/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 5 мин.
Совсем недавно существовало мнение, что профессия аудитора станет ненужной, исчезнет, что на её смену придут компьютеры. Но, как показало время – это абсолютно неверное суждение. Компьютеры пришли в аудит не как специалисты, они пришли в аудит как инструменты. Профессия аудитора сегодня видоизменяется: на смену долгим расчетам и выявлению аномалий приходит big data и process mining.
В ходе аудита внутрихозяйственной деятельности предприятия нам пришлось решить задачу кластеризации договоров. На начальном этапе нам не было точно известно количество возможных типов договоров, было принято остановиться на четырех.
9200 договоров (PDF формат) были распознаны с помощью оптических технологий, тексты внесены в Excel.
Для того чтобы перейти к кластеризации сначала нужно было подготовить данные: как минимум — оставить только слова, состоящие из русских букв одного регистра, длиной больше трех символов (для исключения предлогов). Делать это вручную, когда в тексте каждого договора по 30000 символов, трудоемко. Но это не все: нам нужно выделить слова, по которым алгоритм сможет провести кластеризацию. Нет смысла давать алгоритму распространенные слова, ровно как не имеет смысла давать уникальные.
Какой у нас есть выход? Python + Jupyter Notebook.
- Обращаемся за помощью к данному языку программирования и его оболочке, импортируем библиотеки:
import pandas as pd
import numpy as np
import re
import collections
2. Загружаем в переменную data файл Excel с помощью библиотеки pandas. Далее выгружаем лист с данными в переменную data_preset.
data = pd.ExcelFile("Договоры.xlsx")
data_preset = data.parse('Лист')
3. С помощью цикла сравниваем нормализованный текст и регулярное выражение, которое выделяет слова, состоящие из русских букв, длиной более трех символов.
list_for_science = []
for words in data_preset.norm_text:
for element in words.split():
if re.match(r'[а-я]{3,}', element):
list_for_science.append(element)
4. Следующий раздел кода – это реализация Term frequency — статистической меры, которая используется для оценки важности слова. Он относится к NLP – natural language processing или же к обработке естественного языка.
tf_text = collections.Counter(list_for_science)
for i in tf_text:
tf_text[i]=(tf_text[i]/float(len(list_for_science)))*100
5. Командой
tf_text.most_common()Мы можем вывести список, упорядоченный по убыванию распространенности слова в тексте:

list_del = []
for i in tf_text:
if(tf_text[i] > 0.066 or tf_text[i] < 0.033):
list_del.append(i)
print('удален')
for i in list_del:
del tf_text[i]
7. Остается завершающий этап — очистка. Берем исходную запись, сравниваем слова в ней с нашим списком слов и, если находим совпадение, то заносим её в рабочий лист. Между записями используем разделитель «1» (прим. процедура выделения нужных слов из записей работает проще чем удаление ненужных):
list_for_new = []
i = 0
for words in data_preset.norm_text:
for element in words.split():
for check in tf_text:
if(element == check):
list_for_new.append(element)
list_for_new.append("1")
i = i+1
8. Теперь данные готовы к процессу кластеризации. Выводим данные в Excel для дальнейшей работы. Открываем файл Excel, вносим в него строки, созданные из списков и сохраняем:
string_remember = ""
workbook = xlsxwriter.Workbook("output.xlsx")
worksheet = workbook.add_worksheet()
i=1
for element1 in list_for_new:
if(element1 == "1"):
print(string_remember)
print(" ")
worksheet.write(i, 1, string_remember)
string_remember = ""
i=i+1
else:
string_remember = string_remember + " " + str(element1)
workbook.close()
9. Приступаем к кластеризации:
list_for_work = []
for words in data_preset.text:
list_for_work.append(words)
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
documents = [TaggedDocument(doc, [i]) for i, doc in enumerate(list_for_work)]
model = Doc2Vec(documents, size=300, workers=4)
10. Обращаемся к ранее созданному файлу Excel и используем метод, позволяющий преобразовать текст в вектор – Doc2vec. Создав векторное представление – подключаем метод k-средних и проводим модель через 11 «эпох» обучения.
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
epochs = 0
while epochs < 11:
model.train(documents, total_examples=model.corpus_count)
epochs=epochs+1
kmeans_model = KMeans(n_clusters=4, init='k-means++', max_iter=100)
X = kmeans_model.fit(model.docvecs.doctag_syn0)
labels=kmeans_model.labels_.tolist()
l = kmeans_model.fit_predict(model.docvecs.doctag_syn0)
pca = PCA(n_components=2).fit(model.docvecs.doctag_syn0)
datapoint = pca.transform(model.docvecs.doctag_syn0)
11. И, наконец, визуализируем:
import matplotlib.pyplot as plt
label1 = ["#FFFF00", "#008000", "#0000FF", "#800080"]
color = [label1[i] for i in labels]
plt.scatter(datapoint[:, 0], datapoint[:, 1], c=color)
centroids = kmeans_model.cluster_centers_
centroidpoint = pca.transform(centroids)
plt.scatter(centroidpoint[:, 0], centroidpoint[:, 1], marker='^', s=150, c='#000000')
plt.show()
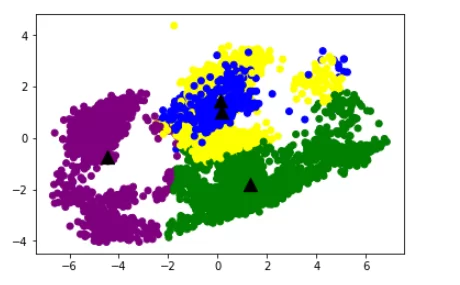
12. Выводим данные:
workbook = xlsxwriter.Workbook("output_new.xlsx")
worksheet = workbook.add_worksheet()
i=1
for words in labels:
worksheet.write(i, 1, words)
i=i+1
workbook.close()
Таким образом, мы решили задачу кластеризации. Как видно из графического представления – два кластера (фиолетовый и зеленый) определились явно, чего нельзя сказать о двух остальных (синий и желтый). Пусть на данном этапе задача пока не выполнена на 100%, но мы смогли выделить необходимые нам договоры, связанные с электронным документооборотом и недвижимостью. В смешанной зоне оказались «невыразительные» договоры: одни по причине сходства признаков, а другие — потому что после очистки данных в них осталось мало информации. С другой стороны — это тоже важный показатель, скорее всего, для обработки достаточно было выделить три кластера. Тем не менее, главное понять ошибки, исправить их и стать лучше.