/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Один из самых важных элементов работы с данными – их понимание, изучение и первичный анализ. Знание структуры данных, их полноты, разнообразия, наличие null-значений, корреляций, других статистических индикаторов и многое другое – ключ к успешной реализации любых проектов, в которых задействованы большие объемы информации. Весь описанный выше процесс называется data profiling.
Практический опыт показывает, что первичное исследование данных в ручном режиме отнимает большое количество времени и сил.
К счастью, существуют различные способы ускорить разведочный анализ данных (Exploratory Data Analysis, EDA). Одним из них является применение библиотеки Pandas-Profiling языка Python.
Конечно, в библиотеке Pandas есть инструменты для описания структуры данных (например df.describe()), но данная информация не является достаточной для полноценного анализа данных.
В статье в качестве примера используется файл “houses.csv”.
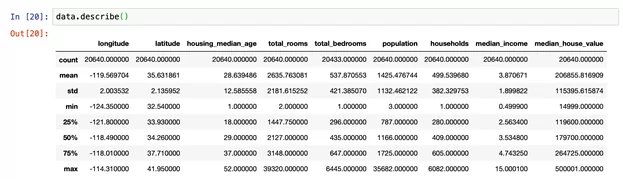
Становится очевидно, что подобный способ не удовлетворяет наши потребности в изучении структуры данных. В этом случае на помощь приходит библиотека Pandas-Profiling, которая является мощным описательным инструментом в сфере EDA.
Pandas-Profiling – это open-source библиотека, с помощью которой можно легко генерировать интерактивные отчеты о структуре исследуемых данных.
В финальном
отчете пользователь получает следующие блоки информации:
- Типы используемых данных;
- Сущности;
- Статистика по квантилям;
- Описательная статистика;
- Статистические коэффициенты;
- Частота значений;
- Гистограммы;
- Корреляция;
- Матрица пропущенных значений;
- Текстовый анализ по категориям
Всю документацию о данной библиотеке можно найти по ссылке:
https://github.com/pandas-profiling/pandas-profiling
Итак, для того чтобы получить информативный отчет, нам необходимо сделать несколько простых шагов.
- Установка Pandas-Profiling:
pip install pandas-profiling[notebook,html]2. Загрузка библиотек:
import pandas as pd
import pandas_profiling
from pandas_profiling import ProfileReport3. Импорт данных:
file = 'houses.csv'
data = pd.read_csv(file, sep = ',')
data.head(10)4. Генерация отчета:
profile = ProfileReport(data, title = 'Data', html = {'style': {'full_width': True}}, sort='None')5. Визуализация:
profile.to_notebook_iframe()6. Сохранение в формате html (возможно сохранение в json):
profile.to_file(output_file="your_report.html")Теперь, когда мы изучили данный инструмент, необходимо дать краткое описание полученных результатов визуализации отчета.
В шапке отчета находятся вкладки для быстрого перемещения между блоками отчета:

Отчет состоит из следующих 6 блоков информации:
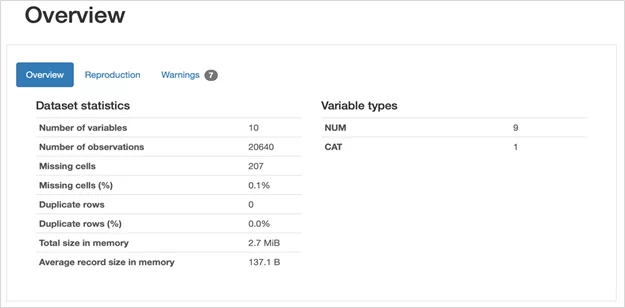
- Overview. Данный блок предназначен для общего описания данных в датасете. Данный блок состоит из 3 подпунктов: Overview. Здесь отражена описательная статистика по всему набору данных, а также типы используемых данных;
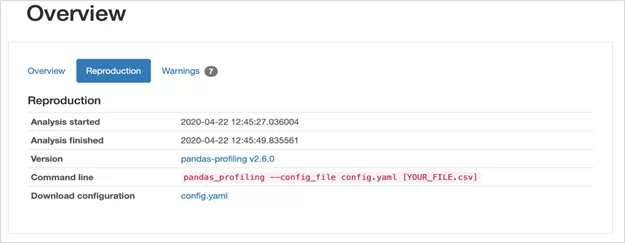
Reproduction. Данный раздел имеет техническое назначение и содержит системную информацию;
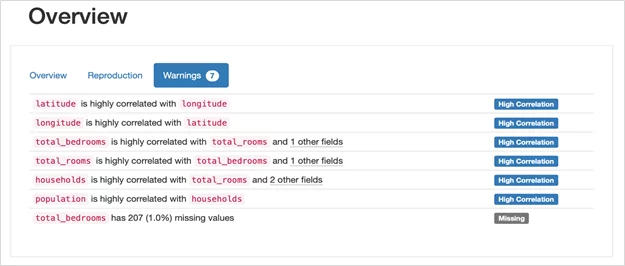
2. Warnings. Важный элемент отчета. В данной вкладке показаны найденные особенности данных (наличие высокой корреляции между данными в столбцах, наличие пустых значений и т.д.)
