/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Мы уже рассказывали про пакет для Python – PyTesseract. И сравнивали его с другими инструменты для распознавания PDF (ссылка — https://newtechaudit.ru/pytesseract-pdf/). Сегодня расскажем о том, как указать папку с несколькими файлами PDF и получить на выходе только нужную нам информацию из этих документов в текстовом виде в одном документе.
Первым делом, импортируем все необходимые библиотеки и так же указываем пути к cmd PyTesseract и к poppler:
import cv2
import numpy as np
import imutils
import pytesseract
from pdf2image import convert_from_path
import matplotlib.pyplot as plt
import os
import time
import pandas as pd
from PIL import Image, ImageFile
import numpy as np
import math
import re
from scipy import ndimage
ImageFile.LOAD_TRUNCATED_IMAGES = True
init_path = os.getcwd() + '\\'
pytesseract.pytesseract.tesseract_cmd= init_path + r'Tesseract-OCR\tesseract.exe'
poppler_path = init_path + r'PROSTOpopplerDLYApython\poppler-0.68.0_x86\poppler-0.68.0\bin'
os.chdir(poppler_path)
Следующим шагом создаём списки ключевых слов, в данном примере будем искать реквизиты организаций и их наименования, ключевые слова могут быть другие для решения других задач.
rekvis=['инн','бик','кпп','инн.','кпп.','бик.','счета','счет','счёта','счёт']
namescp=['ооо','оао','наименование','общество']
Далее описываем функцию предобработки изображения для PyTesseract. Переводим изображение в градации серого, применяем размытие. В этой же функции передаём полученное изображение в PyTesseract и конвертируем в текст.
def in_text(img):
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = cv2.medianBlur(img,3)
img = cv2.bilateralFilter(img,3,35,35)
rgb_planes = cv2.split(img)
result_planes = []
result_norm_planes = []
for plane in rgb_planes:
dilated_img = cv2.dilate(plane, np.ones((7,7), np.uint8))
bg_img = cv2.medianBlur(dilated_img, 21)
diff_img = 255 - cv2.absdiff(plane, bg_img)
result_planes.append(diff_img)
img = cv2.merge(result_planes)
kernel = np.ones((2, 2), np.uint8)
img = cv2.dilate(img, kernel, iterations=1)
img = cv2.erode(img, kernel, iterations=2)
skel = img.copy()
kernel = np.ones((3,3),np.uint8)
erod = cv2.morphologyEx(img,cv2.MORPH_ERODE,kernel)
temp = cv2.morphologyEx(erod, cv2.MORPH_DILATE, kernel)
temp = cv2.subtract(img,temp)
skel = cv2.bitwise_or(skel,temp)
# cv2.imshow('ds',img)
# cv2.waitKey(0)
img2 = cv2.threshold(skel, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)[1]
resulat = pytesseract.image_to_string(img2, lang = 'rus')
return(resulat)
Далее описываем функцию для определения угла и его выравнивания.
## проверка угла изображения, выравнивание
def Rotation(imag):
img_before = imag
img_gray = cv2.cvtColor(img_before, cv2.COLOR_BGR2GRAY)
img_edges = cv2.Canny(img_gray, 100, 100, apertureSize=3)
lines = cv2.HoughLinesP(img_edges, 1, math.pi / 180.0, 100, minLineLength=100, maxLineGap=5)
angles = []
for [[x1, y1, x2, y2]] in lines:
angle = math.degrees(math.atan2(y2 - y1, x2 - x1))
angles.append(angle)
median_angle = np.median(angles)
img_rotated = ndimage.rotate(img_before, median_angle)
print(f"Angle is {median_angle:.04f}")
return(img_rotated)
На следующем шаге описываем функцию для работы с уже конвертированным текстом. Поиск будет осуществляться по ключевым словам, которые мы передали в списки rekvis и namescp.
## поиск названий организаций и их реквизитов, при необходимости можно расширить поиск по другим ключевым словам
def findition(result):
words=[]
name_org=[]
global rekvisiti
global ALLinf
global s
global df
for i in range(len(resulat1)):
word = resulat1[i]
p = word.lower()
words.append(p)
if ((p in namescp) and re.match(r'[«"]',(resulat1[i+1])) and ((resulat1[i+1] + " ") not in ALLinf)):
ALLinf.append(p + " : ")
name_org.append(p + " : ")
if bool(rekvisiti) is True:
df.loc[s,'Найденные реквизиты']=rekvisiti
rekvisiti=[]
s=s+1
else:
df.loc[s,'Найденные реквизиты']='Не найдено'
rekvisiti=[]
s=s+1
k=1
while True:
ALLinf.append((resulat1[i+k]) + " ")
name_org.append((resulat1[i+k]) + " ")
if ((resulat1[i+k]).endswith(r"»") or (resulat1[i+k]).endswith(r"».") or (resulat1[i+k]).endswith(r"»,")
or (resulat1[i+k]).endswith(r'".') or (resulat1[i+k]).endswith(r'",') or (resulat1[i+k]).endswith(r'"')):
df.loc[s,'Организация'] = name_org
name_org=[]
break
k=k+1
elif (p in rekvis) and re.match(r'\d',(resulat1[i+1])):
ALLinf.append(p + " : " + resulat1[i+1])
rekvisiti.append(p + " : " + resulat1[i+1])
# df = df.append([{'Найденные реквизиты': p + " : " + resulat1[i+1]}],ignore_index=True)
print("---%s seconds ---Работа с текстом"%(time.time()-start_time))
# df = df.append([{'Найденные реквизиты': p + " : " + resulat1[i+1]}],ignore_index=True)
print(words)
# re.sub(',',' ',nazv)
# df = df.append({'Организация': [[nazv]],'Найденные реквизиты':[[rekvs]]},ignore_index=True)
return(words)
Теперь осталось передать путь к папке с файлами pdf и в нужном порядке вызвать наши функции. В данном примере получаем только первую страницу каждого документа, т.к. вся необходимая для нас информация есть на первой странице документа. В цикле передается первая страница документа и конвертируется в изображение. Затем полученное изображение передается в функцию проверки угла и выравнивается в случае необходимости. После этого полученное изображение передается сначала в функцию предобработки и перевода изображения в текст. Полученный текст разделяем по словам с помощью функции split() и передаём в функцию работы с текстом.
