/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Рассмотрю практические вопросы использования Spark DataFrame. Коснусь таких аспектов работы как: создание DataFrame из различных источников данных, фильтрация, сортировка, создание новых столбцов и другое.
Стоит напомнить или отметить, что Spark поддерживает написание команд на трех языках программирования: Scala, Java и Python. Представлю реализацию на языке Python. Не буду затрагивать многих нюансов, с которыми вы можете столкнуться, поэтому наиболее развернутую информацию как всегда можно найти только в Гайде
Создание DataFrame
Spark позволяет создавать DataFrame различными способами:
- Из файла (JSON, CSV, ORC, Parquet и др.);
- Из RDD;
- Из таблицы на HDFS;
- Из pandas DF.
Примеры создания DF перечисленными способами.
Создание DF из файла
Первый способ на примере. Чтение CSV файла.
Прежде чем осуществлять чтение файла необходимо создать схему, которая отражает типы данных значений. Для начала необходимо выполнить импорт типов данных:
from pyspark.sql.types import StructType, StructField, IntegerType, StringTypeСоздание схемы:
schema = StructType(fields=[
StructField("col_1", IntegerType()),
StructField("col_2", StringType ())
])
Создание DF:
df = spark.read.csv("/path/file_name", schema=schema, sep=";")Если есть уверенность, что файл не содержит в своих столбцах смешанных типов данных, можно задать условие, чтобы при записи DataFrame типы данных определялись самостоятельно, для этого достаточно установить параметр: inferSchema=True.
В случае, когда в таблице присутствует заголовок необходимо добавить: header=True.
Собирая все вместе получается следующий запрос для создания DF:
df = spark.read.csv("/path/file_name", sep=";", inferSchema=True, header=True.)Для предпросмотра DataFrame можно использовать следующие функции:
- show(5, vertical=True, truncate=False)
- take()
- collect()
Посмотреть содержимое таблицы:
df.show()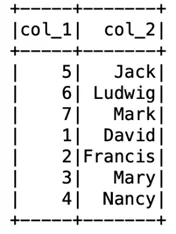
Создание DataFrame из RDD и Pandas DataFrame
Создание из этих структур довольно простое и выполняется в одно действие:
df = spark.createDataFrame(rdd)
df = spark.createDataFrame(pandasDF)
Возможно отдельно задать параметр schema
Создание из таблицы HDFS
Создание Spark DF из таблиц HDFS возможно 2-мя способами, отличающихся формой написания (при этом скорость выполнения команды неизменна):
- Pyspark запрос;
- SQL запрос.
Примеры написания запросов:
Pyspark API
df = spark.table(‘schema_name.table_name’)SQL API
df = spark.sql(“””
SELECT col_1,
col_2
FROM schema_name.table_name
”””)
Операции с DataFrame
Spark DataFrame имеет обширный (хоть и более скромный чем Pandas) функционал.
Пример выполнения следующих операций:
- выбор колонок,
- фильтрация,
- сортировка,
- создание новых столбцов,
- соединение таблиц,
- сохранение результата.
Для выполнения предложенных команд необходимо осуществить импорт необходимых функций:
from pyspark.sql.functions import col, asc, desc, lenghtВыбор нужных колонок
Выбираю из df столбцы с названием “col_1” и “col_2”:
df2 = df.select(col(“col_2”))
df2.show()

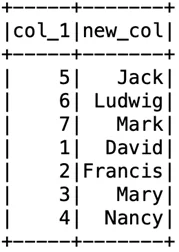
Переименование столбцов
Переименую столбец ”col_2” на “new_col”:
df2 = df.select(col(“col_1”), col(“col_2”).alias(“new_col”))
df2.show()
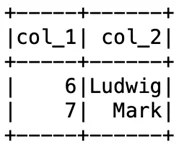
Фильтрация
Фильтрацию можно выполнить, используя команды where или filter:
df2 = df.filter(col(“col_1”) > 5)
df2.show()
Также поддерживаются логические операторы: и (&), или (|), не (~) и др.
Сортировка
Делаю сортировку по двум столбцам, по первому – по убыванию, по второму – по возрастанию:
df2 = df.orderBy(col("col_1").desc(), col("col_2").asc())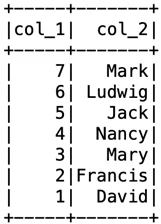
Создание новых столбцов
Создам новый столбец, в котором будут хранится значения длины строки столбца “col_2”:
df2 = df.withColumn(“new_col”, length(“col_2”))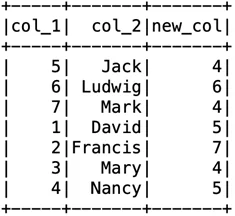
Если необходимо произвести сложные математические операции, можно написать необходимую функцию и применить ее к RDD.
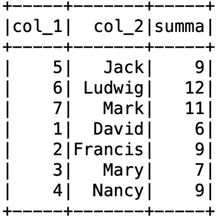
Например, если необходимо сложить “col_1” с длиной “col_2”, то написание функции выглядит так:
def summator(a_int, b_str):
return a_int + len(b_str)
rdd = df.rdd.map(lambda x: x[0], summator(x[0], x[1],))
df2 = rdd.toDF([“col_1”, ”summa”])
Соединение таблиц
Для соединения двух таблиц используется команда join. Соединяю таблицы df и df2 (из прошлого примера), ключом для соединения – является поле “col_1”.
df_rez = df.join(df2, df.col_1 == df2.col_1, how=”inner”)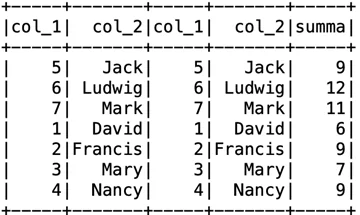
Сохранение результата
Если объем данных небольшой, то возможно преобразовать Spark DF в Pandas DataFrame, а затем уже сохранить в нужном формате:
pandas_df = df.toPandas()Если объем данных большой, можно сохранить информацию либо в файл на HDFS, либо в таблицу в формате Parquet или ORC.
Сохранение в таблицу в формате ORC:
t_f.write\
.mode("overwrite")\
.format("orc")\
.saveAsTable(‘schema_name.table_name’)
Сохранение в файл в формате csv:
df.coalesce(1)\
.write.format("com.databricks.spark.csv")\
.mode("append")\
.option("header", "true")\
.option("delimiter", "~")\
.option("quoteMode", "false")\
.save("path")
Заключение
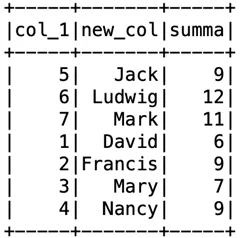
Я разобрал основы работы со Spark DataFrame, показал, как создавать и выполнять несложные операции. В заключении отмечу, что все предложенные методы можно комбинировать с собой для сокращения промежуточных вычислений. Например:
df_final = df.select(col("col_1"), col("col_2").alias("new_col"))\
.join(df2.select(col("col_1"), col("summa")), df.col_1 == df2.col_1, how="inner").select(df.col_1, col("new_col"), df2.summa)