/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
В последнее время я сосредоточился на рассмотрении встроенных библиотек Python. В Python есть много интересных функций, которые предоставляют готовые реализации и решения для различных типов проблем.
Одним из примеров является встроенная библиотека, которую мы рассмотрим в этой статье — Difflib. Поскольку она встроена в Python3, нам не нужно ничего скачивать или устанавливать, просто импортируем её следующим образом.
import difflib as dl- Поиск «измененных» элементов
Первая функция, которую мы рассмотрим, это context_diff().
Создадим два списка с некоторыми строковыми элементами.
s1 = ['Python', 'Java', 'C++', 'PHP']
s2 = ['Python', 'JavaScript', 'C', 'PHP']
Затем, мы можем сгенерировать сравнительный «отчет» следующим образом.
dl.context_diff(s1, s2)Для этого будем использовать цикл for для функции context_diff(), чтобы вывести все за один раз.
for diff in dl.context_diff(s1, s2):
print(diff)
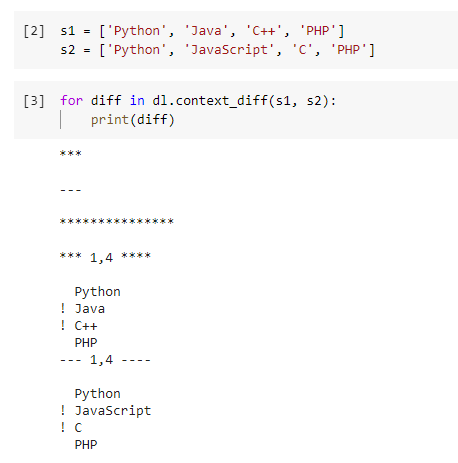
В выводе видим результат, что второй и третий элементы отличаются, на это нам указывает восклицательный знак !
В этом случае первый и четвертый элементы одинаковые, так что в выводе нам будут показывать разницу. Если мы сделаем сценарий более сложным, функция покажет что-то более полезное. Давайте изменим наши два списка следующим образом.
s1 = ['Python', 'Java', 'C++', 'PHP']
s2 = ['Python', 'Java', 'PHP', 'Swift']
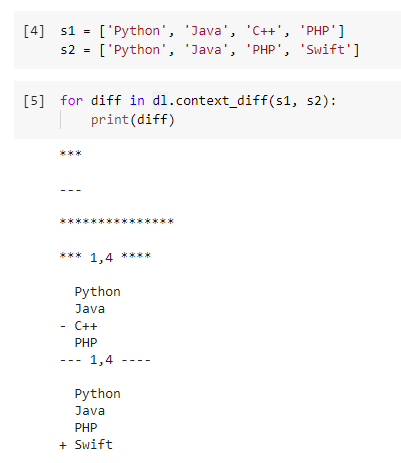
Из приведенного выше вывода следует, что «C++» был удален из первого списка (исходный список), а «Swift» и добавлен во второй (новый список).
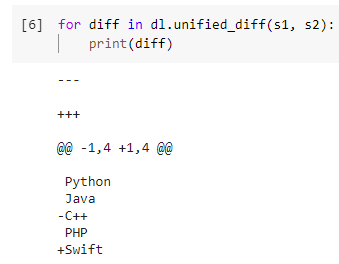
Для более удобного чтения вывода можем использовать функцию dl.unified_diff(s1, s2) — функция «унификации» двух списков вместе может генерировать выходные данные, как показано ниже, что, на мой взгляд, зрительно воспринимается гораздо легче.
2. Точно указываем на различия
В первом разделе мы сосредоточились на выявлении различий на уровне строк. Теперь попробуем получить более конкретный вывод. Сравним несколько слов и покажем, в чем разница. Для этих целей мы можем использовать функцию ndiff().
Предположим, мы сравниваем слова из двух списков.
['tree', 'house', 'landing']
['tree', 'horse', 'lending']
Эти три слова выглядят похожими, но только второе и третье имеют одну измененную букву. Давайте посмотрим, что нам вернет функция.
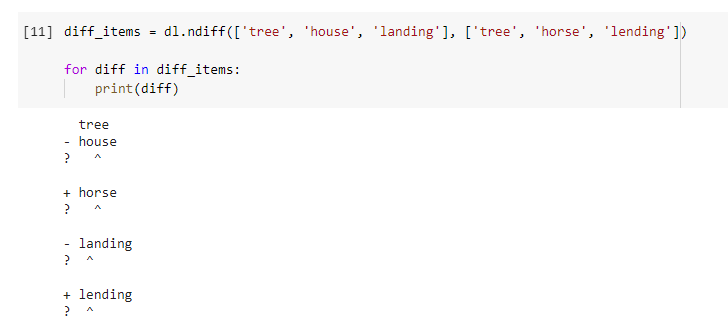
Функция показывает не только то, что было изменено (со знаком минус и плюс) и не изменено («tree» не изменено, поэтому индикатора нет вообще), но и то, какая буква была изменена. Символ ^ показывает какая буква была определена как различная.
3. Поиск близких соответствий в строках
Теперь поговорим о другой возможности стандартной библиотеки Python. Предположим, мы попали в ситуацию, когда нам понадобилось, найти в списке слова, похожие на некую входную строку. Решить эту задачу можно с помощью функции get_close_matches() — ищет наилучшие, «достаточно хорошие» совпадения. Первый аргумент этого метода задаёт искомую строку, второй аргумент задаёт список, в котором выполняется поиск.
Давайте рассмотрим пример:
dl.get_close_matches('thme', ['them', 'that', 'this'])
Функция успешно определяет “them”, когда мы вводим “thme” (опечатка), а не “that” или “this”, потому что “ them” — самое близкое. Однако функция не гарантированно что-то вернет. То есть, когда нет ничего достаточно близкого к входным данным, будет возвращен пустой список.

