/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 10 мин.
Вопрос оценки качества работы систем распознавания речи возникает как перед разработчиками собственных решений, так и перед конечными пользователями. Насколько качественна система распознавания речи? Насколько она эффективная на разных типах данных?
И очень хочется использовать не просто субъективный подход, а использовать какие-то объективные и количественные параметры.
В моем случае стояла задача произвести транскрибацию большого количества телефонных разговоров. При этом варианты выбора возможных решений были ограничены. Фактически рассматривалось три варианта: библиотека Python VOSK и собственное решение, далее условно обозначенное как S2T, и SmartSpeech от SberDevices. Но цель моего исследования не сравнение инструментов как таковое, а показать общий подход к данной задаче.
Существует ряд общепринятых метрик для проведения такой оценки.
Первое с чем нужно определиться – по какому критерию будет производится оценка, т.е. что именно будет оцениваться: например, точность распознавания речи, скорость обработки, устойчивость к шуму в источнике данных.
Далее нужно определить некий показатель (метрику) определяющую конкретное свойство для выбранного критерия. Например, процент точно распознанных слов, время обработки фрагмента речи, максимальный уровень шума и т.п.
После чего необходимо создать валидационный датасет. Или несколько датасетов, сгруппированных по доменам (например, телефонные звонки, аудиокниги). Т.к. очевидно, что на разных типах данных системы распознавания речи могут давать очень разный результат. Аудиокниги записываются в студии на специальном оборудовании в идеальных условиях, читаемый текст соответствует литературной норме именно письменной речи, и текст читает профессиональный диктор. В то время как телефонные звонки содержат разговорную речь, неполные предложения, часто не законченные, сигнал содержит помехи, и полоса частот более узкая и т.д.
Часто системы распознавания речи имеют разные модели для разных типов исходных данных, в частности для телефонных разговоров.
Частота дискретизации аудио (8 или 16 kHz) также важна. Вообще она должна быть такой же, как родная частота модели распознающей системы. Модели для работы с телефонными звонками как правило используют 8 kHz, и это нужно учитывать.
Для стабильности результатов тестирования длительность таких датасетов должна быть порядка 2-3 часов аудио.
Текст для расчета метрик должен быть нормализован. Т.е. все тексты приводятся к нижнему регистру. А все цифры должны быть записаны в виде текста. Т.к., например, SmartSpeech записывает числа именно числами, а VOSK такого не умеет. Какие-то системы могут расставлять знаки препинания, другие нет. А использование буквы «ё» может быть неоднозначно.
В связи с чем и необходимо привести все тексты к единообразному виду. Нормализация вообще может быть произведена по-разному, можно и наоборот, скажем, приводить все числа к представлению в виде цифр, а не текста, тут нет какого-то единственного верного решения.
Метрики
Существует ряд общепринятых метрик для подобных задач. Наиболее распространенные метрики для оценки точности распознавания речи:
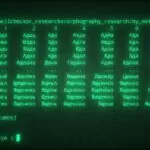
- Word Recognition Rate (WRR) — точность распознавания, которая определяется как процент правильно распознанных слов, и родственная ей, Word Error Rate (WER) — процент неправильно распознанных слов. Вычисляется на основе расстояния Левенштейна.
- Метрика WER представляет собой «стоимость» для преобразования одной строки (эталонной) во вторую (гипотеза, результат транскрибации) с наименьшим числом операций замены (S), удаления (D) и вставки (I) слов.
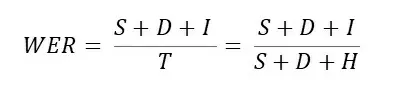
где S — количество операций замены слов,
I — количество операций вставки слов,
D — количество операций удаления слов,
T — количество слов в эталонной фразе,
H — количество верно распознанных слов.
Чем метрика WER ближе к нулю, тем выше точность распознавания.
Упрощенно метрику WER можно понимать, как количество ошибок в словах (это не совсем так). Т.е., например, WER = 50% — это половина слов распознана неверно, WER = 10% — каждое десятое слово распознано неверно.
