/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
ИИ в общественном восприятии уже не слышится как нечто магическое. Успешные проекты ИИ основаны на детальном понимании требований собственной отрасли и собственных клиентов. Требуется обсуждение между специалистами и ИТ-отделами, а также грамотной оценки технологий и их возможностей. Являются результатом реализованных ИТ-проектов. Такие системы также должны разрабатывать, тестировать, внедрять и адаптировать специалисты. Чтобы искусственный интеллект работал, мы, люди, должны продолжать напрягать свои собственные умы.
Человеческий интеллект имеет важное значение для развития совершенно нового типа систем, как они сейчас возникают. Искусственный интеллект при этом является лишь одним из драйверов развития.
Обработка естественного языка Natural Language Processing (NLP) — еще одна важная часть искусственного интеллекта. Тут речь идет об обработке текстов, а не языка. Методом NLP анализируются тексты глубже.
Одним из наиболее распространенных случаев использования для NLP является поиск в Интернете: каждый раз, когда вы ищете что-то через Google или Яндекс, вы используете данные соответствующей системы.
Чатботы работают очень аналогичным образом: они интегрированы в другие чат-программы и анализируют, как пишет ваш пользователь. При определенных наборах ключей бот в итоге выдает конечный результат. Тот же принцип применяют и умные голосовые помощники, такие как Siri и Алиса, которые «активируются» при вызове своего имени.
NLTK-ведущая платформа для создания программ на Python для работы с данными на человеческом языке. Он обеспечивает простые в использовании интерфейсы библиотек NLP.
Пример на Python, который вы можете сделать с NLTK
Маркировать и помечать текст:
>>> import nltk
>>> sentence = """At eight o'clock on Thursday morning
... Arthur didn't feel very good."""
>>> tokens = nltk.word_tokenize(sentence)
>>> tokens
['At', 'eight', "o'clock", 'on', 'Thursday', 'morning',
'Arthur', 'did', "n't", 'feel', 'very', 'good', '.']
>>> tagged = nltk.pos_tag(tokens)
>>> tagged[0:6]
[('At', 'IN'), ('eight', 'CD'), ("o'clock", 'JJ'), ('on', 'IN'),
('Thursday', 'NNP'), ('morning', 'NN')]
Идентификация имен существительных:
>>> entities = nltk.chunk.ne_chunk(tagged)
>>> entities
Tree('S', [('At', 'IN'), ('eight', 'CD'), ("o'clock", 'JJ'),
('on', 'IN'), ('Thursday', 'NNP'), ('morning', 'NN'),
Tree('PERSON', [('Arthur', 'NNP')]),
('did', 'VBD'), ("n't", 'RB'), ('feel', 'VB'),
('very', 'RB'), ('good', 'JJ'), ('.', '.')])
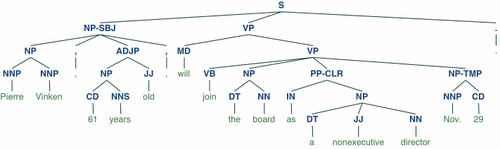
Отображение дерева анализа:
>>> from nltk.corpus import treebank
>>> t = treebank.parsed_sents('wsj_0001.mrg')[0]
>>> .draw()
Кроме того, NLP используется во многих других областях. Например, техника помогает кадровым агентствам просеивать резюме для подходящих кандидатов. Кроме того, обнаружение спама или сентиментальный анализ работают с обработкой естественного языка.
Распознавание адреса и имени в свободном тексте очень сложно сделать машинным путем программирования, поскольку они слишком сложны. На данный момент обработка естественного языка помогает извлекать компоненты предложения в качестве данных из текстового контекста. Для этого необходимо обучить конкретную модель, оптимизированную для условий в текстах перевода и способную распознавать эти данные.