%%time
ALLinf=[]
rekvisiti=[]
path = init_path + r'\files'##путь к папке с файлами PDF
files = os.listdir(path)
df = pd.DataFrame(index=[0],columns = ('Организация','Найденные реквизиты'))
s=0
for file in files:
nazv=[]
rekvs=[]
print(file)
start_time = time.time()
imag=convert_from_path(path+ '\\' + file,300,first_page=1,last_page=1)
imag[0].save(r'out.png','PNG')
imag = cv2.imread(r"out.png", cv2.IMREAD_UNCHANGED)
print("---%s seconds ---Конвертация в изображение и считывание"%(time.time()-start_time))
start_time = time.time()
img = Rotation(imag)
print("---%s seconds ---Ротация"%(time.time()-start_time))
start_time = time.time()
#img = cv2.imread(r"out.png", cv2.IMREAD_UNCHANGED)
# cv2.imshow('ds',img)
# cv2.waitKey(0)
res=in_text(img)
resulat1=res.split()
poisk=findition(resulat1)
if bool(rekvisiti) is True:
df.loc[s,'Найденные реквизиты']=rekvisiti
rekvisiti=[]
s=s+1
else:
df.loc[s,'Найденные реквизиты']='Не найдено'
rekvisiti=[]
s=s+1
print(ALLinf)
df.to_excel('primer.xlsx')
Найденная информация по организациям записывается в DataFrame. На выходе у нас есть один DataFrame, в котором есть вся найденная информация из всех документов по нужным нам условиям (в нашем случае реквизиты организаций и их наименования).
На выходе получается DataFrame вида:
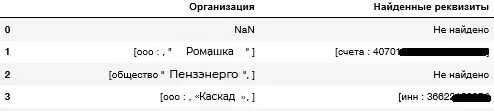
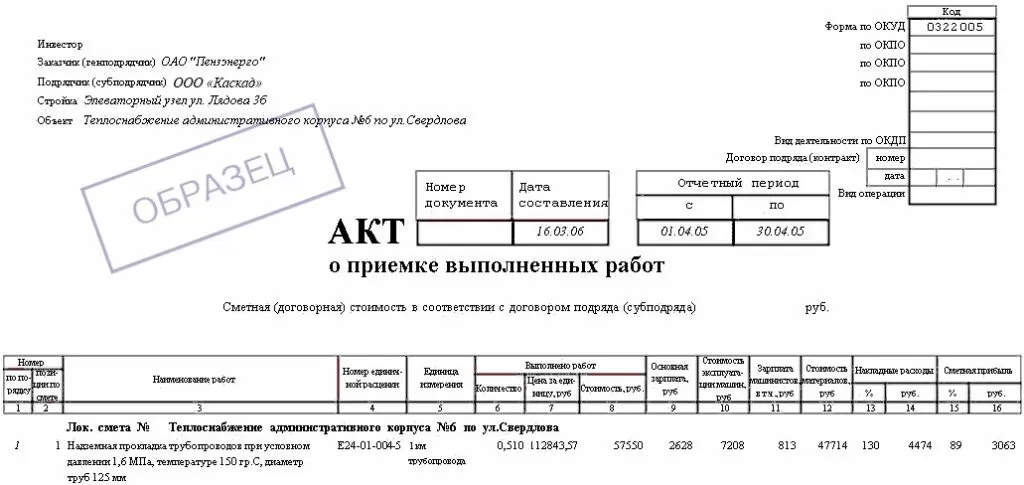
Входные документы:

Итог
При помощи компьютерного зрения и библиотек для работы с текстом и изображениями мы смогли автоматизировать процесс извлечения нужной информации из PDF документов в текстовом виде. Как видно из приложенных изображений, есть скан с шумами, плохим качеством и не ровным углом, при этом все реквизиты, которые были в документе были найдены и текст распознан.
С использованием такого алгоритма можно извлечь любую необходимую информацию из PDF в текстовом виде, по определённым ключевым словам или условиям, при этом достаточно указать папку с PDF файлами, а на выходе будет всего один файл со всей информацией.