/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Ссылка на запись вебинара и ответы на вопросы по этой теме — будут размещены сегодня на нашем сайте
Вчера мы уже рассматривали работу с RSS-каналом «Сейчас.ру» — ссылка. Сегодня поговорим о других крупные сайтах, таких как — Коммерсант, Лента.ру, Вести.
В связи с ценностью данных для использования их в машинном обучении и других сферах, парсинг (от англ. parsing — разбор, анализ) является важным процессом для сбора информации. Помимо парсинга определенных сайтов, иногда возникает задача парсить сразу большое количество разных источников. Хороший способ для этого — RSS ленты. RSS (от англ. Rich Site Summary — обогащённая сводка сайта) — семейство XML-форматов, предназначенных для описания лент новостей, анонсов статей, изменений в блогах и т. п.
Парсер, описанный в этой статье, написан на языке программирования Python с использованием библиотеки feedparser, предназначенной именно для парсинга новостных лент. Помимо этого, понадобятся библиотека pandasдля работы с датасетами, csv для сохранения результатов в csv формате и модульre для использования регулярных выражений. Импортируем их:
import feedparser
import csv
import pandas as pd
import reСначала, я указываю входные данные, которые потребуются для парсинга: словарь новостных RSS-лент, которые я буду использовать для поиска новостей; путь к файлам (путь файла для всех новостей, путь файла для определенных новостей); вектора, по которым ищутся определенные новости (в примере будут использоваться два вектора, поиск будет проходить при наличии двух векторов в тексте (логическое И). Сами вектора разбиты прямым слэшом ‘|’, что значит логическое ИЛИ, то есть поиск осуществляется по одному из слов первого вектора И одного из слов второго вектора). Определим входные данные:
our_feeds = {'Kommersant': 'https://www.kommersant.ru/RSS/news.xml',
'Lenta.ru': 'https://lenta.ru/rss/',
'Vesti': 'https://www.vesti.ru/vesti.rss'} #пример словаря RSS-лент
#русскоязычных источников
f_all_news = 'allnews23march.csv'
f_certain_news = 'certainnews23march.csv' #пример пути файла
vector1 = 'ДолЛАР|РубЛ|ЕвРО' #пример таргетов
vector2 = 'ЦБ|СбЕРбАНК|курс'Дальше определяем функцию, которая получает на вход ссылка RSS-ленты и возвращает обработанную ссылку через библиотеку feedparser. Затем определяем четыре функции, которые нужны для получения заголовков, описания, ссылки на источник и даты публикации новости. Вы можете увеличить список при желании, я выбрал самые стандартные теги. Проблема в том, что существуют разные RSS-ленты, где-то не прописан определенный тег, например тег категории новости. Четыре тега выше обычно есть во всех RSS-лентах. Для этого необходимо совершить итерацию по всем тегам, обычно они спрятаны в items, а после взять интересующие нас теги: title, description, link, published. Будем добавлять все данные в изначально пустые списки.
def check_url(url_feed): #функция получает линк на рсс ленту, возвращает
# распаршенную ленту с помощью feedpaeser
return feedparser.parse(url_feed)
def getHeadlines(url_feed): #функция для получения заголовков новости
headlines = []
lenta = check_url (url_feed)
for item_of_news in lenta['items']:
headlines.append(item_of_news ['title'])
return headlines
def getDescriptions(url_feed): #функция для получения описания новости
descriptions = []
lenta = check_url(url_feed)
for item_of_news in lenta['items']:
descriptions.append(item_of_news ['description'])
return descriptions
def getLinks(url_feed): #функция для получения ссылки на источник новости
links = []
lenta = check_url(url_feed)
for item_of_news in lenta['items']:
links.append(item_of_news ['link'])
return links
def getDates(url_feed): #функция для получения даты публикации новости
dates = []
lenta = check_url(url_feed)
for item_of_news in lenta['items']:
dates.append(item_of_news ['published'])
return datesПосле того как мы задали функции, которые будут получать нужные нам теги, нужно прогнать их по нашему словарю со ссылками на RSS-ленты. Все результаты будем записывать в изначально пустые списки путем объединения списков методом extend.
