/img/star (2).png.webp)
/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
В настоящее время все чаще используют модели для вероятностей исхода будущих событий.
И перед нами стояла задача проверить эффективность работы одной из моделей, оценивающей стоимость активов с признаками обесценения.
При разработке подобных моделей применяются значительные по объему накопленные данные, которые подвергаются предварительной обработке и далее используются для обучения модели.
Разработчиком модели использовались базовые исходные данные в следующем формате:
| Наименова-ние актива | Стоимость актива до дефолта, млн. руб. | Стоимость обесценен-ного актива, млн. руб. | Дисконт | Характеристи-ки актива (дата приобрете- ния ) | Характеристики актива (прочие) |
| АВС | 1267,15 | 437,2 | 0,65 | 12.03.2018 | … |
| … | … | … | … | … | … |
Мы установили, что к входным параметрам модели применялись ограничения, основанные на экспертных суждениях.
Разработчиком модели удалялись записи по активам, оценённым с дисконтом более 75% к первоначальной оценочной стоимости. Данное ограничение позволяло существенно сократить обучающую выборку, но основывалось на экспертном мнении разработчика, и не было подкреплено математическим расчетом.
Поскольку данное заключение сотрудников бизнес-подразделения не подкреплялось аналитическими исследованиями, нами было принято решение проверить, как влияет экспертное суждение разработчиков на эффективность прогнозирования модели.
Нам удалось разработать технологию генерации моделей с меняющимися входными параметрами, включающую функционал оценки качества генерируемых моделей и подбор оптимальных входных параметров для создания обновленной модели.
Суть технологии заключается в генерации большого количества моделей при изменении одного из входных параметров, на который оказало влияние экспертное суждение.
Генератор математических моделей был создан на Python 3.6. с использованием приложения Jupyter Notebook. В качестве переменной на вход генератора подавались выборки для разработки, из которых последовательно удалялись активы с дисконтом начиная от 30% и заканчивая 99% с шагом 0,25%. Остальные параметры для создания моделей не менялись и соответствовали параметрам разработчика модели. Генератором было произведено 276 последовательных итераций (99-30)*4 в результате которых было создано 276 моделей на выборках с различными порогами дисконтирования для целей отбора активов в обучающую выборку. Результат анализа качества полученных моделей представлен на графике, где отражены значения метрик качества MAE, RMSE, MED_AE моделей.
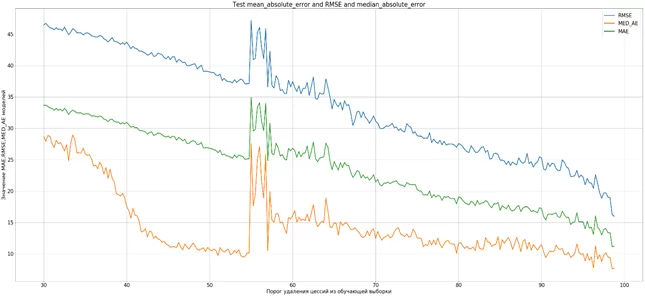
— ось Х — значения порога дисконтирования для обучающих выборок;
— ось У – значения метрик ошибок моделей (чем меньше значение, тем качество модели лучше).
Анализируя метрики по линиям графика, можно сделать два заключения:
1. При увеличении порога дисконта, применяемого для отбора активов в обучающую выборку, качество моделей растет даже при значении дисконта более 75%.
2. На графике видны значительные ухудшения качества моделей в диапазоне порога дисконта с 55% до 57,5%, применяемого для отбора активов. Данный факт объясняется тем, что в обучающей выборке присутствуют активы, оказывающие значительное отрицательное влияние на качество модели. Найти такие активы в выборке можно по значительному отклонению между значением дисконта, применённого к активу, рассчитанного моделью, и дисконтом актива, заданным в целевой переменной для данного актива. Исходя из анализа линий графика, таких активов в выборке единицы.