Variables. В данном блоке находится информация по каждой переменной. В общем случае раздел выглядит так:
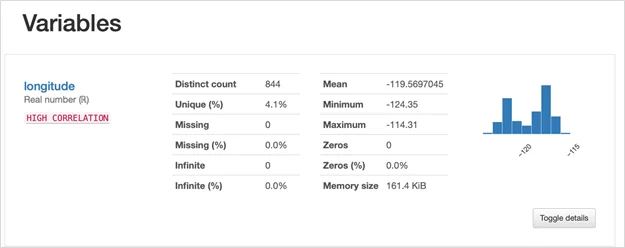
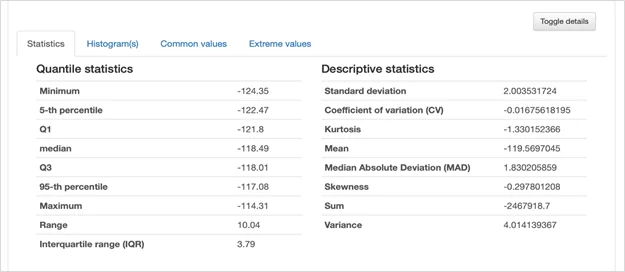
При необходимости можно посмотреть более детальную информацию (квантильная статистика, описательная статистика, полноразмерная диаграмма, распределение значений, минимальные и максимальные значения), нажав на кнопку “Toggle details” в правом нижнем углу:
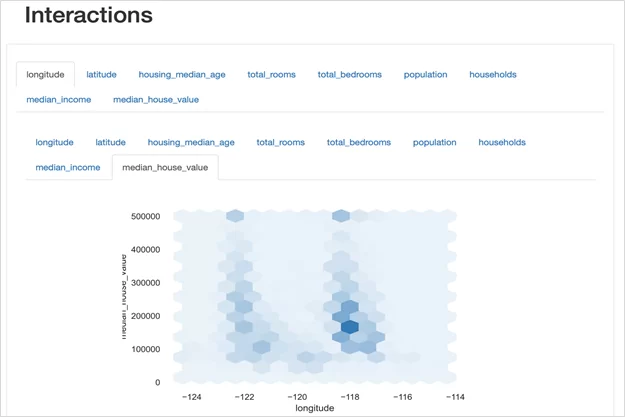
3. Interactions. В данной секции происходит автоматическая генерация графиков по парам переменных для визуализации зависимостей и распределения значений.
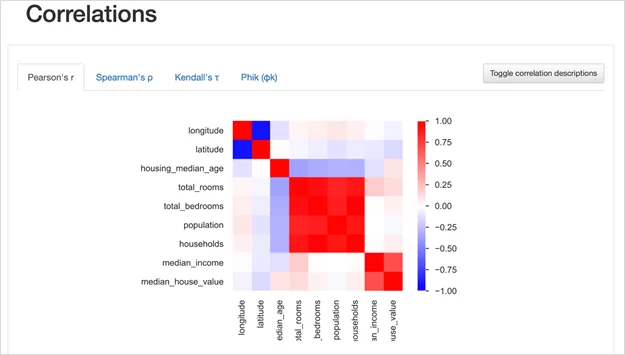
4. Correlations. В этом блоке отражены значения корреляции всех пар переменных.
5. Missing values. Блок предназначен для анализа пропущенных значений в выборке.
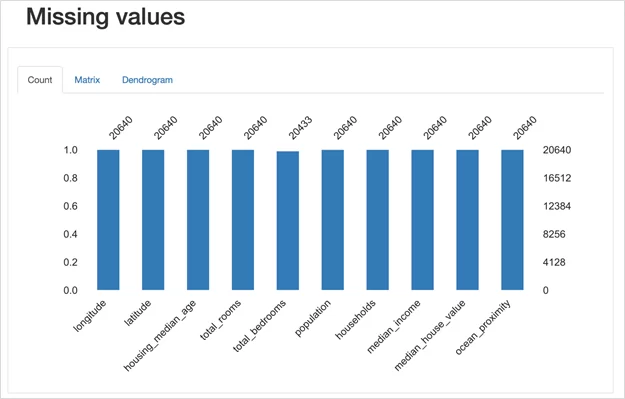
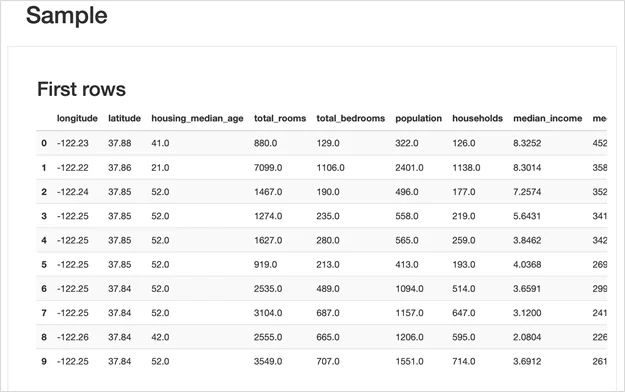
6. Sample. Простое отображение нескольких строк из таблицы.
Не вызывает сомнений, что библиотека Pandas-Profiling является очень мощным и полезным инструментом при изучении структуры данных и разведочном анализе.
К сожалению, у библиотеки есть один существенный минус – медленная обработка больших массивов данных. Но данную проблему можно решить двумя способами:
- Использование только части всего массива (важно убедиться, что выборка из генеральной совокупности перемешана случайным образом и захватывает разные данные):
profile_sample = ProfileReport(data.sample(n = 10000), title="Data", html={'style': {'full_width': True}}, sort="None")profile_sample.to_notebook_iframe()- Использование minimal mode (менее детализированный отчет) на всей генеральной совокупности данных:
profile_minimal = ProfileReport(data, minimal=True)profile_minimal.to_notebook_iframe()Подводя итог вышесказанному, можно сказать, что рассмотренный инструмент прост в использовании и предоставляет пользователю быстрый способ изучения данных.
Надеюсь, что данный материал был для вас полезным и сделает вашу работу проще и быстрее.
В приложениях вы можете найти полный код в формате ipynb, пример использованных данных и пример отчета в формате html.