/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Люди, которые работают с sql, знают, что для объединения таблиц используется операция join. В библиотеке Pandas также предусмотрен join, но помимо него, есть еще такие табличные функции объединения, как merge и concatenate. Когда только-только знакомишься с этими функциями разница между ними неочевидна, поэтому я предлагаю вам краткий обзор отличительных особенностей этих операций.
Join
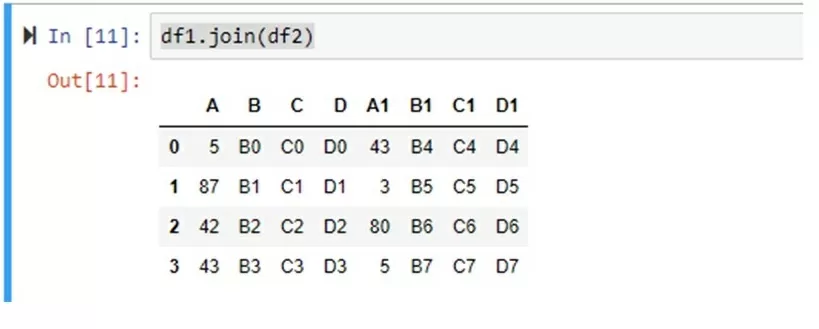
DataFrame.join(self, other, on=None, how='left', lsuffix='', rsuffix='', sort=False) Из трех операций объединения датафреймов join является наиболее простым и предлагает минимум «средств управления» объединения ваших таблиц.
Он объединит все столбцы из двух таблиц с общими столбцами, переименованными в определенные lsuffix и rsuffix. Способ объединения строк из двух таблиц определяется с помощью how – inner, outer, right, left (по умолчанию) аналогично sql. Визуализировать понимание соединения таблиц всеми этими способами могут схемы, изображенные с помощью кругов Эйлера:
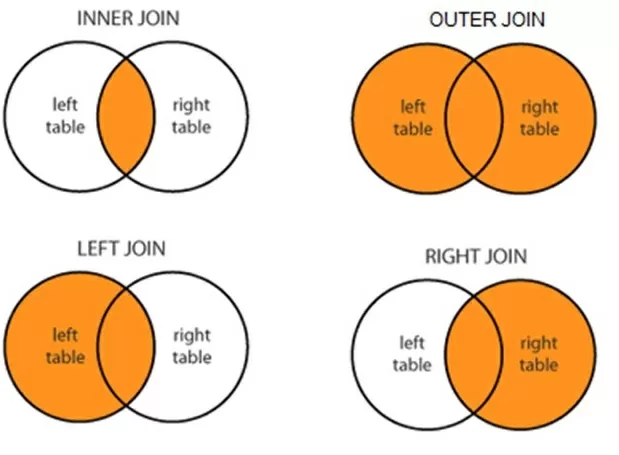
Рассмотрим как работает объединение с помощью Join на примере:
df1 = pd.DataFrame({'A': ['5', '87', '42', '43'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
df2 = pd.DataFrame({'A1': ['43', '3', '80', '5'],
'B1': ['B4', 'B5', 'B6', 'B7'],
'C1': ['C4', 'C5', 'C6', 'C7'],
'D1': ['D4', 'D5', 'D6', 'D7']})
Merge
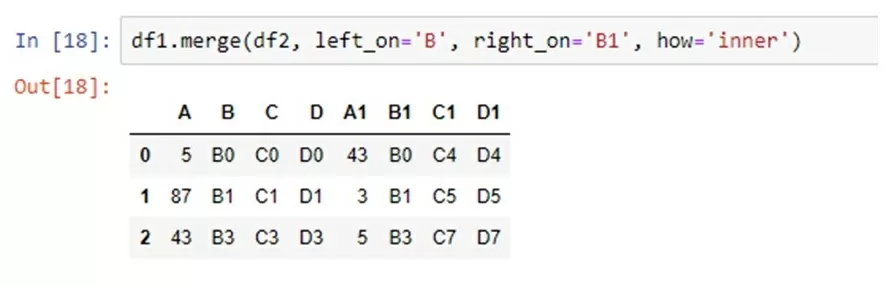
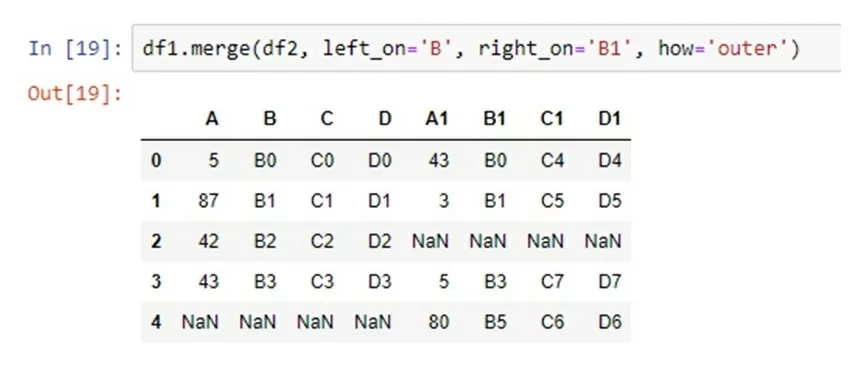
DataFrame.merge(self, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None) Аналогично предыдущей функции merge также объединяет все столбцы из двух таблиц с общими столбцами, переименованными в определенные suffixes. Но в отличие от join, merge уже предлагает три способа организации построчного выравнивания. Первый способ заключается в использовании on = «НАЗВАНИЕ СТОЛБЦА», в этом случае столбец должен быть общим столбцом в обеих таблицах. Второй способ — использовать left_on = «НАЗВАНИЕ СТОЛБЦА» и right_on = «НАЗВАНИЕ СТОЛБЦА». Такой способ позволяет объединить две таблицы, используя два разных столбца. Третий способ — использовать left_index = True и right_index = True, в данном случае таблицы будут объединены по индексам.
