/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Бывает, что для определения слабого места процесса аудитору необходимо проанализировать, какие показатели влияют на конечный результат и какова степень их влияния. При ручной проверке данных велика вероятность пропустить какой-либо из признаков, в то время как влияние этого признака на конечный результат будет значительным. Применение методов автоматизированных средств анализа данных позволит избежать вероятность исключения важного признака из анализируемых данных.
При выборе инструмента, с помощью которого можно решить задачу определения степени зависимости, мы остановились на фреймворке для платформы .net Accord.Net – инструменте машинного обучения с открытым исходным кодом.
Для определения степени зависимости результата от входных параметров мы будем использовать класс фреймворка, реализующий модель логистической регрессии.
Логистическая регрессия широко используется в различных сферах, таких как медицина или маркетинг, для предсказания болезней или спроса на товар, мы же попробуем применить этот метод для определения признаков некачественно выполненных заявок в службу поддержки пользователей компании.
Возьмем данные по заявкам пользователей в службу поддержки
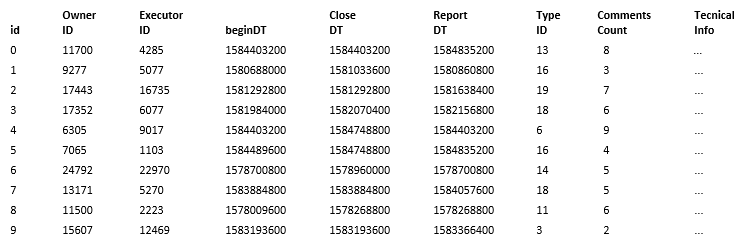
Здесь колонка isCorrect (оценка корректности выполнения обращения) будет результирующим индикатором, на который будут влиять остальные свойства заявки. Проверим гипотезу, что на результирующий показатель влияние будет оказывать только параметр score, используя модель логистической регрессии.
Загрузим исходные данные по заявкам в таблицу данных используя методы библиотеки Accord.IO:
var dataFile = "./data.csv";
var dataTable = new CsvReader(dataFile, true).ToTable();
Для обучения модели необходимо разделить таблицу данных на массив результирующих показателей и массив входных данных.
В исходных данных большинство значений – числовые, а строковые значения – информационные поля, которые не оказывают влияния на результат, поэтому мы исключаем их из таблицы данных.
Оставшиеся данные преобразуем в 2 массива – массив результатов и массив входных параметров:
var resultValue = dataTable.Columns["isCorrect"].ToArray<double>();
dataTable.Columns.Remove("id");
dataTable.Columns.Remove("isCorrect");
dataTable.Columns.Remove("description");
dataTable.Columns.Remove("tecnicalInfo");
var inputParameters = dataTable.ToJagged<double>();
Используя метод обучения Iteratively Reweighted Least Squares, создадим модель логической регрессии и обучим ее, используя массив входных параметров и результирующий массив данных:
var learner = new IterativeReweightedLeastSquares<LogisticRegression>()
{ Tolerance = 1e-4,
MaxIterations = 100,
Regularization = 0,};
var regression = learner.Learn(inputParameters, resultValue);
regression.Save("./models/Scorer.ml");
Для получения коэффициентов зависимости модели необходимо вызвать метод GetOddsRatio. Метод возвращает коэффициенты линейной функции для порядкового номера параметра.
Выведем на экран коэффициенты для каждого из параметров:
for (var col = 0; col < dataTable.Columns.Count; ++col)
{Console.WriteLine(@"{0} - odd {1}", dataTable.Columns[col].ColumnName, regression.GetOddsRatio(col));} 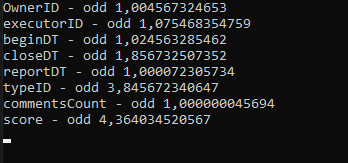
По полученным коэффициентам мы делаем вывод, что изначальная гипотеза верна и параметр «оценка пользователем score» оказывает сильное влияние на результат, но помимо этого мы выявили еще один важный параметр – тип обращения TypeID.
В ходе использования фреймворка были выделены следующие положительные стороны:
— Простота использования означает низкий порог вхождения и выполнение задач с минимальными трудозатратами;
— Данные загружаются в стандартный класс языка DataTable, что позволяет загружать данные из любых источников, помимо тех, к которым предоставляется доступ через методы фреймворка;
— Фреймворк написан для платформы .Net, что позволяет пользоваться преимуществами объектно-ориентированного программирования;
Из явных минусов отметим строгую типизацию входных параметров, что ограничивает применение инструмента в задачах, где показатели объекта — данные разных типов.
Фреймворк Accord.Net был полезен для решения задачи поиска влияющих параметров, подтвердил изначальную гипотезу и выявил дополнительное свойство, влияющее на результат. В дальнейшем мы планируем использовать его в работе, для решения задач, в которых возможно применение алгоритмов машинного обучения.