/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
В качестве примера мы будем использовать сайт youla.ru. Задача – выгрузить 500 объявлений для формирования датасета, который нужен для реализации AI проекта.
Зайдём на главную страницу сайта и оценим ситуацию. На главной сразу отображается только 64 объявления, при прокрутке до низа страницы подгружается ещё 60 и т.д. Стоит заметить, что это уже осложнило бы задачу при парсинге через html.
Открываем инструменты разработчика, встроенные в браузер (F12). Нас интересует вкладка Сеть/Network. Переключаем фильтр на XHR и видим следующую картину.
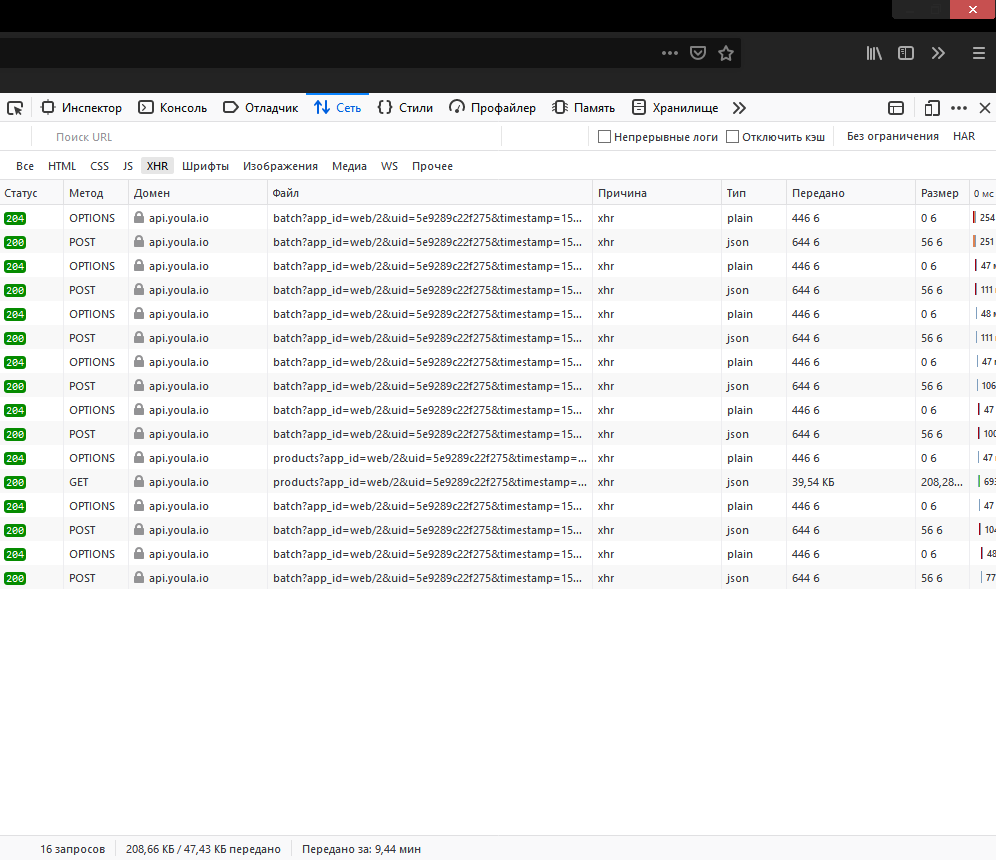
Что отсюда можно понять? Как минимум, что API у сайта есть и он им активно пользуется. Теперь нужно просмотреть все эти обращения к API и найти нужные нам. Для этого щёлкаем по каждому и в информации о запросе нажимаем на Ответ. Перебрав несколько, мы находим то, что нам нужно — запрос, в ответ на который сервер отправляет массив объявлений в json.