Рассмотрим на примере:
df2 = pd.DataFrame({'A1': ['43', '3', '80', '5'],
'B1': ['B0', 'B1', 'B5', 'B3'],
'C1': ['C4', 'C5', 'C6', 'C7'],
'D1': ['D4', 'D5', 'D6', 'D7']})
df1 = pd.DataFrame({'A': ['5', '87', '42', '43'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
Concatenate
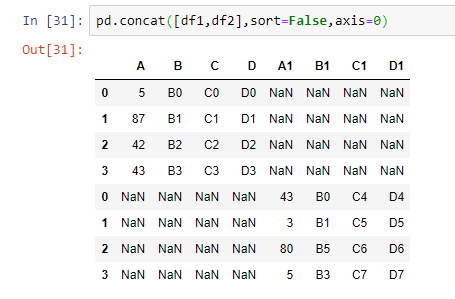
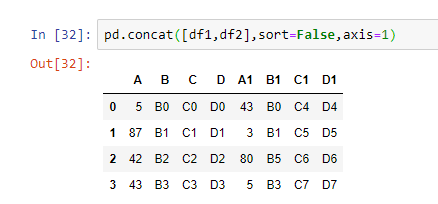
pandas.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=None, copy=True)В отличии от join и merge, которые по умолчанию работают со столбцами, concat позволяет выбрать, хотим ли мы выполнять объединение по столбцам или по строкам. Для этого в аргументе функции необходимо прописать axis=0 или axis=1, в первом случае вторая таблица будет присоединена к первой снизу, во втором – справа.
Рассмотрим на примере:
df2 = pd.DataFrame({'A1': ['43', '3', '80', '5'],
'B1': ['B0', 'B1', 'B5', 'B3'],
'C1': ['C4', 'C5', 'C6', 'C7'],
'D1': ['D4', 'D5', 'D6', 'D7']})
df1 = pd.DataFrame({'A': ['5', '87', '42', '43'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
Append
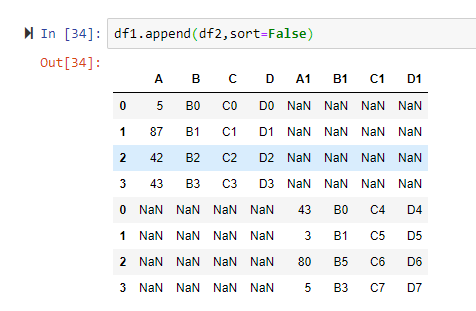
DataFrame.append(self, other, ignore_index=False, verify_integrity=False, sort=False)Напоследок будет уместно упомянуть такую функцию как append(). Она несколько выбивается из перечня ранее упомянутых функций, но тем не менее ее также можно считать инструментом объединения таблиц. Append() используется для добавления строк одного датафрейма в конец другого, возвращая новый датафрейм. Столбцы, не входящие в исходный датафрейм, добавляются как новые столбцы, а новые ячейки заполняются значениями NaN.
Рассмотрим на примере:
df2 = pd.DataFrame({'A1': ['43', '3', '80', '5'],
'B1': ['B0', 'B1', 'B5', 'B3'],
'C1': ['C4', 'C5', 'C6', 'C7'],
'D1': ['D4', 'D5', 'D6', 'D7']})
df1 = pd.DataFrame({'A': ['5', '87', '42', '43'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
Мы рассмотрели основные различия функций объединения датафреймов в Pandas. Join и merge работают со столбцами, и переименовывает общие столбцы, используя заданный суффикс. Но merge позволяет более гибко настроить построчное выравнивание. В отличии от join и merge, concat позволяет работать как со столбцами, так и со строками, но не дает переименовывать строки/столбцы.