Следовательно, удалять из выборки все сделки с дисконтом свыше 75% на основе экспертного суждения сотрудников бизнес-подразделения не целесообразно, так как качество модели в этом случае ухудшалось.
Для реализации проекта мы использовали следующие библиотеки Python:
- Библиотека numpy — для обработки больших массивов данных;
- Библиотека pandas — для обработки и анализа данных;
- Библиотека matplotlab — для отображения результатов исследования в виде графических представлений;
- Библиотека sklearn – использовалась генератором для создания моделей. В качестве метода создания математических моделей был использован градиентный бустинг.
#для оценки влияния параметра дисконта на качество модели, создаем обучающую выборку с дисконтом, изменяющимся в пределах от 0 до 99% в каждой итерации, dk- количество итераций с шагом 0,25%. ['D-rate']- параметр обучающей выборки, определяющий величину дисконта
dk=396
for j in range(120,dk,1):
#Берем только те активы, которые были проданы дороже чем за j/4(30%), но не больше чем 100% от стоимости долга.
#Создание обучающей выборки
df_to_learn_b = df_7115_26[(df_7115_26['D-rate']>=0) & (df_7115_26['D-rate']<=j/4)]
#Удаляем ненужные поля и выносим таргет в отдельный датафрейм
y_b = df_to_learn_b['D-rate']
del df_to_learn_b['D-rate']
#Формировние тестовой и обучающей выборки на каждой итерации, создание модели и её обучение
train_b , test_b, y_train_b, y_test_b = train_test_split(df_to_learn_b, y_b, test_size=0.2, random_state=42)
gb_b = GradientBoostingRegressor(n_estimators=750, learning_rate=0.01, max_depth=7, min_samples_split=5, min_samples_leaf=5)
gb_b.fit(train_b, y_train_b)
#Запишем значения метрик качества модели в датафрейм на каждой итерации
pr_a = gb_a.predict(df_to_learn_t)
pr_a[np.where(pr_a<0)] = 0.0
pr_a[np.where(pr_a>dk/4)] = dk/4
proc_discont_plot.append([j, np.sqrt(mean_squared_error(y,y_pred=pr_a)),
median_absolute_error(y,y_pred=pr_a),
mean_absolute_error(y,y_pred=pr_a)])
#Строим график изменения метрик качества моделей, обученных на выборках с различными
диапазонами дисконта
from matplotlib.mlab import movavg
plt.figure(figsize=(50,20))
plt.rcParams.update({'font.size': 22})
x = [k[0]/4 for k in proc_discont_plot]
l2 = plt.plot(x, [k[1] for k in proc_discont_plot], '-', linewidth=3.0, label=u'RMSE_75')
l3 = plt.plot(x, [k[2] for k in proc_discont_plot], '-', linewidth=3.0, label=u'MED_AE_75')
l4 = plt.plot(x, [k[3] for k in proc_discont_plot], '-', linewidth=3.0, label=u'MAE_75')
plt.title('Test mean_absolute_error and RMSE and median_absolute_error')
plt.xlabel('Порог удаления обесцененных активов из обучающей выборки')
plt.ylabel('Значение MAE,RMSE,MED_AE моделей')
plt.legend()
plt.grid()
plt.show()
Задачу поиска и удаления из обучающей выборки активов, заключенных на нерыночных условиях (например, при неправомерных действиях, направленных на занижение стоимости активов, в результате чего искусственно сформирован значительный дисконт), можно решить с помощью применения метода доверительных интервалов.
После удаления активов, не попавших в доверительный интервал из обучающей выборки, качество модели улучшится, выбросы на графике исчезнут. Применяя метод доверительных интервалов, удаление отдельных позиций из обучающей выборки станет математически/статистически обоснованно.
На очищенной выборке была создана новая модель с лучшими качественными показателями. Таким образом, была решена задача минимизации влияния человеческого фактора на формирование данных для обучающей выборки модели, позволившая улучшить качество Модели оценки стоимости активов с признаками обесценения.