/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
В 1913 году Генри Форд запустил первый сборочный конвейер по сборке генераторов. Сборка была разложена на 85 независимых друг от друга операций, при этом выполнялись они условно параллельно. Как итог: сокращение сборки генератора с 20 до 5 минут.
Принцип готовый промежуточный результат передается дальше по конвейеру был применен в специальных функциях Oracle.
Конвейерная функция или же pipelined-функция — это табличная функция, которая поставляет свои результаты в вызывающую среду по мере их подготовки, не материализуя весь результирующий набор. Тем самым как плюсы можно выделить:
-Ускорение SQL-запросов и PL/SQL-кода (в некоторых случаях)
-Уменьшение затрат ресурсов PGA при материализации результата
Синтаксис
create or replace function func_name(…) return тип_коллекция
pipelined
is
begin
… цикл …
pipe row (элемент_коллекции);
…
end;
От обычной функции отличается ключевой конструкцией Pipelined, обязательно должна возвращаться коллекция, её заполнение происходит по мере выполнения через pipe row, в котором указывается элемент коллекции.
Важный момент: Результаты должны отдаваться итеративно в цикле. Это может быть, например, проход по курсору (так обычно бывает при обработке входных данных), либо просто цикл.
Как только программа достигает участка с pipe row результат передается в вызывающую среду, при этом вызывающая сторона уже может выполнять свои действия с этой строкой. Проведем аналогия с конвейером Генри Форда. Пока готовится новая деталь предыдущая деталь уже отдана по конвейеру в вызывающую среду и уже принимает участие в последующей сборке.
Перейдём к практике. Посмотрим, как создаются конвейерные функции и как получить из них результат. Создаём объект их 2 полей, он будет элементом коллекции. Саму коллекцию t_person и конвейерную функцию get_persons. Заметим, что в качестве результата функции указана коллекция t_persons, а в инструкции создается элемент коллекции t_person, который сразу же отдается в вызывающую среду. Используются эти функции точно так же, как обычные табличные функции oracle (До 12 версии, с указанием ключевого слова table, после 12 включительно).
----- Пример 1. Pipelined функции с объектами
-- объект
create or replace type t_person is object(
id number,
full_name varchar2(200 char)
);
/
-- коллекция объектов
create or replace type t_persons is table of t_person;
/
-- конвейерная функция
create or replace function get_persons return t_persons
pipelined
is
begin
-- генерируем 10 строк
for i in 1..10 loop
-- возвращаем результат
pipe row(t_person(i, 'full_name_'||i));
end loop;
end;
/
-- вызываем (<12)
select * from table(get_persons());
-- вызываем (12+)
select * from get_persons();
Далее, создадим коллекцию чисел t_numbers, через нее мы будем возвращать результат. И 2 функции: обычную delay_simple и конвейерную delay_pipelined. Они обе генерируют n строчек в обычном цикле. На каждой строчке функции спят указанное время (по умолчанию 1 сек.) для этого используется пакет dbms_session (dbms_lock для oracle 11). Теперь рассмотрим отличия. В обычной функции результат сначала добавляется в коллекцию, в конце коллекции возвращается как результат выполнения. В конвейерной функции результат возвращается через команду pipe row, сразу как только оно было получено. Это легко проверить если вызвать её в sql запросе, для получения строки с результатом.
------ Объекты для примеров
-- Создаем коллекцию
create or replace type t_numbers is table of number(10);
/
---- Обычная процедура
create or replace function delay_simple(p_count number := 5, p_delay_sec number := 1) return t_numbers
is
v_out t_numbers := t_numbers();
begin
-- генерируем N строк
for i in 1..p_count
loop
dbms_session.sleep(p_delay_sec); -- спим p_delay сек. dbms_lock для Oracle 11
v_out.extend(1);
v_out(v_out.last) := i;
end loop;
return v_out; -- вернуть весь результат
end;
/
---- Конвейерная процедура
create or replace function delay_pipelined(p_count number := 5, p_delay_sec number := 1) return t_numbers
PIPELINED
is
begin
-- генерируем N строк
for i in 1..p_count
loop
dbms_session.sleep(p_delay_sec); -- спим p_delay сек. dbms_lock для Oracle 11
PIPE ROW(i);-- возврат строки сразу
end loop;
end;
На 2 примере продемонстрирую основное свойство возврата результата по мере его подготовки.
Создаём вспомогательную функцию get_actual_dtime. Функционал простой: в автономной транзакции получается текущее время на момент вызова и возвращается в вызывающую среду. Почему же нельзя использовать sysdate? Потому что sysdate вычисляется в момент старта запроса. А нам нужно актуальное время на момент получения строчки, а это можно сделать только через автономную транзакцию.