Обращаю внимание, показатель WER может быть и больше 100%. Это может произойти за счет операций вставок. Для иллюстрации рассмотрим такой искусственный пример:
Эталон: «Я стразу отправила запрос в военкомат»
Гипотеза: «Я сразу отправила запрос в военкомат по месту регистрации». WER = 416%.
Применяется также: ошибка распознавания соответствий — Math Error Rate (MER) и показатель потери информации Word Information Lost (WIL).
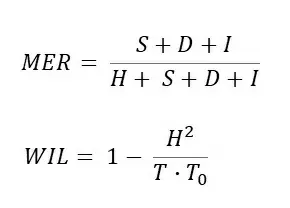
где T0 — количество слов в гипотезе распознавания.
- Метрика Character Error Rate (CER) вычисляется так же как WER, но не для слов, а для отдельных символов.
- Для оценки качества существуют так же другие менее распространенные метрики, учитывающие разные операции с разной стоимостью. Т.е., например, замена имеет меньший вес, чем вставка или удаление. Или учитывающие разные слова или буквы с разным весом (такой подход используется при оценке систем автоматизированного перевода).
- Для оценки скорости распознавания может быть использована метрика Real Time Factor (Коэффициент реального времени) – показатель отношения времени распознавания к длительности распознаваемого сигнала, также известного как Speed Factor (SF). Данный показатель можно рассчитать, используя формулу:
где Трасп – время распознавания сигнала, Т – его длительность. Коэффициент измеряется в долях от реального времени.
Для вычисления метрик существуют готовые решения.
Python библиотека JiWER. В её основе лежит библиотека Levenshtein для вычисления расстояния Левенштейна.
Или библиотека FastWER.
Не такое эффективное, как вышеуказанные библиотеки, но рабочее решение:
Исходный код:
import numpy as np
def levenshtein_distance(r, h):
rows = len(r)+1
cols = len(h)+1
distance = np.zeros((rows,cols),dtype = int)
for i in range(1, rows):
for k in range(1,cols):
distance[i][0] = i
distance[0][k] = k
for col in range(1, cols):
for row in range(1, rows):
if r[row-1] == h[col-1]:
cost = 0 # если в позиции [i,j] один и тот же символ, то стоимость = 0
else:
cost = 1
distance[row][col] = min(distance[row-1][col] + 1, # стоимость deletions
distance[row][col-1] + 1, # стоимость insertions
distance[row-1][col-1] + cost) # стоимость substitutions
return distance[row][col]
def wer(r, h):
return levenshtein_distance(r.split(), h.split()) / len(r.split()) * 100
def cer(r, h):
return levenshtein_distance(r, h) / len(r) * 100
Вообще, неверно было бы просто посчитать метрику WER для нескольких текстов и взять среднее арифметическое из их значений (тексты разной длины будут давать одинаковый вклад в ошибку). Можно попробовать рассчитать WER для всего корпуса текстов, объединив их в один, но тут есть препятствие — вычислительная сложность алгоритма O(n^2), и для больших текстов быстро растет. Т.е. если для текста из 10 слов потребуется порядка 100 операций, для текста из 100 слов 10000 операций, а для текста из 1000 слов уже порядка 1000000 операций.
Поэтому я использовал не только среднее значение метрики WER (CER), но и ее среднеквадратичное отклонение, и форму распределения метрики как случайной величины.
Итак, с теорией на этом закончу, перехожу к нашей задаче. Напомню, мне необходимо было транскрибировать большое количество звонков. И для этого сначала нужно было выбрать инструмент, который будет для этого использоваться.
Я сделал выборку для исследования из 90 звонков, общей длительностью 180 минут. Нужно отметить, что в случае с телефонными разговорами у меня нет 100% верной текстовой версии разговора, поэтому использовал ручную транскрибацию для получения эталонного текста.
Т.е. звонки были прослушаны и транскрибированы людьми вручную, а полученный таким образом текст использовался в качестве 100% верного эталонного текста при вычислении метрик.
Хотя это, конечно, дает смещенную оценку метрик WER (CER), так как люди тоже совершают ошибки при транскрибации (около 5% для русской речи). Но, так как в нашем случае все инструменты сравнивались между собой по одной и тоже методике и на одних и тех же данных, этим можно пренебречь.
