/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 11 мин.
Введение
Для проведения проверки мне необходимо было установить адреса нескольких сотен объектов недвижимости. Проблема в том, что адреса были написаны в разных частях документов, документы имели различные форматы, и сам адрес также мог быть написан разнообразными способами.
Да, существует возможность использовать для данной задачи различные библиотеки и сервисы, но источники данных с информацией об этих объектах должны быть упорядочены и однородны. Можно ли используя минимум ресурсов решать подобные задачи? Можно! Рассмотрим решение на основе Python 3, Pandas и нескольких библиотек для конвертации файлов в датафреймы.
Конечно, удобнее работать с данными, представленными в виде упорядоченных списков адресов, геотэгов и пр. (изображение 1). В нашем случае в структуре адресов:
- использованы различные разделители (точки, запятые, прочие разделительные знаки)
- в строках с адресами присутствовала «мусорная» информация, не относящаяся к адресу
- адрес может был представлен как в полном формате (страна, район/область, населённый пункт, улица, строение, помещение), так и в любом сокращённом (изображение 2)

Относительно небольшого набора документов ситуация не представляется проблемной, все нужные данные можно собрать вручную, унифицировать разделители и обрезать всё лишнее. Но что если таких файлов много?
Извлечение информации
Итак, у нас в наличии есть набор файлов, в которых поля с адресами, расположены в различных частях документа. При этом, столбцы неоднородны; данные по адресу могут содержаться как в одном столбце, так и в нескольких; в том числе могут отличаться заголовки столбцов; плюс к каждому из них применяются все свойства проблемной структуры, описанные выше. Все эти нюансы усложняют унификацию процесса сбора информации, но мы постараемся собрать данные воедино.
Следующим шагом с помощью обработчиков для различных видов документов (pdf, excel и word) соберём данные в датафреймы. В случае с файлами Excel, можно воспользоваться встроенными функциями библиотеки pandas (ExcelFile, read_excel). Word — файлы так же не доставят особых проблем (функция Document в библиотеке docx). И в первом, и во втором случае понадобятся небольшие «косметические правки» (поля с датами, спецсимволы и т.п.) и в целом, данные будут готовы для обработки. Наибольшего внимания требуют файлы формата PDF. Из-за своей структуры PDF файлы не позволяют перенести данные напрямую, в следствии чего, приходится обрабатывать документ с учётом его разметки, внутренних изображений, блоков и т.п.
import pandas as pd
import tabula
import fitz
import ast
def sort_blocks(blocks):
# упорядочиваем блоки, т.к. их порядок может быть нарушен (особенности разбора pdf файлов)
sorteded_blocks = []
for b in blocks:
x0 = str(int(b["bbox"][0] + 0.99999)).rjust(4, "0")
y0 = str(int(b["bbox"][1] + 0.99999)).rjust(4, "0")
sort_key = y0 + x0
sorteded_blocks.append([sort_key, b])
return [b[1] for b in sorted(sorteded_blocks)]
def sort_lines(lines):
# аналогично блокам поступаем с лайнами
sorted_lines = []
for l in lines:
y0 = str(int(l["bbox"][1] + 0.99999)).rjust(4, "0")
sorted_lines.append([y0, l])
return [l[1] for l in sorted(sorted_lines)]
def sort_spans(spans):
# аналогично блокам поступаем со спэнами
sorted_spans = []
for s in spans:
x0 = str(int(s["bbox"][0] + 0.99999)).rjust(4, "0")
sorted_spans.append([x0, s])
return [s[1] for s in sorted(sorted_spans)]
def get_data_from_pdf_with_fitz(file):
fitz_document = fitz.Document(file)
fitz_document_pages = fitz_document.pageCount
pdf_data = ""
for page_number in range(fitz_document_pages):
# разбиваем pdf файл на подэлементы и далее каждый на составные части
page_data = ""
page = fitz_document.loadPage(page_number)
page_text = page.getText("json")
# страница делится на блоки
page_dict = ast.literal_eval(page_text)
page_blocks = sort_blocks(page_dict["blocks"])
for block in page_blocks:
if "image" not in block.keys():
# блоки на лайны
page_lines = sort_lines(block["lines"])
for line in page_lines:
# лайны на спэны
page_spans = sort_spans(line["spans"])
for span in page_spans:
if page_data.endswith(" ") or span["text"].startswith(" "):
page_data += span["text"]
else:
page_data += " " + span["text"]
page_data += "\n"
pdf_data += page_data + "\n "
return pdf_data
def get_data_from_pdf(file):
pdf_data = get_data_from_pdf_with_fitz(file)
pdf_data = re.sub(r"[\«\»\"]", " ", pdf_data)
pdf_data = re.sub(r"\s+", " ", pdf_data)
try:
dataframe_container = []
dataframes = tabula.read_pdf(pdf_data, lattice=True, stream=True, pages='all', pandas_options={"header": None})
for n, dataframe in enumerate(dataframes):
for k in range(dataframe.shape[0]):
dataframe_container.append(dataframes[n].values[k])
dataframe = pd.DataFrame(df_container)
return dataframe
except Exception as e:
return e
Альтернативный вариант – передать обработку подобных файлов стороннему ПО, например, ABBYY Fine Reader. В целом, результат будет примерно одинаковый и в большинстве случаев удовлетворительный.
