/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
В сфере благотворительности наблюдается много случаев мошенничества. Например, в сети часто подделывают картинки со сборами денег на лечение, меняя данные карты. Попробуем выявить факты мошенничества. Будем искать похожие изображения с разными реквизитами. Это, возможно, будет указывать на то, что реквизиты на одной из похожих фотографий были изменены с целью получения наживы путём обмана.
Ключевые библиотеки: BeautifulSoup для парсера, opencv для получения корреляции между изображениями, tesseract для получения текстовой информации с изображений.
ПАРСЕР
Для начала, пропарсим поисковую выдачу картинок яндекса по ключевым запросам. Загружаем найденные картинки, получаем прямые ссылки на них и ссылки на страницу сайта, где они размещены.
pages = range(1,14) # Кол-во обрабатываемых страниц в запросе
list_links_to_pics, list_links_to_websites, \
fls_saved, list_links_yandex = [], [], [], []
req_num = 0
for link_last in links_last: # По каждому поисковому запроса
req_num += 1 # Порядковый номер запроса
for page_num in pages: # По каждой странице поиск.запроса
link = link_first+str(page_num)+link_last # Собираем ссылку на страницу поиска
# Получаем ссылку на картинки и ссылки на сайт:
links_pic,links_to_website, links_yandex = get_links(
parse(link)[0], parse(link)[1])
fl_saved = save_pics(links_pic) # Сохраняем картинку
list_links_to_pics.append(links_pic) # Ссылки прямые на картинку
list_links_to_websites.append(links_to_website) # Ссылки на сайт с картинками
list_links_yandex.append(links_yandex) # Ссылки на похожие картинки
fls_saved.append(fl_saved) # Имя сохраненной картинки
if page_num != pages[-1]:
time.sleep(20) # Пауза между страницами, чтобы не откл.запросы
Так, получили картинки для дальнейшего анализа. Также можно написать парсер выдачи других поисковых систем или сделать поиск по похожим картинкам для увеличения количества изображений.
ПОЛУЧЕНИЕ ТЕКСТОВЫХ ДАННЫХ С ИЗОБРАЖЕНИЙ
Далее, необходимо получить текстовую информацию с картинок. Ниже приведен пример функции для получения текста из изображения:
def get_text():
""" Функция получения текста из изображений """
df['Текст'] = '' # Добавляем колонку текст
os.system(r'nul>texts_photos.txt') # Очищаем файл текстовый
for i, pic in enumerate(pic_names_list):
try:
image = Image.open('Pictures_downloaded/'+pic+'.JPG')
text = pytesseract.image_to_string(
image, lang='rus', config='digits') # Извлекаем цифры из текста
text = re.sub('\s+', ' ', text) # Удаляем абзацы пустые
df['Текст'][i] = text
with open('texts_photos.txt', 'a') as Txt_file:
Txt_file.write('\n'+pic+' '+text) # Записываем текст в txt
except Exception as e:
pass
На выходе получим подобную таблицу:
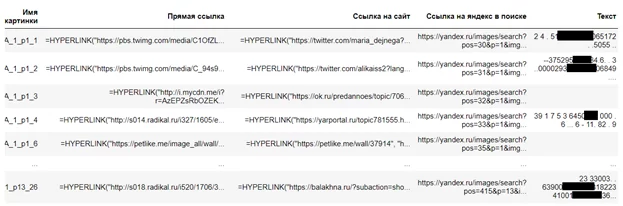
Так, получили текстовую информацию с картинок. Далее, будем искать реквизиты сбербанка. Можно, например, вытянуть с какого-нибудь сайта, где имеются BIN карт сбербанка, все возможные комбинации, а далее искать совпадения в тексте с изображения.
Ниже приведен пример функции поиска номера карты в тексте:
def find_SBER(Texts):
""" Функция поиска наличия реквизитов сбербанка на изображении """
cases = []
for BIN in BINS_Sber: # Получаем регулярку для поика
cases.append(BIN+'\d{12,14}') # БИН 4х-Значный + 12 цифр на карте
for i, Text in enumerate(Texts):
requisites = []
for case in cases: # Ищем в тексте все варианты под Сбер
sber_requisites = re.findall(case, Text) # Ищем номера карты Сбера
if sber_requisites:
requisites.append(sber_requisites)
requisites_ = reshape_list(requisites)
if requisites_ == []:
df['Реквезиты Сбер'][i] = '-'
else:
df['Реквезиты Сбер'][i] = requisites_
Проделав операцию по поиску реквизитов сбербанка, мы сузили круг поиска. Сравнивать картинки будем только между теми, что имеют интересующие нас реквизиты.
ПОИСК ПОТЕНЦИАЛЬНО ФАЛЬСИФИЦИРОВАННЫХ ИЗОБРАЖЕНИЙ
Далее составляется список уникальных пар картинок для сравнения между собой, т.к. для поиска похожих изображений будет использоваться функция opencv cv2.matchTemplate(), которая принимает в аргументы только два изображения. Так же их необходимо предварительно привести к одному размеру.
def image_correlation(pic_name_pairs, folder_path):
""" Функция определения схожести изображений """
corr_list = [] # список с соответствиями пар картинок
for i in range(len(pic_name_pairs)):
pic_names = re.split(' ', pic_name_pairs[i]) # делим пару названий картинок на 2 элемента
# Получаем cv2 изображение Numpy array:
image_1 = cv2.imread(folder_path+pic_names[0]+'.JPG')
image_2 = cv2.imread(folder_path+pic_names[1]+'.JPG')
# Во избежание ошибок по несоотв.размеров, приводим к одному размеру:
# Наименьший X и Y размер из двух картинок:
min_x = min(image_1.shape[0], image_2.shape[0])
min_y = min(image_1.shape[1], image_2.shape[1])
# Меняем размер изображений:
image_1 = resize_c2vimage(image_1, min_x, min_y)
image_2 = resize_c2vimage(image_2, min_x, min_y)
# Соответствие картинок
corr = (cv2.matchTemplate(image_1, image_2, cv2.TM_CCOEFF_NORMED)[0][0])
corr_list.append(corr)
return (corr_list)
В итоге получили список с корреляциями всех пар картинок с реквизитами сбербанка. Далее смотрим на пары с корреляцией выше установленного нами порога. Если реквизиты сбербанка в этой паре картинок разные – заносим в список потенциальных фальсификаций, если одинаковые – пропускаем. На выходе получаем таблицу с потенциально сфальсифицированными картинками и их парами, а также сами изображения.


В результате, по запросам с ключевыми словами можно выявлять мошенничество в благотворительной сфере.