/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 9 мин.
Актуальность работы с большими объемами текстовой информации ещё долгое время (а может быть и всегда) будет неоспорима. При этом спектр задач весьма вариативен — от задач по поиску именованных сущностей, до классификации и кластеризации текстов обрабатываемых документов.
Представим ситуацию. Перед вами важная задача — классифицировать огромный поток входящих обращений сотрудников/клиентов для дальнейшего анализа профильными сотрудниками на предмет отклонений и для построения интересующих статистик. Первое решение, приходящее в голову — в ручном режиме просматривать обращения и проводить их классификацию. Спустя пару часов, приходит осознание того, что решение было не самым правильным и так задачу не выполнить в срок. Как же тогда поступить? Именно об этом будет следующий пост.
Задача классификации текстовых данных на языке Python довольно обширная тема, в ней могут встречаться как automl‑подходы, модели тематического моделирования так и нейросетевые методы. В рамках данного поста будет рассмотрен относительно эталонный pipeline для решения данной задачи с помощью классических моделей машинного обучения, предназначенных для классификации.
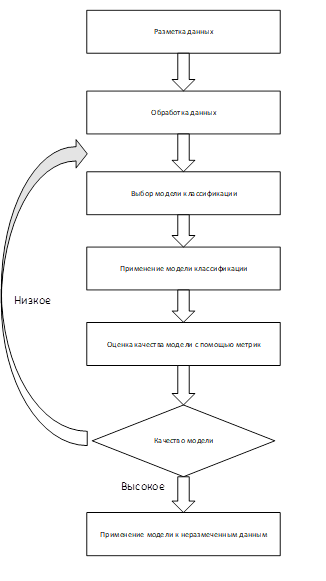
1. Формирование обучающей выборки.
В процессе формирования обучающей выборки производится выбор некоторой части данных (пропорции разбиения различны, но чаще всего используются разбиения 30/70 или 20/80 размеченные/неразмеченные данные), которые необходимо классифицировать вручную (данные, которые так самоотверженно размечали несколько часов тут придутся очень кстати). Эти данные необходимы для предварительной обработки и приведения текстов в числовое представление, понятное для модели и необходимое для дальнейшего поиска скрытых закономерностей, благодаря которым текст может быть отнесен к той или иной тематике.
2. Обработка данных.
Обработка текстов в рамках задач машинного обучения — довольная важная задача. Модели работают только с числовым представлением текстов, для чего необходимо строить их вектора (пункт векторизация текстов). Для того, чтобы вектор был наиболее информативен для модели и наилучшим образом мог указывать содержание анализируемого текста, необходимо проводить унификацию данных, удалять не несущие смысла слова и знаки. Основные задачи, решаемые при обработке данных:
- Приведение к нижнему регистру. Для компьютера одно и то же слово, написанное в разном регистре, будет восприниматься как абсолютно разные слова.
- Очистка от «мусора». В данном случае очистка подразумевает удаление спецсимволов, опечаток, слов с неправильной кодировкой, знаков пунктуации.
- Удаление стоп‑слов. К стоп‑словам в рамках обработки и анализа текстовой информации обычно относят служебные части речи, такие как частицы, союзы, предлоги и междометия, которые часто можно встретить в тексте, и которые в свою очередь не несут какой‑либо смысловой нагрузки.
- Стемминг/ лемматизация слов. Стемминг — это процесс нахождения основы слова, а лемматизация — процесс нахождения нормальной формы слова.
3. Векторизация документов.
Преобразование представления текста документов из текстового представления в цифровое, для дальнейшего использования при обучении модели. Наиболее популярными методами векторизации являются: Прямое кодированеие (one‑hot encoding), bag of words, tf‑idf а так же построение эмбедингов слов/текстов (word2vec, doc2vec)
4. Выбор модели классификатора и её обучение.
На данном этапе производится выбор наиболее подходящей для задачи модели, а также поиск оптимальных гиперпараметров модели.
5. Оценка качества модели с помощью метрик, например — precision, accuracy, recall, F‑мера.
6. Применение модели к неразмеченным данным
Когда основной фронт работ выстроен, можно приступать к реализации.
