/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Еще в ноябре 2016 года американская компания Adobe, разработчик программного обеспечения, представила на собственном мероприятии Adobe MAX свой продукт Adobe VoCo. Данное программное обеспечение предназначено для генерации и редактирования аудио, в том числе при помощи 20 минут речи человека может синтезировать похожий на звук голос со всеми стилистическими характеристиками голоса. https://www.youtube.com/watch?v=I3l4XLZ59iw
По этическим соображениям проект был приостановлен.
В то же время росла популярность сверточных нейронных сетей, а также с каждым годом state-of-the-arts решения по части синтеза голоса все выше и выше приближаются к человеческой речи. Немаловажным фактором стала парадигма открытости исходного кода, благодаря которой программисты и математики со всего мира могли улучшать существующие модели, а также придумывать новые способы решения задачи. Конечно, наибольший коммерческий эффект был достигнут в крупных компаниях, таких как Google, Amazon, Facebook* и Yandex (!).
Вот тут начинается самое интересное… Широкоизвестный факт, что русский язык принадлежит к другой лексической группе, нежели английский язык. Разница алфавита: кириллица и латинский алфавит имеют лишь некоторую буквенную схожесть, разница фонологических систем: произношения и интонация, порождаемые в том числе разным количеством гласных звуков, наличие дифтонгов (два звука произносятся как один), все это наталкивает на мысль, что и подходы к воссозданию речи человека должны отличаться, но так ли это? На деле оказалось, что решения, основанные на сверточных нейросетях устойчивы к языку, над которым вы работаете. Например: обучив нейросеть на датасете, состоящим из русской речи и попытавшись воссоздать голос, произносящий что-то на английском, на выходе получится английская речь с русским акцентом, также это сработает и в обратную сторону. Таким образом, учитывая, что все модели канонически создаются для английского языка, это также незамедлительно двигает развитие и для решений, опирающихся на русскую или любую другую речь.
В июне 2019 года на GitHub появился открытый проект с возможностью голосового клонирования Real-Time-Voice-Cloning, а также, спустя два месяца, появилась его адаптация с предобученными моделями для русской речи – Multi-Tacotron-Voice-Cloning и habr. Это решение мы и решили протестировать.
Для этого нужно было подготовить размеченный датасет, состоящий из дорожек с голосом человека и текста с этих дорожек. Сначала мы читали книгу под диктофон примерно 4 часа. Потом разбили по тишине запись на маленькие файлы длинной от 2-х до 30-ти секунд, выбросив, тем самым, лишний мусор. Для этих файлов мы получили текстовое представление с помощью API от Google. Таким образом, получили размеченный датасет и дообучили на нем модель.
### Тренировка кодировщика
python encoder_preprocess.py d --datasets YourDataset # Обработка данных
pip install visdom # Открыть в новой вкладке терминала для визуализации процесса
visdom
python encoder_train.py pretrained_your_dataset # Тренировка кодировщика
### Тренировка модели синтеза
# В зависимости от ОС поменять путь в директорию
# change synthesizer/preprocess.py (line 108; input_dirs = […])
# change synthesizer/preprocess.py (line 157; split(“…”))
python synthesizer_preprocess_audio.py # Создание обработанного звука и спектограмм
# В директории найти файл pretrained_default.pt, скопировать его и переименовать, дообучая модель
python synthesizer_preprocess_embeds.py --encoder_model_fpath encoder/saved_models/pretrained_your_dataset.pt # Кодирование звука (получение признаков голоса)
python synthesizer_train.py pretrained_your_dataset # Тренировка синтезатора
### Преобразование спектограммы в звук
python vocoder_preprocess.py d --model_dir “synthesizer/saved_models/logs-pretrained/” # Синтез спектограмм
python vocoder_train.py pretrained_your_dataset d # Тренировка вокодера
На дообучение ушло примерно полутора суток. В результате мы получили поддельный голос, схожий с оригиналом по метрике, однако обладающий картавостью и заторможенностью. Но, в целом, результат был более чем удовлетворительный и мы видим потенциал данной технологии.