Но, если сравнивать значения полученных метрик с результатами других исследований, то это нужно иметь ввиду.
Я в основном ориентировался на метрики CER и WER, как наиболее общепринятые, понятные интуитивно и простые для вычисления.
На графике ниже представлена ядерная оценка плотности распределения метрик WER и CER для данной выборки.
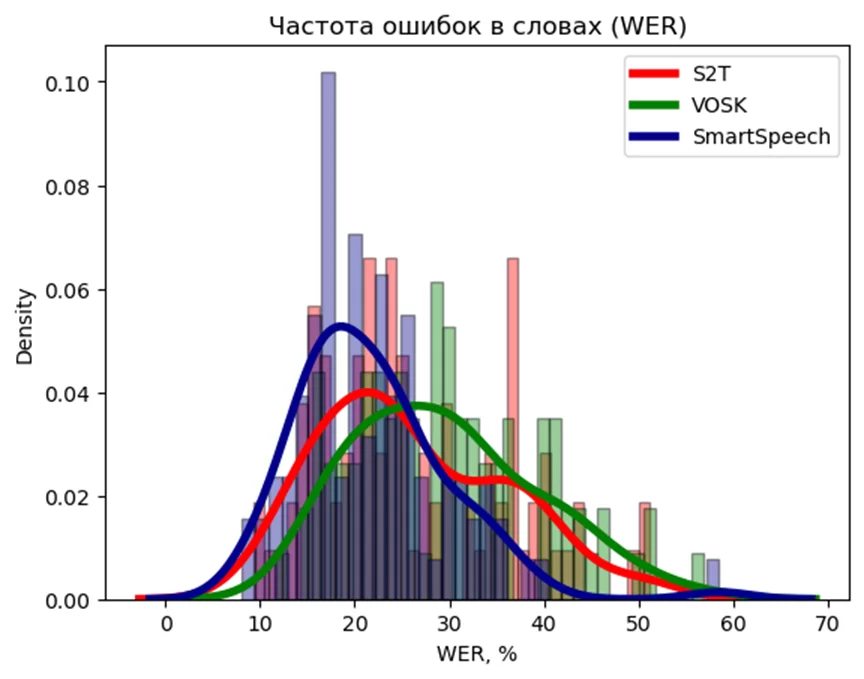
Средние значения: S2T = 22.6%, VOSK = 22.15, SmartSpeech=22.9
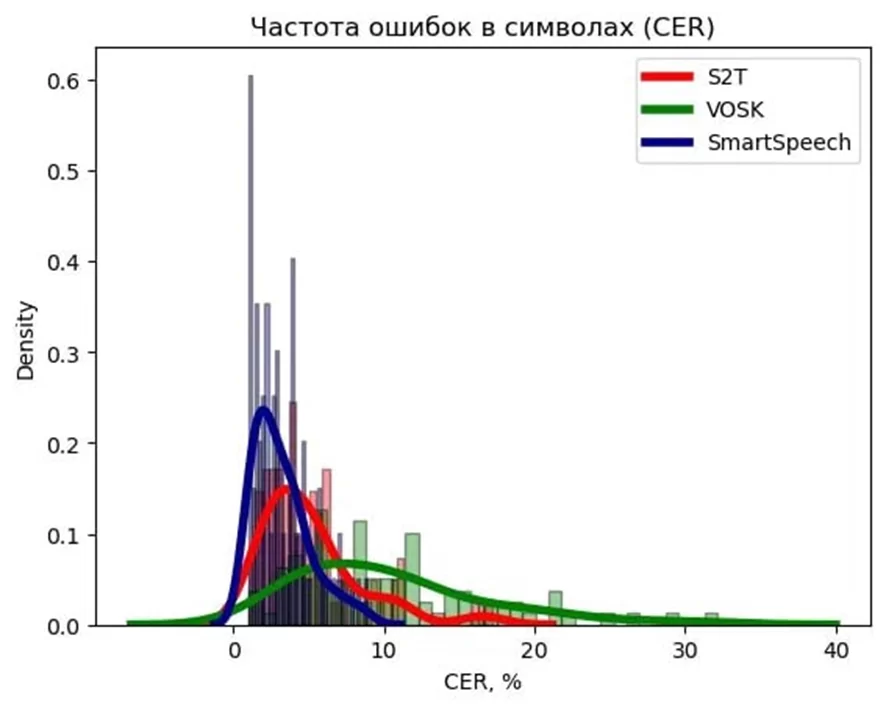
Средние значения: S2T = 7.2%, VOSK = 8.1, SmartSpeech=2.9
Чем левее находится пик на графике и уже разброс показателя — тем лучше. Видно, что при близких по значению средних показателях метрики разброс значений значительно отличается.