Далее необходимо определить, в какой части документа, а точнее в каких столбцах датафреймов находятся адреса. Если структура документа сохраняется и данные остаются без смещений (т.е. все адреса для каждой строчки остаются в искомых столбцах), можно выделять необходимые столбцы отталкиваясь от их имён (тогда предварительно нужно вручную, либо с помощью какого-то алгоритма собрать список наименований подобных столбцов), в противном случае нужно детектировать адреса используя маску поиска, а затем на основе первой найденной ячейки с адресом выделять и весь столбец, полагая, что в нём так же содержатся адреса.
Import re
address_subwords = [
"Адрес", "АО", "аал", "Аобл\.", "аллея", "аул", "б-р", "волость", "въезд", "высел\.", "г\.",
"городок", "дп\.", "д\.", "дор\.", "ж\/д", "жт\.", "заезд", "заимка", "казарма",
"кв-л\.", "км\.", "кольцо", "край", "кп\.", "линия", "мкр\.", "наб\.", "нп\.",
"обл\.", "остров", "окр\.", "парк", "переезд", "пер\.", "п\/р", "платф\.", "пл-ка",
"пл\.", "полустанок", "пгт\.", "п\/ст\.", "п\.ст\.", "п\.", "починок", "п\/о",
"проезд", "промзона", "просек", "проселок", "пр-кт", "проулок", "рп\.", "рзд\.",
"р-н", "Респ\.", "сал", "с\.", "с\/а\.", "с\/о\.", "с\/с\.", "сквер", "сл\.",
"ст-ца", "ст\.", "стр\.", "тер\.", "тракт", "туп\.", "ул\.", "у\.", "уч-к", "х\.", "ш\."
]
# data - строка для обработки
address = [subword for subword in address_subwords if re.search(r'^%s|\s%s' % (subword, subword), str(data).strip(), flags=re.I | re.M)]
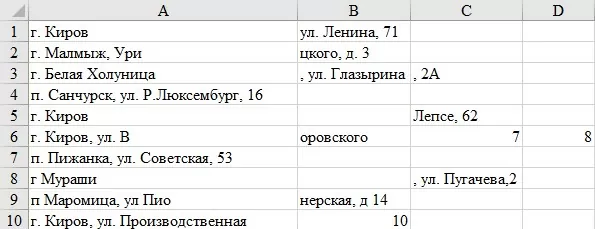
Впрочем, не редко конвертация и/или обработка приводит к ситуации, когда данные смещаются, изменяются. На рисунке (изображение 3) приведен пример документа со смещёнными данными. Данный документ был изначально представлен в виде отсканированного изображения (PDF файл). С помощью программы ABBYY FineReader он был конвертирован в формат excel, но необходимые столбцы с данными были деформированы. В данной ситуации будет недостаточно объединить несколько ключевых столбцов, т.к. заранее неизвестно, что это будут за столбцы, необходимо объединять все ячейки одной строки полностью. Это в свою очередь приведёт к ещё большему загрязнению адреса. Тем не менее на данном этапе у нас в наличии будут списки адресов, которые можно начать обрабатывать.
Обработка информации
Первым шагом для нормализации структуры адреса будет приведение текста к единому стилю. В тексте адреса могут как присутствовать разделители, так и отсутствовать, поэтому базовым вариантом будут считаться адреса без разделителей, очистим от них строку.