Первое — это, с целью уменьшения затрат на дообучение моделей можно оценить минимально необходимый объем обучающей выборки для успешного прохождения аутентификации, мы эмпирически выбрали объем в 4 часа, но учитывая полученный высокий итоговый скорбал, его, наверное, можно значительно сократить.
Второе – приложить усилия для приближения времени генерации фейк-голоса к работе в реальном времени. Это требует более мощного оборудования и возможно других моделей. Но, это на наш взгляд при быстром развитии технологий — дело очень недалекого будущего. Осенью 2019 года компания Screenlife Тимура Бекмамбетова, совместно с разработчиком HR-сервиса «Робот Вера» запустили проект Vera Voice. Уже в ноябре они показали пример работы робота, синтезировав речь известных личностей.
В данный момент, исходя из рисков этой технологии, создатели проекта привлекают партнеров и не разглашают техническую сторону своего проекта.
Цитата:
«Мы понимаем, что данные технологии могут использоваться как во благо, так и во вред, поэтому делаем все возможное, чтобы построить легальную и прозрачную основу для их развития.Приватность, авторские права и этичность являются для нас основными принципами»
Таким образом, человечеству уже доступны методы для создания голосового клона любого человека, при наличие его голосовых слепков. Пока данной технологией владеют только организации, имеющие целый штат специалистов, а также не распространяющие свои решения в свободном доступе. Простому обывателю точные программные продукты недоступны, за исключением сырых технологий в открытом доступе, одна из которых приведена в статье. Регулирование применения подобных технологий открыто обсуждается в правительстве РФ и в других странах, однако на сегодняшний день в мировой практике таких законов не существует.
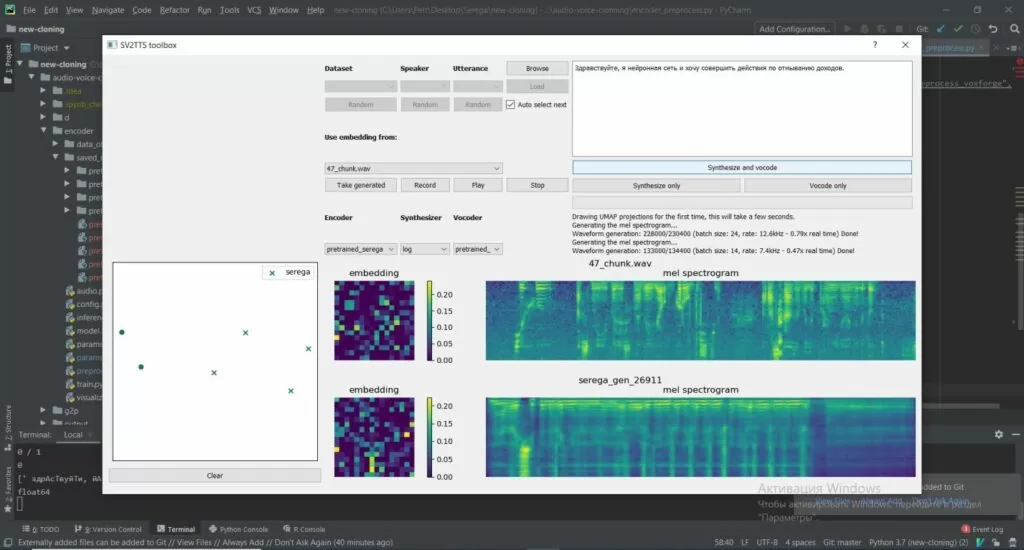
Предложенная нами технология может быть применена для аудита систем, использующих биометрическую голосовую аутентификацию, с ее помощью можно проверить на устойчивость к мошенническим атакам модель, которую использует ваша организация для распознавания голоса. А вот так выглядит пример работы кода:
* — Признана экстремистской организацией и запрещена на территории Российской Федерации