Метод поддерживает необязательный именованный аргумент cutoff (по умолчанию он установлен в значение 0.6), который позволяет задавать пороговое значение для оценки совпадений

cutoff = 0.1 достаточно маленькое значение, и входное слово соответствует всему списку из второго аргумента. Мы можем ограничить количество возвращаемых слов с помощью параметра n, который задаёт максимальное число возвращаемых совпадений.

4. Как изменить строку?
Если вы обладаете некоторыми знаниями в области поиска информации, то, возможно, уже поняли, что вышеприведенные функции используют расстояние Левенштейна. Функция ищет разницу между двумя текстовыми аргументами и измеряет “расстояние” между ними.
Расстояние Левенштейна между двумя словами — это минимальное количество односимвольных правок (вставок, удалений или замен), необходимых для изменения одного слова в другое. Иногда различным модификациям присваивается разный вес.
Используя Difflib, мы можем даже реализовать шаги применения расстояния Левенштейна к двум строкам. Это можно сделать с помощью класса SequenceMatcher.
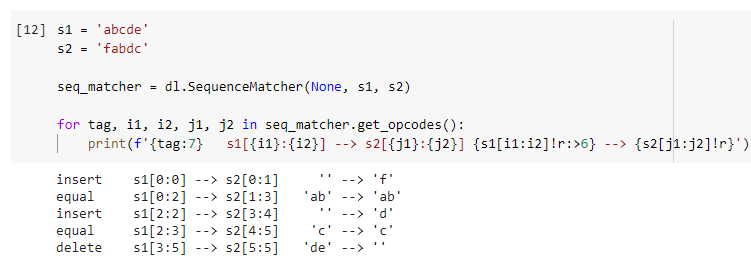
Предположим, что у нас есть две строки abcde и fabdc, и мы хотели бы знать, как первая может быть модифицирована во вторую. Первым шагом является создание экземпляра класса.
s1 = 'abcde'
s2 = 'fabdc'seq_matcher = dl.SequenceMatcher(None, s1, s2)
Затем мы можем использовать метод класса get_opcodes(), чтобы получить список кортежей, который указывают:
- Тег модифицирующего действия (insert, equal или delete)
- Начальная и конечная позиции исходной строки
- Начальная и конечная позиции строки назначения
Мы можем вывести информацию выше в более понятный вид.
for tag, i1, i2, j1, j2 in seq_matcher.get_opcodes():
print(f'{tag:7} s1[{i1}:{i2}] --> s2[{j1}:{j2}] {s1[i1:i2]!r:>6} --> {s2[j1:j2]!r}')
Обратите внимание, что первый аргумент, который мы передавали в SequenceMatcher — это None. Этот параметр используется для указания алгоритма, что некоторые символы могут быть «проигнорированы». Это не означает удаления символов из исходной строки, но будет игнорировать их при обработке алгоритма. Давайте рассмотрим пример.
seq_matcher = dl.SequenceMatcher(lambda c: c in 'abc', s1, s2)
Аргумент “abc” не будет прогоняться через алгоритм, но будет рассматриваться как единое целое.
Приведенный ниже пример показывает, как можно использовать эту функцию на практике.

В этой статье мы рассмотрели встроенную библиотеку Python под названием Difflib. Она может генерировать отчеты, указывающие на различия между двумя списками или двумя строками. Кроме того, она может помочь нам найти наиболее близкие строки совпадений между входными данными и списком строк-кандидатов. В конечном счете, мы можем использовать класс этого модуля для достижения некоторых более сложных и продвинутых функций.