/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
В ходе исследовательских проектов с применением NLP-моделей возникает необходимость извлечь текст из всех доступных видов файлов. Для некоторых форматов, таких как .docx (Word-файлы) или .xlsx (Excel-файлы) существуют удобные модули для языка Python, выполняющие всю работу одной строкой. С форматом .pdf могут возникнуть некоторые трудности: иногда документ содержит текст и легко читаем (ниже мы рассмотрим, как это сделать), но иногда он состоит из изображений, сканов документов и, соответственно, возникает необходимость их распознать.
Есть несколько способов решения данной задачи.
Воспользоваться существующими платными продуктами, например, ABBYY FineReader, способным отсканировать и распознать текст на изображениях в pdf-документе, добавив новый текстовый слой. Останется только извлечь распознанный текст в txt-файл, об этом будет сказано ниже в шаге 2.1.
Распознать содержимое документа с помощью OCR-модулей языка Python, например, EasyOCR. Немного об описании данного инструмента.
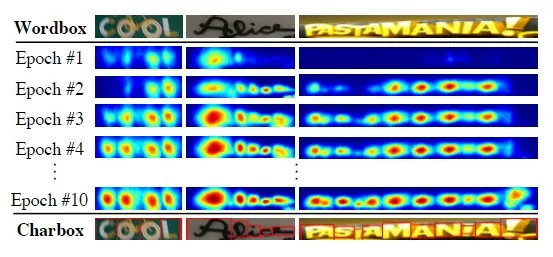
- Сначала стоит задача детекции участков изображения с текстом. На данном этапе используется модель CRAFT (Character Region Awareness for Text Detection, Youngmin et al., 2019). Основой сети является свёрточная VGG-16. Модель вычисляет region score (вероятность что данный пиксель находится в центре некоторой буквы) и affinity score (вероятность что данный пиксель находится посередине между несколькими соседними буквами). Обучение производилось с целью минимизации ошибок предсказания обоих коэффициентов (affinity и region).
2. Следующая задача – распознавание букв на участках изображения. Для этой цели используется CRNN (An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Sense Text Recognition, Baoguang et al., 2015). Название CRNN происходит от Convolutional Recurrent Neural Network, то есть в сети присутствуют как свёрточные, так и рекуррентные слои. Разберёмся подробнее в их назначении. Сначала из исходного изображения, поданного на вход, выделяются различные признаки (фичи) при помощи свёрточных слоёв (см. рисунок 2).
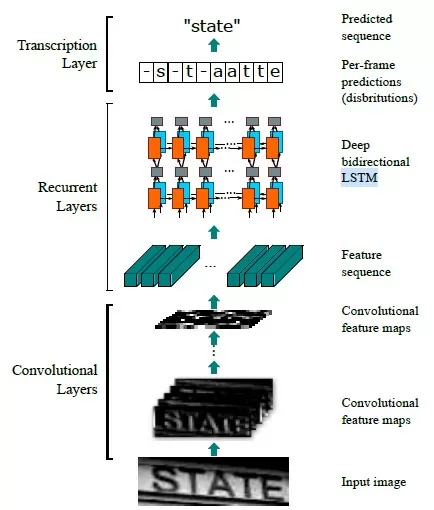
Затем в реккурентной части сети (содержащей LSTM-блоки) производится присвоение лейблов (в данном случае букв алфавита) различным частям изображения. На третьем этапе из полученной последовательности лейблов формируется выходная строка. В некоторых случаях может использоваться словарь слов языка для проверки корректности вывода.
Итак, у нас есть pdf-документ и нам необходимо извлечь из него текст.
Шаг 1. Определение типа входного pdf-файла
Сначала нужно провести проверку, является ли он читаемым документом, то есть находится ли внутри скан/изображение, нуждающееся в распознании. Для этого необходимо проверить каждую страницу на наличие свойства font.
В данном случае использован модуль pdfminer:
from pdfminer.pdfpage import PDFPage
def is_pdf_image(fname):
searchable_pages = [] # создадим два листа для хранения индексов читаемых
non_searchable_pages = [] # и нечитаемых страниц
page_num = 0
with open(fname, 'rb') as infile:
for page in PDFPage.get_pages(infile):
page_num += 1
if 'Font' in page.resources.keys(): # только читаемые страницы имеют атрибут ‘Font’
searchable_pages.append(page_num)
else:
non_searchable_pages.append(page_num)
if page_num > 0:
if len(searchable_pages) == 0:
return 'image'
elif len(non_searchable_pages) == 0:
return 'text'
else:
return 'mix' # при необходимости можно вернуть индексы страниц для обработки
else:
return('Not a valid document')
Теперь, в зависимости от результата, перейдём к шагу 2.1 или 2.2:
Шаг 2.1 Извлечение текста из pdf-документа, содержащего текст.
Для документов с текстом остается пройтись по каждой странице из извлечь текст:
arsrcmgr = PDFResourceManager()
retstr = StringIO()
laparams = LAParams()
device = TextConverter(rsrcmgr, retstr, laparams=laparams) # создаем служебные объекты
fp = open(path, 'rb')
interpreter = PDFPageInterpreter(rsrcmgr, device) # создаем служебные объекты
caching = True
pagenos=set()
for page in PDFPage.get_pages(fp, pagenos,caching=caching, check_extractable=True):
interpreter.process_page(page) # постраничная обработка
text = retstr.getvalue()
text = text.replace('\n', ' ') # опциональное удаление управляющих символов
fp.close()
device.close()
retstr.close()
Шаг 2.2 Извлечение текста из pdf-документа, содержащего изображения.
Для документов с изображениями сначала загрузим их для обработки, я использую для этого модуль fitz: foc = fitz.open(path). Перед распознаванием хорошей практикой является предобработка при помощи модуля OpenCV. Рекомендуется несколько преобразований:
- Увеличить разрешение:
img = cv2.resize(img, None, fx=1.2, fy=1.2, interpolation=cv2.INTER_CUBIC)2. Преобразовать в черно-белый формат:
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)3. Применить размытие:
kernel = np.ones((1, 1), np.uint8)
img = cv2.dilate(img, kernel, iterations=1)
img = cv2.erode(img, kernel, iterations=1)
4. Отфильтровать пиксели по яркости (здесь множество вариантов):
cv2.threshold(cv2.bilateralFilter(img, 5, 75, 75), 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)[1]
cv2.threshold(cv2.medianBlur(img, 3), 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)[1]
cv2.adaptiveThreshold(cv2.bilateralFilter(img, 9, 75, 75), 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 31, 2)
cv2.adaptiveThreshold(cv2.medianBlur(img, 3), 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 31, 2)
После предварительной обработки инициализируем объект-ридер из EasyOCR указав языки для распознавания:
reader = easyocr.Reader(['ru', 'en'])Теперь для каждого изображения в документе произведем распознавание:
result = reader.readtext(img)Результат содержит как сам текст, так и его координаты, и уверенность модели.
for j, res in enumerate(result):
bboxes = res[0]
text = res[1]
score = res[2]
temp_str += ' '+text

Как у объекта Reader, так и у метода readtext достаточно много параметров, советую ознакомиться с документацией. Можно настроить минимальную уверенность модели в зависимости от качества изображений, есть специальная опция для обработки повернутых документов.
Теперь осталось только обработать все изображения и сохранить результат. Скорость работы невыдающаяся — для меня это примерно минута на документ из 10 страниц, но с использованием многопоточности или, оставив обработку на ночное время, можно обработать все документы. Удачи!