/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
Узнав в конце прошлого (2020) года о Data Science соревновании на российской площадке boosters.pro, я решил принять участие, чтобы не заскучать во время новогодних каникул, применить имеющиеся знания, навыки анализа данных и понять, каких навыков не хватает в ближайшей зоне развития. Задач было две, я сконцентрировался на первой из них. Краткая формулировка следующая: «Вам нужно предугадать целевое действие клиента в рамках будущей сессии мобильного приложении Альфа-Банк. Набор данных — события пользователей в мобильном приложении (просмотр баланса, оплаты, переводы, обращения в чат и др.) за 270 дней. На выходе — построить предсказательную модель наиболее вероятного действия клиента при запуске приложения», подробнее о соревновании и предоставленных данных можно посмотреть на сайте организаторов: https://boosters.pro/championship/alfabattle2/overview. Я опишу некоторые этапы размышлений и действий по ходу решения, а также добавлю комментарии этих шагов, сделанные моим немного более опытным коллегой.
Первым шагом была загрузка решения, предложенного организаторами в качестве образца. Ожидания, что это будет самое худшее решение в рейтинге, не оправдались. Оказалось, что действительно этот файл загрузили еще не один десяток человек и что решение это очень плохое, но удивительно, что при этом нашлись решения еще более худшие, т.е. кто-то из участников не воспользовался даже этим. Также для удовлетворения исследовательского интереса с помощью Python-библиотек pandas и numpy было протестировано решение со случайно распределенными вариантами значений целевой переменной (всего у нас в обучающих данных 10 различных вариантов будущей сессии клиента).
Комментарий: «Начать участие сразу – это хороший шаг. Даже начав с загрузки плохого решения, у нас появляется понимание, как работает площадка, появляется отправная точка для дальнейшего сравнения. Но вот дальше гораздо полезнее не тратить время на решения, основанные на случайных числах, а как можно раньше сделать хотя бы базовый исследовательский анализ имеющихся данных. Например, такие простые функции pandas как describe() и value_counts() дают нам информацию о том, что в 5 с лишним млн строк файла train_target.csv мы имеем данные о 77 631 клиенте, с количеством сессий, колеблющимся от 1 до 1646. И при этом в 45% случаев (самое частое) наблюдаемое действие это “main_screen”, а в 1% случаев (самое редкое) – это “invest”.»
Следующим шагом была попытка использовать архив clickstream.zip размером 3Гб, содержащий достаточно обширные данные о действиях пользователя в формате parquet — колоночно-ориентированном формате хранения файлов. К сожалению, загрузить в датафрейм даже один файл из архива на моем домашнем ноутбуке не получилось – блокнот Jupyter умирал и то, что мне нужен более мощный компьютер для работы, стало единственной дополнительной новой информацией. С помощью библиотеки pyarrow получилось увидеть размеры одной из таблиц и схему данных (12+ млн строк, 15 столбцов, большинство из которых текстовые), но на этом эксперименты я свернул.
Первым осмысленным решением можно назвать подсчет встречаемости действий в каждой группе наблюдаемых данных, объединенных клиентом, и выбор самого частого действия в качестве решения. Попутно в matplotlib были сделаны несколько диаграмм разброса для фич, относящихся ко времени событий:
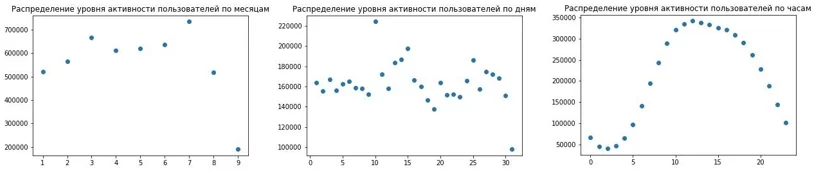
Расчет делался по каждой группе наблюдений, относящихся к одному и тому же идентификатору клиента client_pin. Использование pandas.groupby() для группировок строк и value_counts() для подсчетов по нужным столбцам внутри каждой из групп давало ответ сразу же.
Комментарий: «Можно было бы чуть-чуть улучшить данное решение, разобрав более подробно ситуации, когда самых частых значений не одно, а два или более. Поверхностный подход не учитывал эти моменты, и в отправляемое решение всегда попадало первое значение ряда. А это значит, что из одинаково самых частых выбиралось первое значение по алфавиту.»