-------- Пример 2. Основное свойство pipelined-функции
-- функция для получения времени вне зависимости от основного запроса
create or replace function get_actual_dtime return date
is
pragma autonomous_transaction;
begin
commit;
return sysdate;
end;
/
-- Заполняем таблицу из обычной функции
select 'delay_simple', value(t), get_actual_dtime()
from table(delay_simple()) t;
-- Заполняем таблицу из конвейерной функции
select 'pipelined', value(t), get_actual_dtime()
from table(delay_pipelined()) t;
Выполним запрос для простой функции:
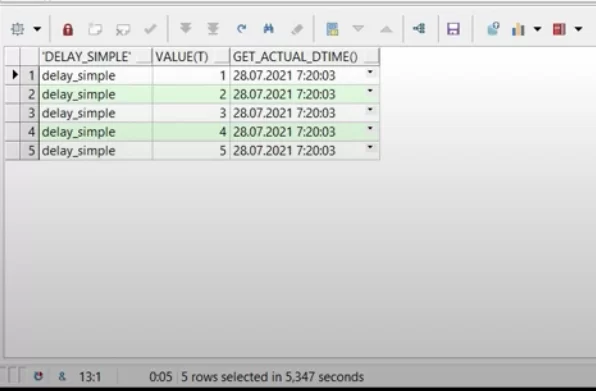
Функция delay_simple формирует коллекцию и за один раз возвращает её.
Выполним запрос для конвейерной функции:
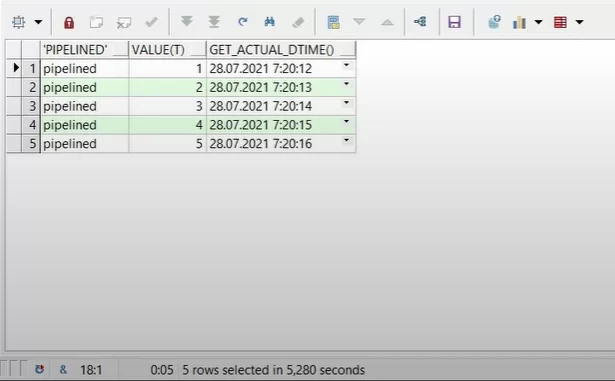
Время возврата результата для каждой строчки разное и различается на 1 секунду.
Посмотрим, как это можно использовать в sql.
Пример 3.1
-------- Пример 3. Использование в SQL
------ 3.1. Без ограничений (выполнятся одинаково за 5 сек)
-- обычная
select * from delay_simple(p_count => 5);
-- конвейерная
select * from delay_pipelined(p_count => 5);
------ 3.2. Ограничение по количеству строк через rownum
-- обычная (выполняется 5 сек)
select *
from table(delay_simple(p_count => 5)) t
where rownum <= 2;
-- конвейерная (выполняется 2 сек)
select *
from table(delay_pipelined(p_count => 5)) t
where rownum <= 2;
------ 3.3. Ограничение по какому-то значению
-- обычная (выполняется 5 сек)
select *
from table(delay_simple(p_count => 5)) t
where value(t) in (1,3);
-- конвейерная (выполняется 5 сек)
select *
from table(delay_simple(p_count => 5)) t
where value(t) in (1,3);
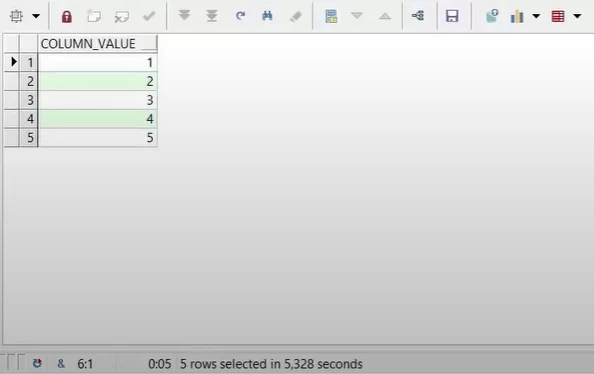
Пример 3.1 простой вызов функции без фильтрации.
Простая функция:
Конвейерная функция:
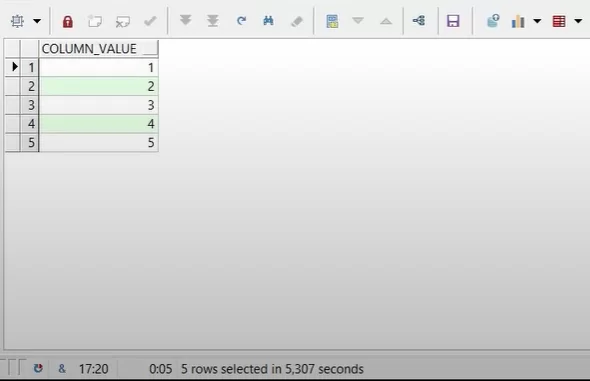
Разница не очень очевидна.
Пример 3.2 Вызов функции с ограничением количества строк.