allheadlines = []
alldescriptions = []
alllinks = []
alldates = []
# Прогоняем наши URL и добавляем их в наши пустые списки
for key,url in our_feeds.items():
allheadlines.extend( getHeadlines(url) )
for key,url in our_feeds.items():
alldescriptions.extend( getDescriptions(url) )
for key,url in our_feeds.items():
alllinks.extend( getLinks(url) )
for key,url in our_feeds.items():
alldates.extend( getDates(url) )Мы имеем четыре списка (по четырем тегам) с новостями из наших источников. Создадим функцию, которая записывает это в датасет. Сам датасет будет записываться в .csv формате, а затем читаться с помощью библиотеки pandas. Функция выдаёт датасет. Аргумент данной функции — путь к файлу, куда сохранится датасет по всем новостям из наших источников.
def write_all_news(all_news_filepath): #функция для записи всех новостей в .csv,
# возвращает нам этот датасет
header = ['Title','Description','Links','Publication Date']
with open(all_news_filepath, 'w', encoding='utf-8-sig') as csvfile:
writer = csv.writer(csvfile, delimiter=',')
writer.writerow(i for i in header)
for a,b,c,d in zip(allheadlines,alldescriptions,
alllinks, alldates):
writer.writerow((a,b,c,d))
df = pd.read_csv(all_news_filepath)
return dfПосле того, как мы имеем датасет со всеми новостям, мы можем начать поиск определенных новостей по нашим векторам. Функция принимает на входе четыре аргумента: путь файла со всеми новостями (который был записан функцией выше), путь файла для записи нового .csv файла (для новостей по определенным векторам). Два вектора — это всего лишь пример, можно использовать любое количество, только придётся немного изменить сам код. Также хочется отметить, что вектора не чувствительны к регистру ввода благодаря прописанию re.IGNORCASE. Поиск происходит по всем тегам: по заголовку, описанию, ссылке и дате публикации. Энкодинг utf-8-sig необходим для работы с кириллицей, если вы работаете с другим языком, используйте другой энкодинг. Функция выдает датасет с определенными новостями.