В моем случае наилучшие результаты продемонстрировал SmartSpeech. Библиотека VOSK и S2T значительно уступают, при этом VOSK оказался на последнем месте.
Некоторые критические замечания
WER – хороший и интуитивно понятный показатель качества распознавания речи для аналитических языков (таких как английский, испанский, итальянский), в которых морфология достаточно проста. Но для синтетических языков, которые имеют богатую морфологию словообразования (русский, турецкий, арабский т.д.), WER оказывается завышен и вообще является менее показательным. Связанно это с тем, что такие языки могут синтезировать достаточно длинные словоформы, состоящие из нескольких морфем, определяющие грамматические признаки; при этом конец словоформы в беглой речи произносить менее четко, что часто приводит к неопределенности.
Например:
Эталон: «Перезвоню через пол часа»
Гипотеза: «Перезвоним через пол часа»
WER: 25%, CER: 8.33%
Эталон: «Я могу поговорить с Ларисой Михайловной»
Гипотеза: «Я могу поговорить с Лариса Михайловной»
WER: 16.67%, CER: 5.13%
Собственно, метрика WER наиболее популярна, т.к. публикации на эту тему существуют в основном именно на английском языке.
Для синтетических языков (таких как русский) могут применяться другие метрики, такие как: ошибки распознавания символов (CER), фонем, слогов, морфем. Именно поэтому я больше ориентируюсь на метрику CER, а не более общепринятую WER.
Но есть более интересные подходы. В частности, для русского языка с учетом его структуры хорошей метрикой является флективная ошибка распознавания слов (IWER – Inflectional Word Error Rate), которая определяется следующим образом:
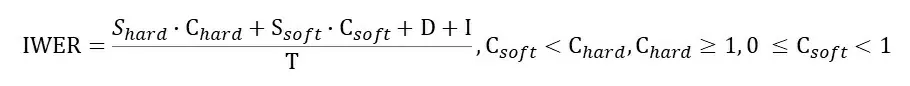
Здесь вес Сhard приписывается всем неверным заменам слов, которые приводят к замене лексемы слова (являются грубыми ошибками), а Shard количество таких грубых ошибок. Csoft это вес негрубых ошибок, т.е. где было неверно распознано окончание словоформы, но основа при этом была распознана верно; Ssoft — количество негрубых ошибок.
Такой подход лучше, но тоже не идеален. Например, сотрудник в телефонном разговоре говорит: «Я могу приступать», а фраза распознается как «Я могу преступать».
Слова отличаются одной буквой, и грамматически верны оба случая, но они несут разный смысл. «Приступать» — означает начало действия, в то время как «преступать» — может означать нарушение установленных норм, закона. С другой стороны, у человека скорее всего вообще не будет никакой сложности верно интерпретировать слово из контекста.
Тем не менее и метрика WER и IWER его «заминусуют» так же как, например, слово «самовар». Т.е. для гипотезы «Я могу преступать» WER = 33.3% и для «Я могу самовар» тоже WER = 33.3%. Это ошибка в корне слова, так что будет учтена с максимальным весом в случае использования IWER.
В данном материале мною были рассмотрены основные и альтернативные метрики качества применяемые для оценки работы систем автоматизированного распознавания речи. Ошибки в распознавании слов, символов; их специфика с учетом особенностей русского языка. Так же рассмотрен процесс подготовки данных для оценки качества работы таких систем.