В качестве датасета для работы в данном случае выступает выборка новостных статей с указанием тематики статьи (спорт, мир, наука и техника, культура, экономика, интернет и сми), сохраненная в формате csv. Общее количество статей — 432 158.
Для начала импортируем необходимые для работы библиотеки:
import numpy as np
import pandas as pd
import nltk
nltk.download('stopwords') # выполнить команду после самого первого импорта библиотеки
nltk.download('punkt')
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from pymystem3 import Mystem
from tqdm import tqdm
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.pipeline import Pipeline, make_pipeline
from sklearn.experimental import enable_halving_search_cv
from sklearn.model_selection import (
train_test_split,
HalvingRandomSearchCV
)
from sklearn.metrics import (
ConfusionMatrixDisplay, confusion_matrix,
f1_score, roc_auc_score,
classification_report, make_scorer
)
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from collections import Counter
from sklearn.datasets import make_classification
from imblearn.under_sampling import NearMiss
import matplotlib.pyplot as plt
topics_dict = {#словарь для кодирования категориальных признаков
'Спорт': 1, 'Мир': 2,
'Наука и техника': 3, 'Культура': 4,
'Экономика': 5, 'Интернет и СМИ': 6
}Дополним список стоп‑слов из библиотеки nltk своими собственными. На данный момент список стоп‑слов ограничен 151 словом и последний раз обновлялся более 10 лет назад.
additional_stopwords = ['которых','которые','твой','которой','которого','сих','ком','свой','твоя','этими','слишком','нами','всему', 'будь','саму','чаще','ваше','сами','наш','затем', 'самих','наши','ту','каждое','мочь','весь','этим', 'наша','своих','оба','который','зато','те','этих','вся', 'ваш','такая','теми','ею','которая','нередко','каждая', 'также','чему','собой','самими','нем','вами','ими', 'откуда','такие','тому','та','очень','сама','нему',
'алло','оно','этому','кому','тобой','таки','твоё', 'каждые','твои','нею','самим','ваши','ваша','кем','мои','однако','сразу','свое','ними','всё','неё','тех','хотя','всем','тобою','тебе','одной','другие','само','эта', 'самой','моё','своей','такое','всею','будут','своего', 'кого','свои','мог','нам','особенно','её','самому',
'наше','кроме','вообще','вон','мною','никто','это']
stop_words = stopwords.words('russian') + additional_stopwords
m = Mystem()Ниже приведена часть кода, в которой произведена компиляция наиболее часто используемых для очистки регулярных выражений (при использовании в циклах с большим количеством шагов дает прирост в скорости) и набор функций, использующихся для очистки входного текста, удаления стоп‑слов, а также его лемматизации:
del_n = re.compile('\n') # перенос каретки
del_tags = re.compile('<[^>]*>') # html-теги
del_brackets = re.compile('\([^)]*\)') # содержимое круглых скобок
clean_text = re.compile('[^а-яa-z\s]') # все небуквенные символы кроме пробелов
del_spaces = re.compile('\s{2,}')
def prepare_text(text):
text = del_n.sub(' ', str(text).lower())
text = del_tags.sub('', text)
text = del_brackets.sub('', text)
res_text = clean_text.sub('', text)
return del_spaces.sub(' ',res_text)
def del_stopwords(text):
clean_tokens = tuple(
map( lambda x: x if x not in stop_words else '', word_tokenize(text) )
)
res_text = ' '.join(clean_tokens)
return res_text
def lemmatize(text):
lemmatized_text = ''.join(m.lemmatize(text))
return lemmatized_text.split('|')Далее производим объединение всех функций. В следующем участке кода считанные из csv‑файла тексты разделяются на части по 10 тысяч строк в каждой. Для чего это делается? Благодаря материалу на Хабре «Лемматизируй это быстрее» я выяснил, что один и тот же объем текстов разительно отличается в скорости обработки в зависимости от количества отдельных вызовов функции лемматизации, в связи с чем было решено объединять тексты и использовать определенный разделитель, а после обработки возвращать их в исходное состояние. После многочисленных экспериментов с chunksize (размер отдельно выбранной части общего датасета), разбиение по 10 тысяч дало наиболее оптимальный по скорости результат (на меньшем количестве выигрыш по времени был незначительным, на большем — очистка данных на других этапах становилась намного дольше, нивелируя увеличение скорости лемматизации).
