/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Методы Data Science особенно полезны, например, для прогнозирования клиентских изменений, автоматического подбора актуальных предложений для клиентов, распознавания голосовых запросов и многого другого.
Рассмотрим такую задачу:
Нам требовалось провести анализ подсчета комиссий, возвратов и сумм операций по различным мерчантам за каждый месяц. Но задача усложнялась тем, что в исходных данных сумма комиссии, возврата, дата операции, номер терминала, номер мерчанта находились в одном столбце, причем в различных формулировках. А также даты были приведены за каждую операцию (то есть множество строк на различные дни с указанием времени)
Вот несколько примеров формулировок (в целях сохранения конфиденциальности, приведены не существующие примеры):
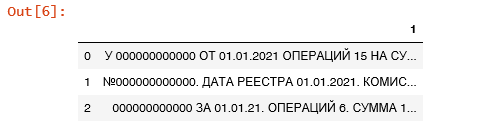
— Эквайринг, по мерчанту 000000000000 от 01.01.2021 операций 15 на сумму 7,140.00 удержано ком 120.50 Возвр 0.00/0.00
— Зачисление средств по операциям с МБК (на основании реестров платежей). Мерчант №000000000000. Дата реестра 01.01.2021. Комиссия 98.88. Возврат покупки 0.00/0.00. НДС не облагается.
— Возмещение по торговому эквайрингу Мерчант 000000000000 за 01.01.21. Операций 6. Сумма 1,683.86 руб.,комиссия 28.62 руб.,НДС не облагается Терминал 00000000. Возврат покупки 0.00.
Существует несколько алгоритмов решения таких задач. Можно разбить по столбцам с использованием split() по ключевым словам (мерчант, комиссия, возврат), затем вытащить первые числа вначале каждого столбца, используя метод isdigit. Также можно использовать регулярные выражения.
Регулярки – это шаблоны, используемые для поиска определенного фрагмента текста, числа и т.п. В Python для работы с ними предусмотрен модуль re, который можно просто импортировать.
Рассмотрим пример использования регулярных выражений в Python:
#Импортируем нужные библиотеки:
import pandas as pd
import numpy as np
import re
#Загружаем датасет
df = pd.read_csv('мерчанты.csv', delimiter=';')\
df

#делаем все буквы большими для исключения разных регистров
df1= df['эквайринг'].str.upper()
df1.to_list()

#Исключим все ненужные данные (в нашем случае это номер терминала, дата, число операций)
df2 = df1.str.replace('\d\d\.\d\d\.\d{4}','')
df3 = df2.str.replace('\d\d\.\d\d\.\d{2}','')
df4 = df3.str.replace('ЕРМИНАЛ \d{8}','')
df5 = df4.str.replace('(?:ОПЕРАЦИЙ|ОПЕРАЦИЯМ) \d+','')
df6 = df5. str.replace('((?:УММА|УММУ) \d+\,\d+\.\d+)','')
df6.to_list()