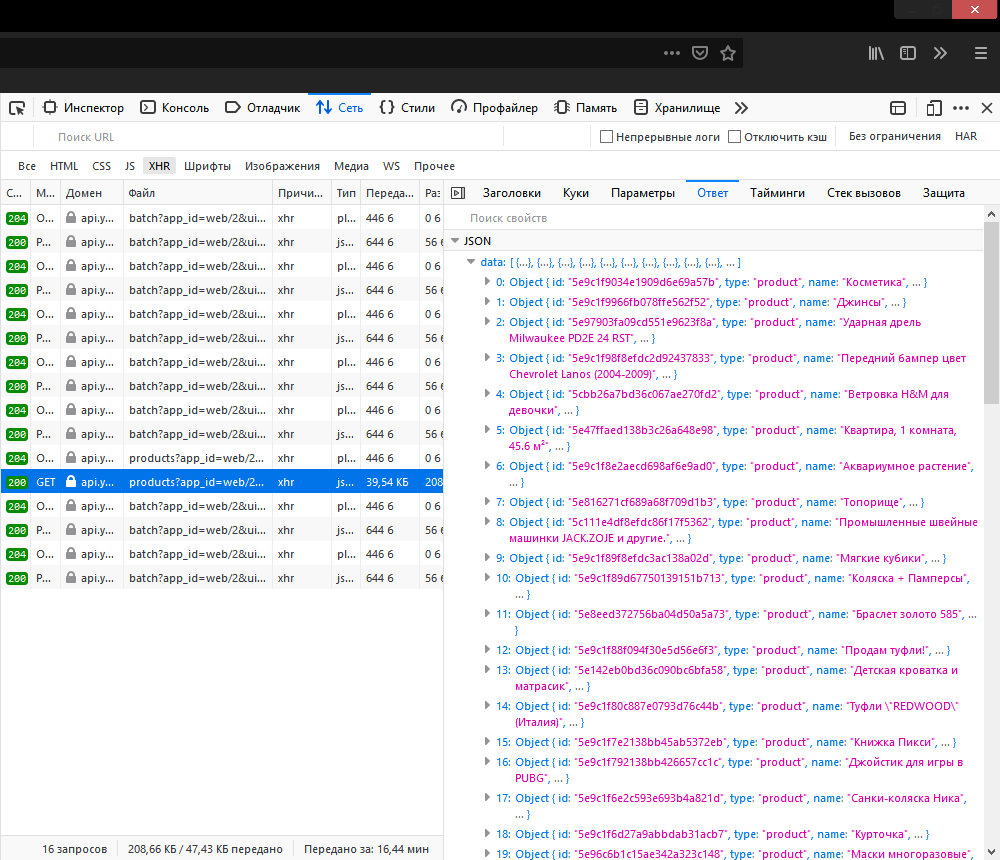
Переходим во вкладку Куки и проверяем, передаётся ли через них какая-то информация для API (для этого сайта они пустые). Затем идём во вкладку Заголовки. Тут нас интересует сам URL запроса и его заголовки. Заголовки нужны для того, чтобы сервер не отказал в доступе по причине отсутствия User-Agent и прочей важной для него информации, а URL разберём далее.
URL запроса:
https://api.youla.io/api/v1/products?app_id=web%2F2&uid=5e9289c22f275×tamp=1586661833629&limit=60&features=banners%2Cserp_id&view_type=tileПроанализируем его параметры и определим их назначение.
“app_id=web%2F2” – вероятно, отвечает за идентификацию платформы, с которой был произведён запрос (сайт/приложение).
“uid=5e9289c22f275” – идентификатор пользователя.
“timestamp=1586661833629” – UNIX time.
“limit=60” – количество объявлений для загрузки из базы.
“features=banners%2Cserp_id” и “view_type=tile” – вероятно, регулирует количество получаемой от сервера информации для необходимого типа отображения на странице.
Теперь у нас есть вся информация, необходимая для выполнения поставленной задачи. Осталось только расчехлить python и написать небольшой скрипт, который будет делать запрос к API, а в ответ получать необходимые данные.
import requests
import json
from time import time
headers = {'Host': 'api.youla.io',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0',
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'ru-RU,ru;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding': 'gzip, deflate, br',
'X-Youla-Splits': '8a=5|8b=6|8c=0|8m=0|16a=0|16b=0|64a=7|64b=0|100d=0',
'Origin': 'https://youla.ru',
'Referer': 'https://youla.ru',
'Connection': 'keep-alive'}
# Информацию берем из URL запроса
app_id = 'web%2F2'
uid = 'e928ad7c22f2'
timestamp = str(int(time()))
limit = '500'
features = 'banners%2Cserp_id'
view_type = 'tile'
url = 'https://api.youla.io/api/v1/products?app_id=' + app_id + '&uid=' + uid + '×tamp=' + timestamp + '&limit=' + limit + '&features=' + features + '&view_type=' + view_type
r = requests.get(url, headers=headers)
# Объект, содержащий информацию о 500 объявлениях с сайта
data = json.loads(r.text)
Результат работы данного скрипта в переменной data объект, содержащий информацию о 500-а объявлениях с сайта. Полученную таким образом информацию можно уже использовать для формирования датасетов.