df = pd.read_csv('file_directory', chunksize = 10000)
filtered_chunk_list=[]
for chunk in tqdm(df):
chunk['text'] = chunk['text'].apply(lambda x: prepare_text(str(x)) )
all_texts = '|'.join( chunk['text'].tolist())
clean_texts = del_stopwords(all_texts)
chunk['text'] = lemmatize(clean_texts)
chunk['title'] = chunk['title'].apply(lambda x: prepare_text(str(x)))
all_titles = '|'.join( chunk['title'].tolist())
clean_titles = del_stopwords(all_titles)
chunk['title'] = lemmatize(clean_titles)
chunk['topic'] = chunk['topic'].map(topics_dict)
filtered_chunk_list.append(chunk)
model_df = pd.concat(filtered_chunk_list)
model_df.to_csv('text_prepare.csv', index=False)Представленная ниже функция помогает определить наилучшие гиперпараметры для выбранной модели:
def search_best_estimator(pipeline, param_grid, x, y):
hrs = HalvingRandomSearchCV(
estimator=pipeline,
param_distributions=param_grid,
scoring='f1_weighted',
cv=3,
n_candidates="exhaust",
factor=5,
n_jobs=-1,
)
_ = hrs.fit(x, y)
return hrs.best_estimator_Для определения качества работы модели помимо использования различных метрик бывает полезно визуальное представление результатов в виде графиков, гистограмм и т. д. Одним из методов визуального представления является матрица ошибок (confusion matrix). На данной матрице легко определить количество правильно/неправильно спрогнозированных моделью значений.
def plot_confusion_matrix(y_test, y_preds, model):
fig, ax = plt.subplots(figsize=(16,10))
cm = confusion_matrix(y_test, y_preds)
cmp = ConfusionMatrixDisplay(cm, display_labels = model.classes_ )
cmp.plot(ax=ax)
plt.show()Обучение модели
Когда все необходимые функции реализованы, приступаем к обучению модели.
Строим пайплайн, в который включен метод векторизации наших текстов, а также выбрана модель, с помощью которой будет строиться классификация.
x, y = df['text'].tolist(), df['topic'].tolist()
pipeline = Pipeline(
steps = [("tfidf", TfidfVectorizer() ),("base",RandomForestClassifier() )]
)
param_grid = {
"tfidf__min_df": [i for i in range(25,35,5)],
"base__n_estimators": [i for i in range(150,250,50)],
"base__max_depth": [i for i in range(25,35,5)],
"base__min_samples_split":[i for i in range(6,10,2)],
"base__min_samples_leaf": [2],
}
estimator = search_best_estimator(pipeline, param_grid, x, y)
Делим выборку на тренировочную и тестовую.
X_train, X_test, y_train, y_test = train_test_split(
x, y, random_state=42, test_size=0.3, stratify=y
)Обучаем модель, делаем предсказание на тестовых данных и строим на результатах матрицу путаницы.