Далее начиная от глобальных структур (страна, район, область) будем производить поиск, по ключевым словам, с помощью регулярных выражений, до локальных структур (улица, строение, помещение).
Если ключевые слова не были найдены, значит адрес записан в таком формате, что его невозможно будет отделить от другого текста («мусора»). Тогда мы будем ориентироваться на наличие чисел в строке, означающих строение/помещение, но подобный ход может привести к отбору ненужной информации. Если ключевые слова были найдены, то производится попытка найти ключевые слова рангом ниже (убывание индекса структуры) далее в строке с отсеканием текста из левой части. При этом если следующее ключевое слово не было найдено, но при этом до числового значения (строения/помещения) были слова, проверяется в каком формате они были написаны, т.к. часть адреса, вероятнее всего, будет указана с большой буквы.
import re
def get_address(address):
# address - строка, в которой предположительно находится адрес
address_parts = []
address_index = -1
address_level_n = -1
address_levels_name = ['subject', 'sub_subject', 'settlement', 'street', 'house']
address_levels = [
["респ\.","республика","край","область","обл\.","г\.ф\.з\.","а\.окр\."],
["пос\.","поселение","р-н","район","с\/с","сельсовет"],
["г\.","город","пгт\.","рп\.","кп\.","гп\.","п\.","поселок","аал","арбан","аул","в-ки","выселки","г-к","заимка","з-ка","починок","п-к","киш\.","кишлак","п\.ст\.","ж\/д","м-ко","местечко","деревня","с\.","село","сл\.","ст\.","станция","ст-ца","станица","у\.","улус","х\.","хутор","рзд\.","разъезд","зим\.","зимовье","д\."],
["ал\.","аллея","б-р","бульвар","взв\.","взд\.","въезд","дор\.","дорога","ззд\.","заезд","километр","к-цо","кольцо","лн\.","линия","мгстр\.","магистраль","наб\.","набережная","пер-д","переезд","пер\.","переулок","пл-ка","площадка","пл\.","площадь","пр-кт\.","проспект","проул\.","проулок","рзд\.","разъезд","ряд","с-р","сквер","с-к","спуск","сзд\.","съезд","тракт","туп\.","тупик","ул\.","улица","ш\.","шоссе"],
["влд\.","владение","г-ж","гараж","д\.","дом","двлд\.","домовладение","зд\.","здание","з\/у","участок","кв\.","квартира","ком\.","комната","подв\.","подвал","кот\.","котельная","п-б","погреб","к\.","корпус","офис","пав\.","павильон","помещ\.","помещение","раб\.уч\.","скл\.","склад","соор\.","сооружение","стр\.","строение","торг\.зал\.","цех"]
]
# пытаемся разбить строку на части используя спец-слова и сокращения
# начинаем с верхнего уровня субъектов и спускаемся ниже, если разбивка не получается
for i, level in enumerate(address_levels):
for subword in level:
address_split = re.split(r'%s' % subword, address, 1, flags=re.I | re.M)
if len(address_split) > 1:
clean_subword = re.sub(r'[^\w\.]', '', subword)
# учитывая формат именования верхних уровней, ищем в строке наименование субъекта до ключевого слова
# в противном случае отсекаем часть строки до ключевого слова
if len(address_split[0]) > 0 and i < 2:
address_part_to_append = re.findall(r'[А-Я][^А-Я\d\s]+', address_split[0], flags=re.M)
if len(address_part_to_append) > 0:
address_parts.append(address_part_to_append[-1].strip() + ' ' + clean_subword)
else:
address_split[1] = clean_subword + ' ' + address_split[1].strip()
else:
address_split[1] = clean_subword + ' ' + address_split[1].strip()
address_level_n = i
break
if address_level_n > -1:
break
# в зависимости от разбивки, добавляем предполагаем части адреса к имеющимся, если они имеются
if len(address_split) > 1:
address_parts.extend(address_split[1].split(','))
else:
address_parts.extend(address_split[0].split(','))
# разбиваем строку в поисках улиц, строений, прочих элементов
address_parts_to_split = address_parts
address_parts = []
for address_part in address_parts_to_split:
address_part = address_part.strip()
address_part_split = re.findall(r'(?:[А-Я][^А-Я]+[\s-][А-Я][^А-Я]+)|(?:[А-Я][^А-Я]+)', address_part, flags=re.M)
if len(address_part_split) > 1:
address_parts.extend(address_part_split)
elif len(address_part) > 0:
address_parts.append(address_part)
# поиск обозначения дома и его номера
is_house_finded = False
