/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
NLP одна из многих задач решаемых при помощи ML. Одним из разделов NLP является NER (Named Entity Recognition) – распознавание именованных сущностей. На сегодняшний день существует ряд инструментов, которые способны обеспечить хорошую точность распознавания различных сущностей, однако, когда дело касается специфических задач, зачастую может потребоваться дополнительная настройка.
Рабочей задачей является создать инструмент автоматизированного поиска объявлений, размещенных в интернете. На вход подается список адресов, записанных по похожей (но неодинаковой!) форме, а на выходе необходимо получить ряд ссылок на найденную информацию.
Задача делится на четыре части:
- Обработка входных данных;
- Создание запроса;
- Передача запроса поисковой системе;
- Получение и обработка результатов поиска.
Именно второму пункту задачи будет уделено внимание в данной статье. При автоматизированном поиске через поисковую систему, качество результата напрямую зависит от качества запроса. Зачастую по введённому поисковому запросу отображаются миллионы результатов, практически не относящиеся к тому, что предполагалось отыскать.
Для создания хорошего запроса можно воспользоваться операторами. Они позволяют существенно уточнить, что и где нужно искать: например, запрос содержащий site:2gis.ru позволит получить результаты только с указанного сайта, а если часть запроса “заключена в кавычки”, то среди найденных результатов будут только те, которые содержат конкретную фразу, заключённую в кавычки.
Эмпирическим методом было определено, что наиболее интересные результаты поиска удается получить при помощи запросов вида:
site:2gis.ru cитуативные_слова “ населенный_пункт улица номер_дома” –слово_исключение Данный запрос состоит из четырёх частей:
- Слова, которые помогают искать результаты на профильных сайтах;
- Необязательные слова (могут встретиться или нет);
- Часть запроса содержащая конкретный адрес;
- Слова, которых в результатах быть не должно.
Таким образом основной задачей является преобразование строки, передаваемой на вход к определенному виду.
Формирование запроса
На входе в данном этапе подаются строки примерно такого вида:
Россия, Бурятия, Баргузинский р-н, Улан-Удэ, 20 лет октября ул, д. 7, кв. 2
Желаемый результат на выходе, должен представлять собой информацию корректно распределённую по столбцам «населённый пункт», «улица», «номер дома».
| Субъект | Нас. пункт | Улица | № дома |
| Бурятия | Улан-Удэ | 20 лет октября | 7 |
Из данных, упорядоченных таким образом, легко создавать и изменять поисковые запросы. Процесс вычленения, подобных составляющих из текста, носит название «поиск именованных сущностей» и является одной из задач, решаемых с помощью машинного обучения.
Для решения данной задачи я решил воспользоваться возможностями проекта Natasha, который представляет из себя набор инструментов для решения задач NLP. В сравнении с аналогичными проектами, такими как Deeppavlov, Stanza, Pullenti работа с адресами представляется наиболее удобной и эффективной именно с Natasha. В основе ner Natasha лежит Yargy парсер, работающий по принципу правил и словарей.
В чистом виде, на представленных ранее данных Natasha отрабатывает следующим образом:
Из:

Получается:
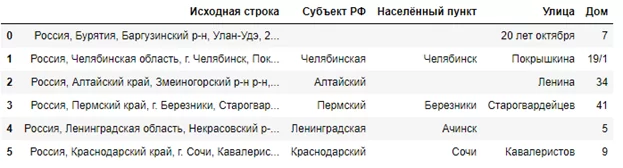
Бурятия почему-то не определяется, как республика, Змеиногорск и Улан-Удэ – как города, а 1 Отличный мкр – не распознается как улица
Для того, чтобы разобраться почему, нужно покопаться в коде. Оказывается, все республики уже занесены в качестве словаря, соответственно они должны распознаваться.

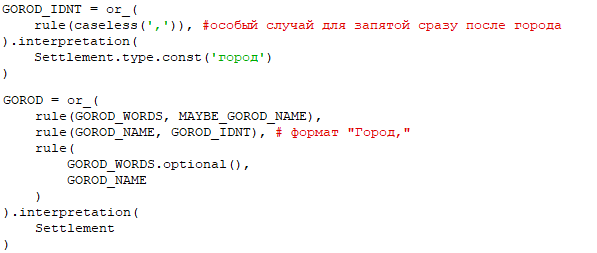
Однако ниже по коду, можно заметить, что при конечном поиске, правило предусматривает, что название республики может быть распознано, только в ситуациях, когда оно сопровождается словом республика, сокращением от него или является аббревиатурой (рис. ниже)