Обычная функция:
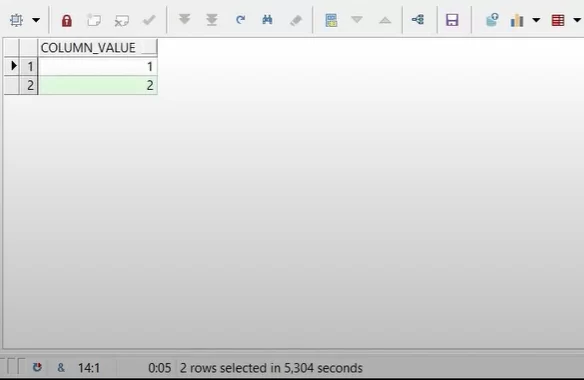
Конвейерная функция:
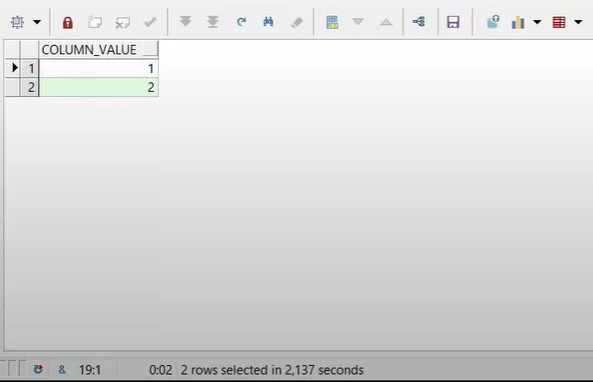
Теперь разница более очевидна. Конвейерной функции нет необходимости выдавать все 5 строчек, если мы уже получили результат.
Пример 3.3 Вызов функции с фильтрации результата с более сложным условием.
Простая функция:
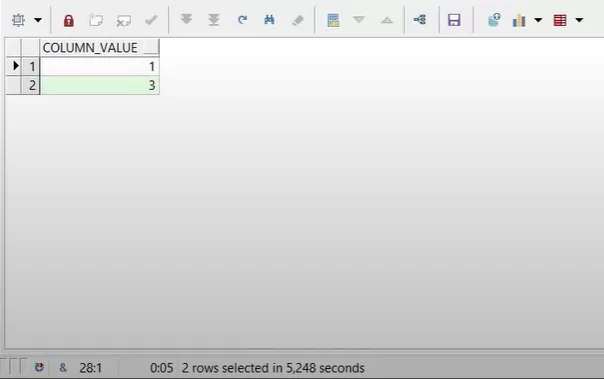
Конвейерная функция:
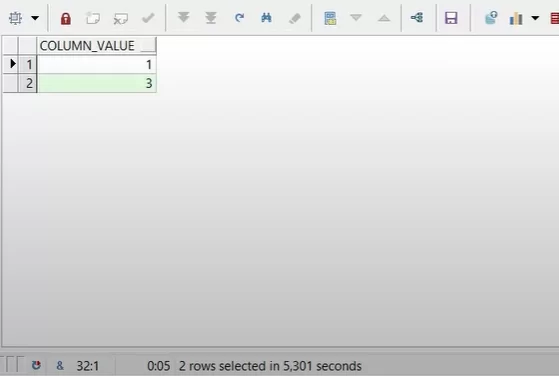
В этом кейсе конвейерная функция вела себя как обычная. Все просто: чтобы отфильтровать по условию in (1,3) нужно получить весь результат работы функции. Т.к мы не знаем какие элементы в коллекции будут до того как будет получен результат.
Теперь посмотрим пример с PGA при генерации больших коллекций. Для замера использования памяти создадим функцию get_session_pga. Выполним 2 теста для 2 процедур. Входные параметры миллион элементов коллекции и 0 сек. Задержки.
Код:
--------- Пример 4. Использование PGA
-- Получение текущего использования PGA
create or replace function get_session_pga return number as
v_pga_size number;
begin
select sum(round(s.value / 1024))
into v_pga_size
from v$sesstat s
,v$statname n
where s.statistic# = n.statistic#
and sid = sys_context('USERENV', 'SID');
return v_pga_size;
end;
/
--- тест delay_simple
declare
p1 number;
p2 number;
v_cnt number;
begin
p1 := get_session_pga();
select count(1) into v_cnt
from table(delay_simple(1e6, 0));
p2 := get_session_pga();
dbms_output.put_line('PGA usage simple: '||round((p2-p1)/1024,2)||' Kb');
end;
/
--- тест delay_pipelined
declare
p1 number;
p2 number;
v_cnt number;
begin
p1 := get_session_pga();
select count(1) into v_cnt
from table(delay_pipelined(1e6, 0));
p2 := get_session_pga();
dbms_output.put_line('PGA usage pipelined: '||round((p2-p1)/1024,2)||' Kb');
end;
/
Результат:
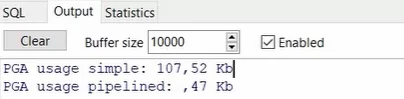
Это небольшие цифры, но когда мы будем работать с объектами, которые будут содержать большие текстовые поля, то разница будет большой. С преимуществом Pipelined-функции.