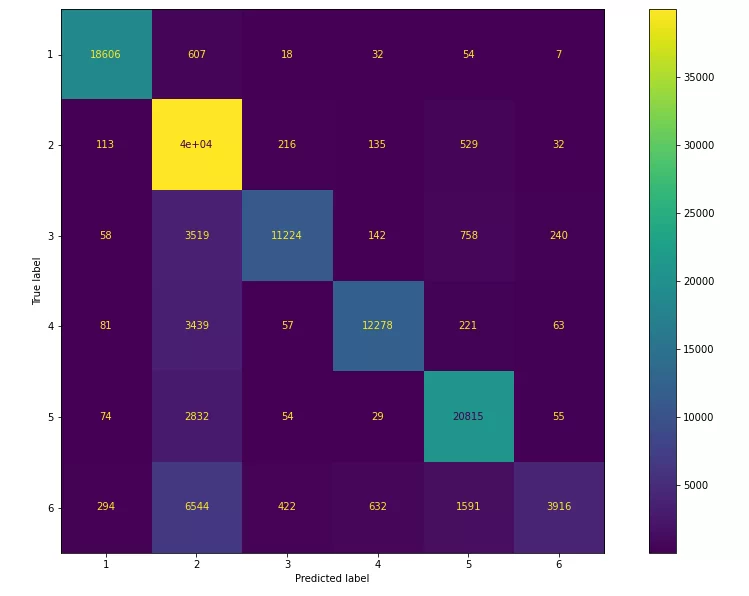
Как видно из матрицы ошибок (confusion matrix), наибольшее количество ложных срабатываний приходится на второй класс. Для задачи классификации по нескольким классам была выбрана взвешенная метрика F1-score, так как при оценке качества в данном типе задач мы не вычисляем общую оценку F-1, а вместо этого производится вычисление оценки F1 для каждого класса в соотношении один/остальные. При таком подходе мы оцениваем успех каждого класса отдельно, словно для каждого класса существуют отдельные классификаторы. Точность работы классификатора на взвешенной метрике F1-score составляет 69%. С чем может быть связано такое поведение при обучении модели? Выведем количество текстов, в каждом из классифицируемых классов в нашей обучающей выборке:
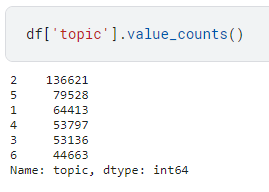
После этого все встает на свои места, класс 2 — мажоритарный и поэтому при обучении модели она наиболее сильно ориентируется на данные полученные из текстов данного класса. Как же обучить модель мультиклассовой классификации при дисбалансе классов?
Необходимо прибегнуть к одному из методов передискретизации (ресэмплинга). Суть данного подхода заключается либо в добавлении недостающих данных в недостаточно большой набор (oversampling), либо в удалении элементов из слишком большого набора (undersampling).
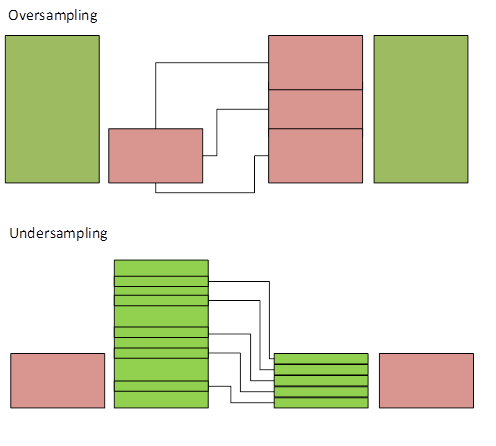
С целью улучшения качества модели применим один из методов undersampling, а именно NearMiss.
vectorizer = TfidfVectorizer(min_df=30)
vect_x = vectorizer.fit_transform(x)
nm = NearMiss()
X_res, Y_res = nm.fit_resample(vect_x, y)
pipeline2 = Pipeline( steps = [("base", RandomForestClassifier() )] )
param_grid2 = {
"base__n_estimators": [i for i in range(200,300,50)],
"base__max_depth": [i for i in range(25,35,5)],
"base__min_samples_split": [i for i in range(8,12,2)],
}
estimator2 = search_best_estimator(pipeline2, param_grid2, X_res, Y_res)
X_train, X_test, y_train, y_test = train_test_split(
vect_x, y, random_state=42, test_size=0.3, stratify=y
)
estimator2.fit(X_res, Y_res)
y_preds2 = estimator2.predict(X_test)
plot_confusion_matrix(y_test, y_preds2, estimator2)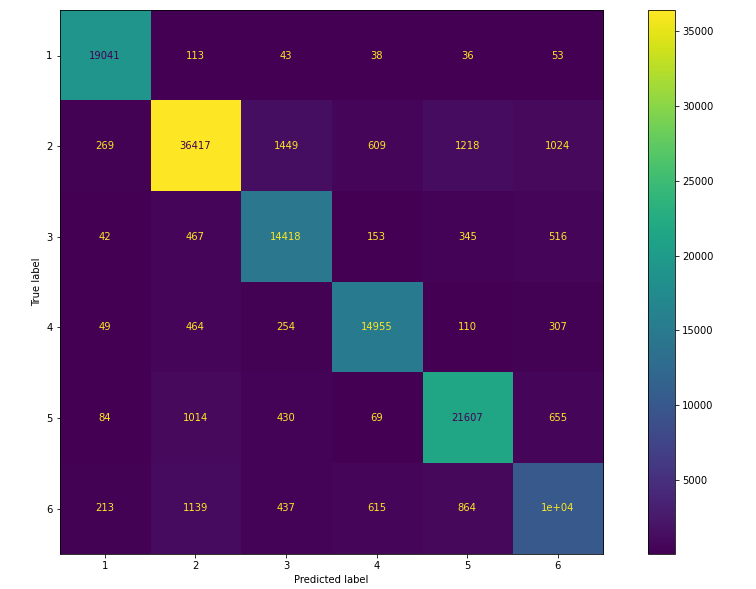
Как видно из confusion matrix, проведение undersampling привело к улучшению классификации. Метрика F1-score выросла до 79%.