def looking_for_certain_news(all_news_filepath, certain_news_filepath, target1, target2): #функция для поиска, а затем записи
#определенных новостей по таргета,
#затем возвращает этот датасет
df = pd.read_csv(all_news_filepath)
result = df.apply(lambda x: x.str.contains(target1, na=False,
flags = re.IGNORECASE, regex=True)).any(axis=1)
result2 = df.apply(lambda x: x.str.contains(target2, na=False,
flags = re.IGNORECASE, regex=True)).any(axis=1)
new_df = df[result&result2]
new_df.to_csv(certain_news_filepath
,sep = '\t', encoding='utf-8-sig')
return new_dfПример выполнения кода для вывода всех новостей:
write_all_news(f_all_news) #все новости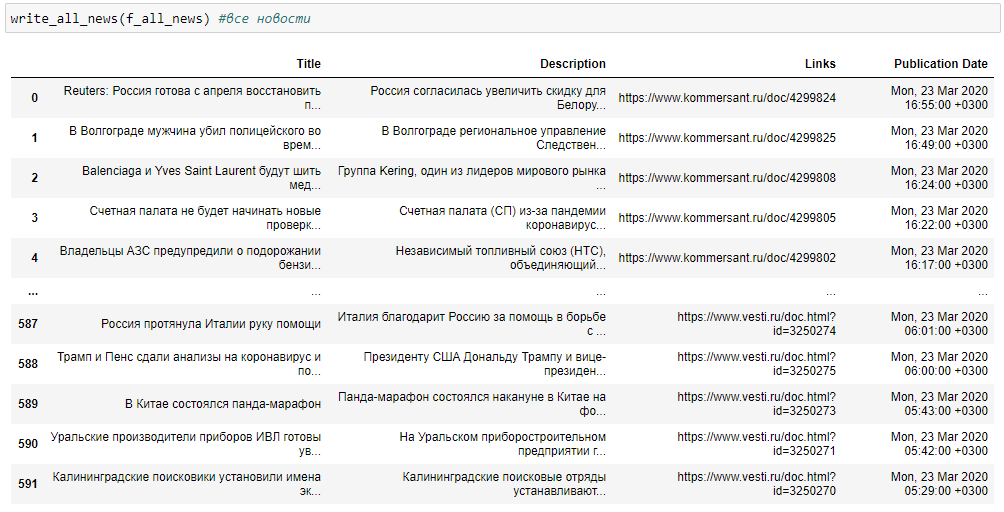
Пример выполнения кода для вывода новостей по определенным векторам:
looking_for_certain_news(f_all_news, f_certain_news, vector1, vector2) 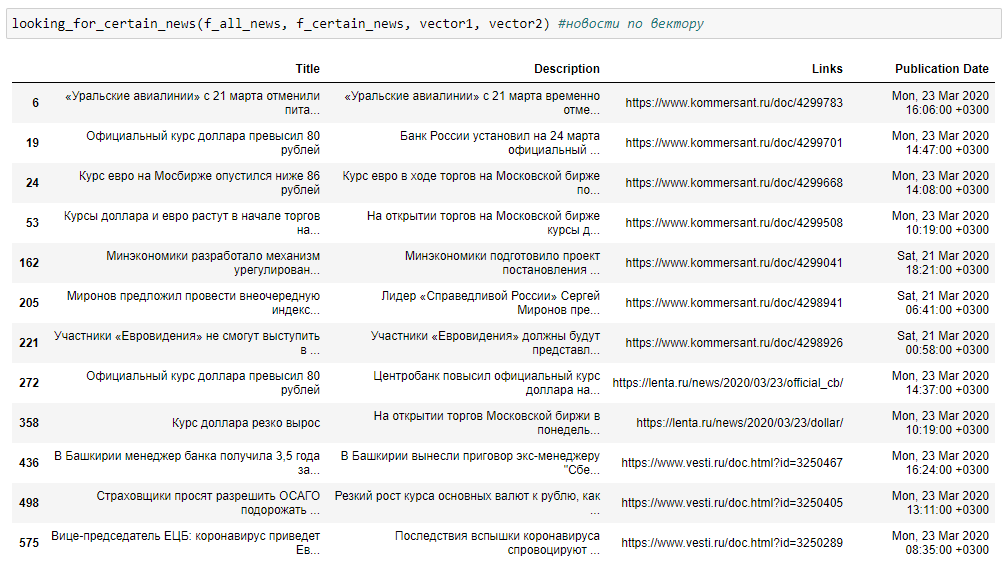
Весь код лежит в моём репозитории по ссылке: https://github.com/germanjke/RSSparsing
Данный парсер решает две проблемы. Получение новостей в удобном формате для дальнейшей работы и поиск по заданным тематикам. В связи с большим потоком информации в RSS-лентах не всегда удаётся получить новость, интересующую нас. Мы же можем задать вектора, по которым будет происходить фильтрация новостей. Таким образом, получить можно действительно нужные нам новости. Помимо этого, все данные сохраняются в .csv формате, что упрощает работу с ним. Непосредственно поиск новостей может выполнять один отдел, а работать с новостями – уже другой. Формат файлов .csv удобен в этом плане. Чтобы работать с ним – не обязательно иметь навыки программирования. Сам код является достаточно простым, поэтому человек, незнакомый с программированием, может разобраться в нём. Благодаря любому количеству RSS-лент, мы можем вести мониторинг неограниченного числа источников. Ручной перебор такого большого количества новостей занял бы огромное количество времени.