/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
В Teradata есть такие таблицы, и даже есть способ загружать данные в них из клиента, но скорость такой загрузки оставляет желать лучшего.
Например, импорт 5000 строк через Teradata SQL Assistant у меня занял 13 минут:

| Elapsed | Rows | SQL Statement | |
| 1 | 00:13:35 | 5000 | insert acc values(?,?,?) |
В python существуют библиотеки для работы с терадатой, с помощью которых можно ускорить этот процесс, одна из них так и называется – teradata.
Процесс подключения к БД выглядит следующим образом:
import teradata
params = {
'dsn'='YourDSN',
'method':'odbc',
'useregionalsettings'='N'
}
td = teradata.UdaExec('test','1.0',logConsole=False).connect(**params)
Вместо «YourDSN» указываем название источника (data source name) такое же, как и при подключении из клиента.
Для выполнения команд на сервере используются методы execute иexecutemany.
Создание таблицы выглядит следующим образом:
create_import = """
create multiset volatile table "acc"(
acc varchar(20),
hash varchar(40),
opendate date
)primary index(acc)
on commit preserve rows;
"""
td.execute(create_import)
Наполнение таблицы можно реализовать параметризированным запросом, передав в качестве параметров набор данных. Для загрузки нескольких строк за раз можно использовать метод executemany. Так как будет выполнятся несколько вставок параллельно, такой способ импорта будет в разы быстрее, чем через клиент.
Например, импорт данных из датафрейма pandas будет выглядеть следующим образом:
import pandas as pd
data = pd.read_sql('select * from account', con=source_con)
insert_import = """insert into "acc" values(?,?,?)"""
import_batch = [tuple(x) for x in data.to_records(index=False)]
td.executemany(insert_import,import_batch,batch=True)
При выполнении такого запроса может возникнуть следующая ошибка:
“SQL request exceeds maximum allowed length of 1 MB”
Она вызвана тем, то у драйвера ODBC есть ограничение размера запроса в 1 Мб, чтобы избежать такой ошибки, можно разбить данные на части такого размера.
В моем случае, для таблицы из 3х столбцов небольшого размера это около 5000 строк.
Один из удобных способ сделать это – воспользоваться методом array_split из модуляnumpy, который разбивает массив или датафрейм на несколько одинаковых частей.
import numpy as np
rows_per_batch = 5000
n_batches = data.shape[0]//rows_per_batch or 1
batches = np.array_split(data,n_batches)
for batch in batches:
import_batch = [tuple(x) for x in batch.to_records(index=False)]
td.executemany(insert_import,import_batch,batch=True)
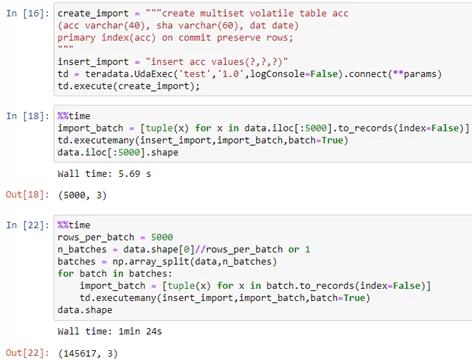
Время выполнения на тех же 5000 строк данных составляет 5 секунд, а на 150 тыс. – чуть больше минуты:
Получение результатов осуществляется так же, как и в других модулях БД — через курсор, или метод pd.read_sql:
cur = td.execute('sel*from account')
res = cur.fetchall()
res_cols = res[0].columns.keys()
df = pd.DataFrame.from_records(data=res,columns=res_cols)
# или
df = pd.read_sql("sel top 100 * from account",td)
Так же следует заметить, что при подобном подходе к работе с разными источниками, отсутствует необходимость записывать промежуточные данные в файл, для последующего импорта на сервер.