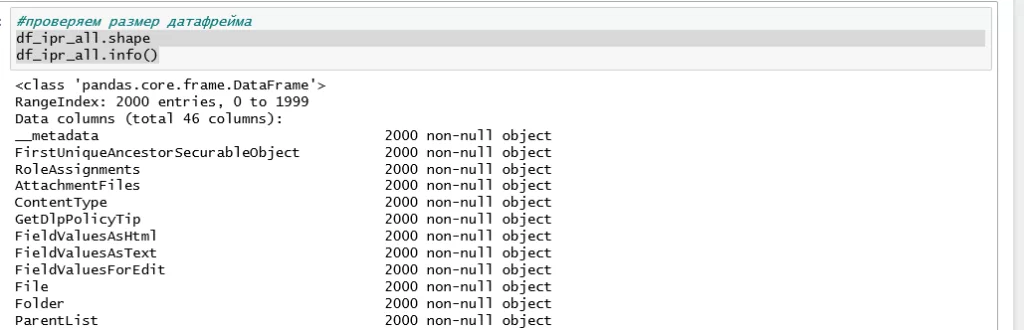
Это дает нам возможность определиться с тем, какие столбцы исходного списка мы хотим видеть в итоговой выгрузке (скорее всего все без исключения столбцы нам не нужны).
Предположим, мы определили 3 значимых для нас столбца: ID, Field1, Field2. Остальные мы можем удалить прямо из датафрейма df, но лучше отредактировать веб-запрос, чтобы сразу получить только необходимые данные.
Для этого нужно добавить в запрос фильтрацию с помощью параметра $select= и перечислить нужные столбцы через запятую:
list_url=r"https://mysite.ru/_api/Web/Lists/GetByTitle('MyList')/Items?$select?=ID, Field1, Field2&$top=2000"Перед следующим условием выборки (количество записей = 2000) теперь нужно добавить амперсанд &, и повторить последующие действия по отправке запроса на сайт SharePoint, получению и обработке ответа из пп. 5-7.8. Заключительный этап – сохранение данных из датафрейма df в файл формата MS Excel.
df.to_excel(‘MyList_in_xls.xlsx’)Все! Можно работать с данными списка в MS Excel:
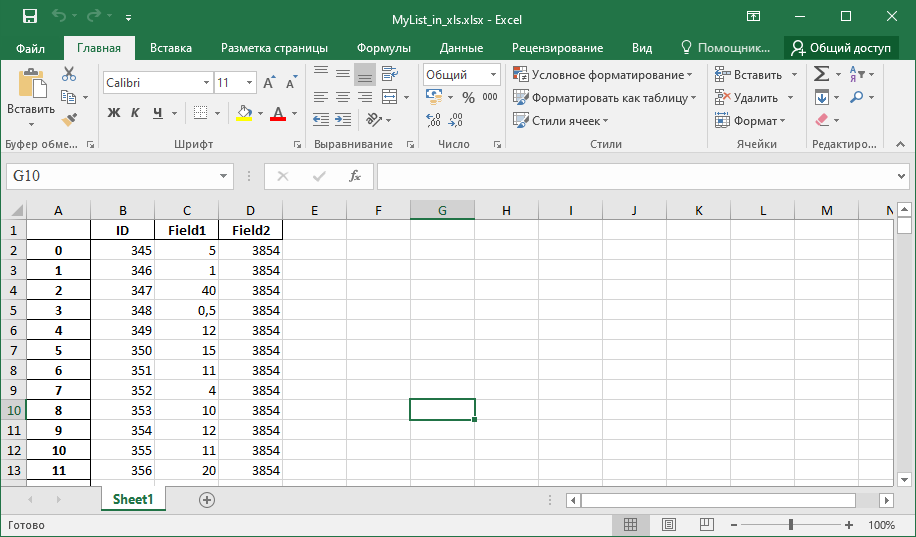
Итак, мы рассмотрели простой пример написания веб-запроса для чтения данных списка SharePoint c использованием REST API, и сохранения полученных записей в файл MS Excel. Если вам необходимо не только читать данные из объектов SharePoint, но и изменять, удалять, обновлять их на сайте, необходимую справочную информацию можно найти на сайте компании Microsoft в разделе «API REST SharePoint».