/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 3 мин.
Предположим, что имеется лог-файл process_log.csv некоторого процесса. При этом в процессе возможны шесть этапов, условно обозначенных A, B, C, D, E, F, а правильной является последовательность этапов B — C — D.
Для того, чтобы проверить правильность реализации процесса, необходимо пройти три шага.
Предварительно импортируем все необходимые библиотеки.
import pandas as pd
from pm4py.algo.discovery.dfg import algorithm as dfg_discovery
from pm4py.visualization.dfg import visualizer as dfg_visualization
import seaborn as sns
%matplotlib inline
На первом шаге в переменной correct_path задаем правильную последовательность этапов процесса, читаем лог-файл процесса process_log.csv и приводим наименования столбцов в лог-файле в соответствие с обозначениями, принятыми в библиотеке pmp4y.
correct_path = 'B-C-D'
log = pd.read_csv('process_log.csv', parse_dates=['timestamp'])
cols = {'timestamp': 'time:timestamp', 'stage': 'concept:name', 'case': 'case:concept:name'}
log.rename(columns=cols, inplace=True)
В результате этих действий столбец case:concept:name будет содержать идентификатор реализации процесса, а столбец concept:name — наименование этапа процесса. Фрагмент полученной таблицы log приведен ниже.
| index | case:concept:name | concept:name | time:timestamp |
| 100 | 1000 | C | 2018-01-29 20:56:10 |
| 101 | 550 | B | 2018-01-30 14:27:45 |
| 102 | 752 | D | 2018-01-30 22:24:30 |
| 103 | 358 | B | 2018-01-31 17:48:08 |
| 104 | 919 | C | 2018-01-31 17:51:06 |
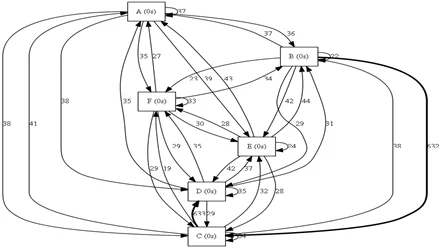
Визуализируем граф процесса с помощью средств библиотеки pm4py.
dfg = dfg_discovery.apply(log)
gviz = dfg_visualization.apply(dfg, log=log, variant=dfg_visualization.Variants.FREQUENCY)
dfg_visualization.view(gviz)
На ребрах построенного графа будет отображено количество переходов между этапами процесса.
На втором шаге выполняем проверку соответствия реального процесса стандарту. Для этого создаем списки этапов процесса stages и уникальных реализаций процесса cases, составляем словарь paths, ключами в котором являются все встречающиеся последовательности этапов, а значениями — их количества, затем проверяем корректность всех последовательностей.
stages = log['concept:name'].unique().tolist()
cases = log['case:concept:name'].unique().tolist()
paths = {}
for case in cases:
log_single = log[log['case:concept:name'] == case].sort_values(by='time:timestamp')
path = '-'.join(log_single['concept:name'])
paths[path] = paths.get(path, 0) + 1
data = [(k, v) for k, v in paths.items()]
results = pd.DataFrame(data, columns=['Путь', 'Количество'])
results['Соответствует'] = results['Путь'].apply(lambda path: 'Да' if path == correct_path else 'Нет')
В итоге получаем таблицу results, содержащую данные о всех возможных последовательностях этапов процесса, их количестве и соответствии стандарту.
| Путь | Количество | Соответствует |
| B-C-D | 600 | Да |
| A-E-D-C-C | 1 | Нет |
| C-F-B | 1 | Нет |
| D-B-B | 1 | Нет |
| E-E-D | 1 | Нет |
На третьем шаге выполняем анализ полученных результатов. Строим диаграмму количества корректных и некорректных реализаций процесса.
conformance = results.groupby('Соответствует')['Количество'].sum().reset_index()
sns.barplot(data=conformance, x='Количество', y='Соответствует')
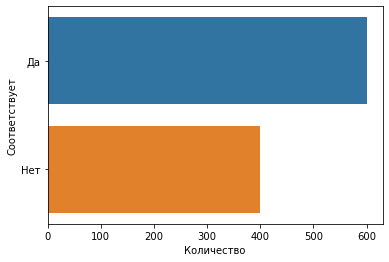
Из диаграммы следует, что исследуемый процесс корректно реализовался приблизительно в 60% случаев (600 из 1000).
Также визуализируем пять наиболее частых некорректных реализаций процесса.
incorrect_all = results[results['Соответствует'] == 'Нет']
incorrect_top5 = incorrect_all.groupby('Путь').sum().sort_values(by='Количество', ascending=False).head(5).reset_index()
sns.barplot(data=incorrect_top5, x='Количество', y='Путь')
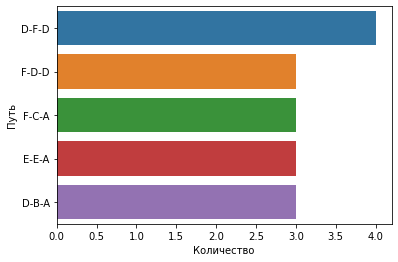
Из диаграммы видно, что из некорректных реализаций процесса наиболее часто встречается последовательность этапов D — F — D.
Таким образом, выполнив несколько несложных действий, можно получить значительно более точное представление о свойствах изучаемого процесса.
Исходный код Python-ноутбука приведен в репозитории github.com/mporuchikov/process_conformance_checking.