Для исправления этой проблемы добавим в код возможность присутствия названия республики, сопровождаемого запятой:

а также шаблон, в соответствии с которым, запятая может быть после наименования:

Теперь необязательно иметь сокращение респ. рядом с названием республики, чтобы её опознать.
Та же ситуация с одинокими названиями городов: в словаре уже перечислены основные города России, однако без г. Рядом распознаны они не будут:
Такая конструкция позволит распознавать как города, только вписанные в словарь слова и никакой лишней информации в выборку не попадёт.
С распознанием микрорайона – другая ситуация. Yargy парсер изначально не содержит правила позволяющего распознать микрорайон, а значит это правило нужно дописать самостоятельно. В качестве примера было использовано другое, уже имеющееся в коде парсера правило. За основу было взято правило для бульвара и по аналогии написано для микрорайона.
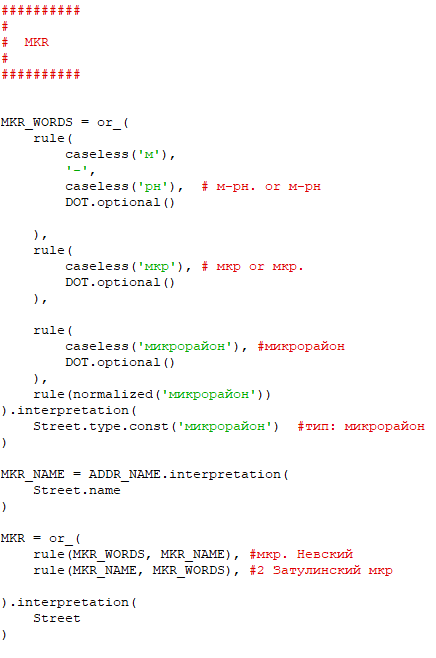
Также нужно не забыть добавить новое правило в список правил в конце скрипта

Аналогичным образом можно редактировать имеющиеся или добавлять новые правила, для улучшения работы парсера по адресам. Для тестовой выборки перечисленных дополнений достаточно для того, чтобы получить результат аналогичный ручному вводу.
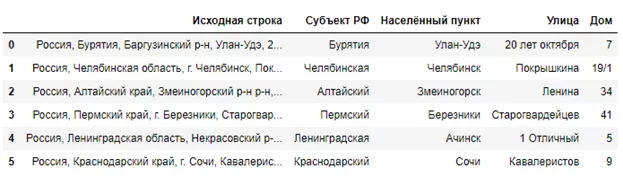
Результат
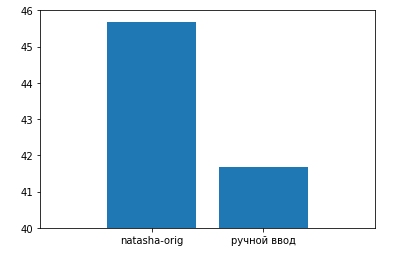
Для проверки эффективности и целесообразности внедрения такого улучшения, сравним среднее расстояние Левенштейна для тестовой выборки обработанных вручную и обработанной с помощью стандартной Natasha, а также для всех адресов, обработанных с помощью стандартной Natasha и Natasha, дополненной ситуативными правилами.
На примере тестовой выборки можно проследить, что среднее расстояние Левенштейна между необработанной и обработанной строкой одного и того же адреса, при ручном вводе, оказывается меньше. Это является индикатором того, что в строках, созданных с помощью Natasha не хватает значений и расстояние оказывается больше.
Таким же образом можно сравнить эффект от внедрения правил на полной выборке.
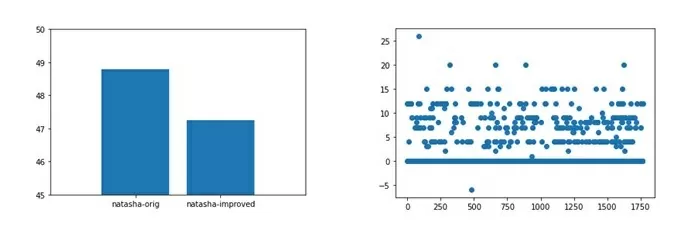
(б) – разница в расстояниях Левенштейна для одних и тех же адресов в полной выборке.
Вывод:
В результате дополнения библиотеки Natasha всего лишь тремя дополнительными условиями, удалось улучшить 17% общего числа поисковых запросов. Подобный подход позволяет стабильно улучшать результат работы до требуемого значения, не требует больших затрат времени и является достаточно простым для понимания.