Новый год (а я напомню, что соревнование проходило в период с 12.12 по 18.01.) принес подарки и новые идеи. Появилась гипотеза, что имеет значение, а как давно было последнее взаимодействие с пользователем. Т.е. если мы попрощались с ним недавно, то продолжать будем с той же операции, что была последней, а если давно, то предлагаем ему самое частое действие из того, что он совершал до этого. Звучит неплохо, но что считать «недавним» взаимодействием? Один час? 2 часа? Практика показала, что сутки (24 часа) дают результат лучше, чем 1 час, 48 часов лучше, чем сутки, а вот дальнейшее увеличение этого интервала метрику качества ухудшает.
Комментарий: «Имело смысл проверить, объединены ли прошлые действия пользователя в группы по времени, образующие последовательности или наборы и искать закономерности уже внутри таких групп.»
Еще несколько дней раздумий дали плоды в виде решения, которое основывалось на анализе статистики наблюдений. Шаги следующие (по-прежнему работаем поочередно с каждой из групп событий, относящихся к одному клиенту). Сначала считаем разницу во времени в секундах между каждым наблюдаемым действием и моментом времени, в котором делаем предсказание. Находим обратные значения (1/delta) к данным величинам и получаем ряд весовых коэффициентов для каждого наблюдения – веса, таким образом, будут тем меньше, чем дальше во времени наблюдаемое событие от момента прогноза. Затем группируем по одинаковым действиям, суммируя весовые коэффициенты, и выбираем действие с наибольшим весом. Интуитивно понятно, что это попытка совместить частотный подход (с выбором самого популярного наблюдаемого шага) и выбор последнего действия (у него будет самый большой вес изначально), но улучшить эту формулу добавлением весовых коэффициентов к части или всех наблюдаемых шагов не получилось – качество только снижалось.

Комментарий: «Идея не нова, хотя и хорошо, что получилось прийти к ней самостоятельно. Развитие этого подхода состоит в подборе оптимального количества учитываемых в расчетах событий – возможно, что не нужно учитывать их все, а только последние N или за последние D дней. Предварительно неплохо посмотреть на кластеры, образуемые клиентами, или разбить все данные на группы по диапазонам количеств имеющихся наблюдений»
Ну, и собственно, само машинное обучение. К моему сожалению, ни интересная библиотека cpt (Compact Prediction Tree) по предсказыванию очередного элемента последовательности с фиксированным алфавитом, разработанная Philippe Fournier-Viger, ни работы с решающими деревьями
библиотеки sklearn, ни catboost не позволили улучшить полученный результат. В качестве фич были использованы значения часа и номера дня недели по каждой из операций (минимальное, среднее, медиана и максимальное), общее количество наблюдений, количество уникальных значений в наблюдениях, продолжительность наблюдений в секундах (разница во времени между первым и последним наблюдением), дельта времени между последним наблюдением и моментом прогноза, а также отношение продолжительности к этой дельте. График продвижения к итоговому решению выглядит следующим образом.
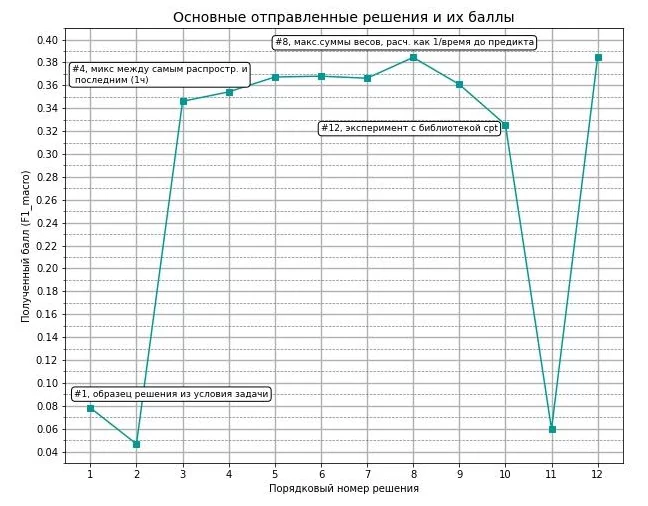
Получилось войти в 50 лучших и получить бронзовый «значок» площадки, что не так уж и плохо. Код на python для получения решения можно посмотреть здесь.
Комментарий: «В итоговой конференции соревнования рассказали, что лучшие решения (ожидаемо) были получены с помощью нейронок, хотя и более классические методы ML при должном усилии давали результаты, приближенные к результатам сетей. Нужно учить мат.часть и в качестве помощи на этом пути могу посоветовать курс, организованный ВШЭ на площадке Coursera по теме «Как выиграть соревнование по Data Science» (ориг. “How to Win a Data Science Competition: Learn from Top Kagglers”). Курс запущен в 2017, но содержит много и даже на данный момент полезной информации. Успехов!»