#Теперь можно вытаскивать нужные нам числа (мерчант, комиссию, возврат)
df7 = df6.str.extract('.* ( \d{12}).* ([0-9.]+).* ([0-9.]+)')
df7.columns = ['мерчант', 'комиссия', 'возврат']
df7
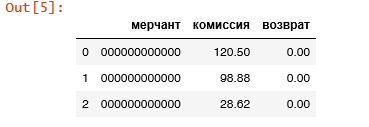
В итоге получаем отдельные готовые столбцы, содержащие числовые значения мерчанта, суммы комиссии и суммы возврата, которые уже можно использовать для дальнейшего анализа.
Теперь попробуем сделать то же самое с использованием метода split:
Для этого также как выше импортируем библиотеки pandas и numpy, загружаем датасет и делаем все буквы большого регистра.
#Обрезаем по слову «мерчант» каждую строку
tempA =df1.str.split('МЕРЧАНТ', expand = True)
#Оставляем только все, что после слова «мерчант»
tempB= tempA[1]
tempB.to_frame()
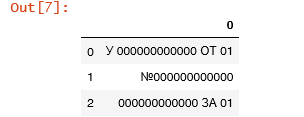
#Далее обрезаем до следующей точки (в нашем случае обрезаться будет в разных формулировках в разных местах)
tempB = tempB.str.split('.', n = 1, expand = True)
tempC = tempB[0]
tempC.to_frame()
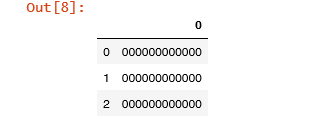
#Извлекаем число с первым вхождением (здесь можно было бы использовать функцию с методом isdigit, но он достает только целые числа, в случае с номером мерчанта все отработало бы точно, но в случае с комиссиями и возвратами, где число с плавающей точкой – нет, так что будем сразу использовать здесь str.exctract с регуляркой)
tempD = tempC.str.extract('(\d+)')
tempD
#Теперь можно также вырезать комиссию
tempE = df1.str.split('КОМ', expand = True)
tempF = tempE[1]
tempG = tempF.str.split('ВОЗВР', expand = True)
tempН = tempG[0]
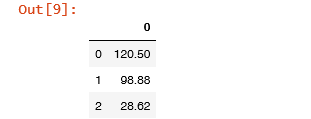
tempI = tempH.str.extract('(\d+\.\d+|\d+)')
tempI
#Вырезаем возврат
tempJ = df1.str.split('ВОЗВР', expand = True)
tempJ = tempJ[1]
tempJ = tempJ.str.extract('(\d+\.\d+)')
tempJ

И соединим наши датафреймы:
df10 = df.join(df7)
df10

Можно сделать вывод, что лучше комбинировать эти два метода для более точного извлечения необходимых данных в еще более сложных случаях. То есть сначала разбить с использованием split на нужные участки предложения, а затем с использованием регулярных выражений вытаскивать необходимые числа из каждого участка.
Но это еще не все. Сейчас мы все еще имеем множество строк (несколько миллионов) с датами на дни и часы, а нам требуется сумма за месяц, что значительно уменьшит число строк и объем данных.
Для этого нам потребуется библиотека datetime
В нашем случае дни нам больше не потребуются, так что можно их заменить единичками, чтоб облегчить задачу, а время удалить.
import datetime
df10['dat'] = pd.to_datetime(df10['dat'])
df10['dat']=df10['dat'].apply(lambda x:datetime.datetime(year=x.year,month=x.month,day=1))
df10

df10#Затем можно группировать по дате и мерчантам
df_sum = df10[['dat', 'мерчант', 'сумма операции', 'комиссия', 'возврат']]
df_sum = df_sum.groupby(['dat','мерчант']).sum()
df_sum.head()

Теперь мы привели данные в должный вид, после чего можно визуализировать их с помощью библиотеки matplotlib, и понять в каких месяцах комиссия была самая большая, а в каких был самый большой возврат и многое другое.
#например посмотрим на график возвратов в каждом месяце (для нашего примера лучше построить по дням, но на настоящих данных на месяцах)
import matplotlib.pyplot as plt
plt.plot(df['dat'], df10['возврат'])
plt.show()
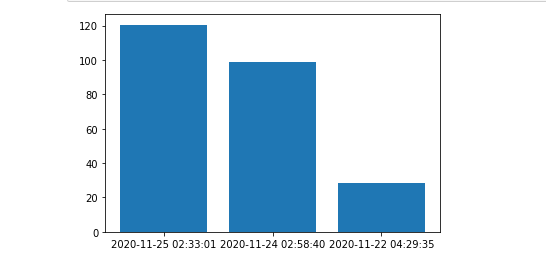
#или можем построить столбчатую диаграмму комиссий на каждый месяц
import matplotlib.pyplot as plt
plt.bar(df['dat'],df10['комиссия'])
plt.show()
Итак, мы рассмотрели аспекты применения методов Python для обработки данных с использованием регулярных выражений и метода split, показали преимущества этих методов, способы визуализации данных и актуальность данного вопроса. Важно отметить, что использование вышеописанных методов ускоряет работу аналитиков, программистов и аудиторов, т.к. многие рутинные операции могут быть выполнены компьютерами намного быстрее, чем традиционными способами в Excel. Рекомендуем внедрять описанные в этой статье методы в работу в целях повышения качества и увеличения объема выполненных задач.