for house_subword in address_levels[-1]:
house_split = re.split(r'%s' % house_subword, address_parts[-1], 1, flags=re.I | re.M)
clean_house_subword = re.sub(r'[^\w\.]', '', house_subword)
if len(house_split) > 1:
is_house_finded = True
address_parts = address_parts[:-1]
if len(house_split[0]) > 0:
address_parts.append(house_split[0])
address_parts.append(clean_house_subword + ' ' + house_split[1])
# если информация не найдена, добавляем хвост, предполагая, что в нём находится дом
if not is_house_finded:
merged_part = re.search(r'[^\d]\d', address_parts[-1])
if merged_part != None:
n = merged_part.span()[0] + 1
value = address_parts[-1]
address_parts = address_parts[:-1]
address_parts.append(value[:n])
address_parts.append(value[n:])
# собираем данные
dict_address = {}
list_address = list(map(str.strip, address_parts))
for list_address_part in list_address:
if address_level_n < 5:
# ограничиваем размер частей, для избежания больших строк
dict_address[address_levels_name[address_level_n]] = list_address_part[:64]
address_level_n += 1
else:
break
return dict_address
При нахождении числового значения, строка с адресом считается законченной и все данные из правой части отсекаются. Затем все найденные элементы строки собираются в адрес в нормализированном виде. Шаги алгоритма повторяются для каждой строки датафрейма, каждого датафрейма из коллекции.
Кроме описанного алгоритма, я тестово использовал алгоритм, основанный не на ключевых словах, а на формализованном синтаксисе записи адресов в русском языке. Данный алгоритм использует расстояние между символами, расположение больших букв, знаков препинания и числовых значений в конце адреса. В целом работоспособность второго алгоритма оказалась на уровне первого, поэтому в рамках статьи он не обозревается.
Сравнение
Для определения эффективности алгоритма было проведено сравнение с НЛП для поиска и извлечения информации из документов с «плохой» структурой в связке с проектом Natasha. Очевидно, что эффективность последних должна быть выше, но также потребуются данные для обучения, унифицированная структура, приведение к нормальному виду, в то время как описанные в статье алгоритмы работают с необработанными данными.
Основой НЛП для поиска и извлечения информации послужил проект sec-doc-info-extraction. В исходном виде в качестве входных данных он использует html файлы, в которых производится поиск ключевых фраз. Для задачи поиска адресов алгоритм модифицирован — вместо html файлов, обрабатывались excel файлы (соответственно pdf и word документы предварительно сконвертированы в формат excel), а в качестве ключевых слов использовались всё те же элементы структуры адреса. После обучения в целом можно сказать, что скрипт справлялся с поставленной задачей.
Далее, для определения частей адреса внутри строк среди найденных документов, использован метод описанный в статье «Обработка NL адресов для создания эффективных поисковых запросов при помощи набора инструментов проекта Natasha». В отличии от базовой версии Natasha, данный метод позволяет находить большее количество мест за счёт своих доработок (к примеру микрорайоны учитываются как часть адреса). При предварительной обработке данных и приведению их к унифицированному виду (что для тестовой выборки было сделано вручную) задача выполнялась успешно, но в случае с «сырыми» данными, возникала проблема либо с отсечением нужных данных, либо пропуском адреса в принципе, что ожидаемо при использовании «загрязнённых» данных.
Итого, на тестовой выборке получился следующий результат: описанный в статье алгоритм, несмотря на проблемы с полнотой данных, правильно отработал примерно в 70% случаев; в свою очередь модифицированная Natasha с чистыми данными правильно обработала адрес в 95% случаев, но с «плохими» адресами показатель упал до 50% случаев. При этом скорость работы была выше у модификации Natasha (изображение 4).

Вывод:
Несмотря на невысокую скорость работы, зависимость от качества данных, мой алгоритм поиска адресов, при минимальном количестве ресурсов и библиотек, достаточно успешно выполняет эту задачу. А какими способами Вы решаете подобные задачи?