xgbc = XGBClassifier()
xgbc.fit(X_res,[j-1 for j in Y_res])
X_train, X_test, y_train, y_test = train_test_split(
vect_x, y, random_state=42, test_size=0.3, stratify=y
)
pred_y = xgbc.predict(X_test)
f1 = f1_score( y_test, [j+1 for j in pred_y], average='weighted')
print( f' Model F1-score: {f1}' )
plot_confusion_matrix(y_test2, pred_y, xgbc)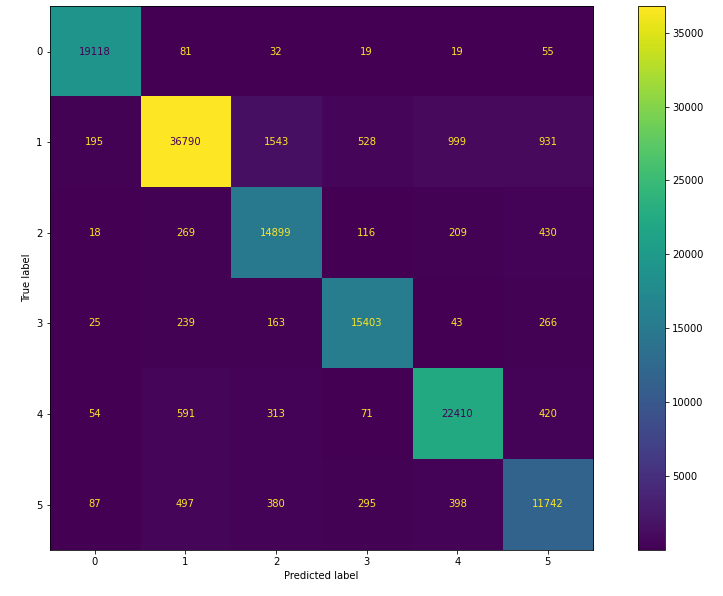
Взвешенный параметр метрики F1-score для модели XGBoostClassifier достиг 92%. По confusion matrix можно заметить, что существенно снизилась доля ошибок, связанных с отнесением текстов к мажоритарному классу и не относящихся к нему.
Вывод
На основании проведенных исследований удалось достигнуть качества классификации в 92% по взвешенной метрике F1-score. На данный момент существует довольно большое количество моделей, специализирующихся на решении задач в области Natural Language Processing, в том числе основанных на глубоком обучении, поэтому рассмотренные модели и качество их работы не являются «панацеей» и могут быть мало применимы для другого датасета. Но, нет предела совершенству! Одним из вариантов улучшения классификации является продолжение экспериментов с подбором оптимальной связки «метод передискректизации — метод векторизации — модель классификации».
Так же стоит отметить тот факт, что дисбаланс в классах оказывает значительное влияние на точность работы модели, в связи с чем я считаю, что целесообразно производить обучение лишь на сбалансированных данных.
Ссылка на Github‑репозиторий.